







之前写了一个拉取nba球员的脚本,是针对hupu网站上的数据进行拉取。由于水平一般,代码写的简单粗暴
hupu球队\球员信息的链接
可以看到球员球队信息。爬出所有球队的链接
teamList = []
response = urllib2.urlopen("http://g.hupu.com/nba/players/")
html = response.read()
def getTeams():
Items = re.findall('<span class="team_name"><a href=".*?</a></span>',html,re.S)
for item in Items:
link = item.replace('<span class="team_name"><a href="','')
team = re.findall('">.*?</a></span>',link,re.S)[0]
link = 'http://g.hupu.com/'+link.replace(team,'')
team = team.replace('">','').replace('</a></span>','')
teamList.append(teamLink(team,link))
然后再爬出每个球员的详细页面
for team in teamList:
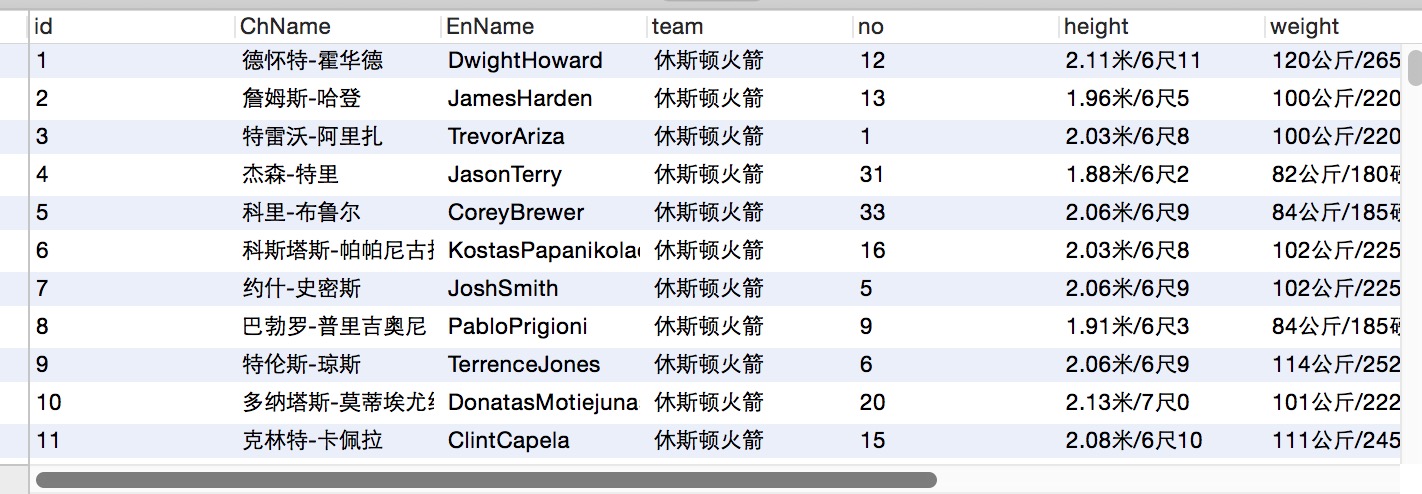
getPlayers(team)并且获得数据,存入数据库
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









