






 呵呵,在这里小渣还是先说明一点哦,我们大家都是在不断努力嘛,这个博客是自己学习自己动手写网络爬虫的心得,也难免有错,大家一起谈讨加油哦,么么哒~~~
呵呵,在这里小渣还是先说明一点哦,我们大家都是在不断努力嘛,这个博客是自己学习自己动手写网络爬虫的心得,也难免有错,大家一起谈讨加油哦,么么哒~~~
宽度优先遍历互联网-----实现思想  在上一节中,我们说了宽度优先遍历的思想基础,把这个算法放在互联网爬虫项目中,怎么实现呢?
在上一节中,我们说了宽度优先遍历的思想基础,把这个算法放在互联网爬虫项目中,怎么实现呢?
实际爬虫项目是从一系列大的种子链接开始的。所谓的种子链接,就像是宽度优先遍历的种子节点。简而言之:实际的爬虫项目种子链接可以有多个,而宽度优先遍历中的种子节点只有一个。比如我们可以指定www.hao123.com。
先说:爬虫中的子节点与终端节点
每一个HtmL页面 或者其他文件(word,excel,pdf),在这些文件中,只有HTML页面有相应的子节点,这些子节点就是HTMl页面上对应的超链接 。如hao123网页中,一些比如淘宝啊,优酷啊,京东啊,这些便是hao123中的子节点。这些子节点本身又是一个链接,对于非HTML文档,比如Excel文件,不能从中提取超链接,因此,可以看作是图的终端节点,就好像是上节中的BCDIG。
继续:爬虫过程
这是我们一般所使用的hao123。我们就举这个例子吧。
整个宽度优先爬虫的过程:从一系列的种子节点开始,(简单理解,可以说从一个开始,与上一节相呼应)把这些网页的的子节点(也就是超链接)提取出来,放入队列中依次进行抓取,被处理过的链接需要放入一张表(Visited,也就是标记已经访问了)。每次新处理一个链接之前,需要朝看这个链是否在visited中,如果在呢,就证明已经处理了,跳过,否则下一步处理。
图解过程如下:
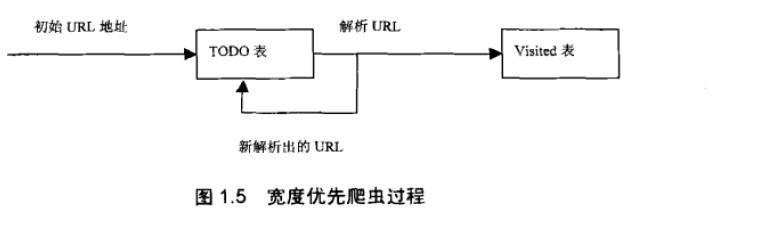
我们耐性看一下这个图:
首先 初始化的URL地址是爬虫系统中提供的种子URL(一般在系统的配置文件中指定 )。当解析这些种子URL所表示的网页时候,会产生新的URL(比如从网页中的<a href="http://www.baidu.com">提取http://www.baidu.com这个链接)。然后,我们要做:
1.把解析出来的链接和visited表中的链接进行比较,如果visited表中不存在此链接,表示没有访问过。
2.把链接放入TODO表
3.处理完毕后,在此从TODO表中取一条链接,直接放入Visited表中。
4.针对这个链接所表示的网页,继续上述过程,如此循环。
宽度优先遍历说是爬虫中使用最广泛的一种爬虫策略,为什么?
原因:
1重要的网页往往离种子比较近,例如我们打开新闻网站,往往是最新的和热门的,越后面重要性越来越低。
2万维网的实际深度最多能达到17层,(具体的理论验证我也不是很懂)但是达到某个网页总存在一条很短的路径,而宽度优先遍历会以最快速度到达。
3,宽度优先有利于多爬虫的合作抓取,多爬虫合作通常先抓取站内链接,抓取的封闭性很强。需要实际编码才会深刻体会。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









