






目录
2.1.2 初始化数据段 Initialized data segment
2.1.3 未初始化的数据段 Uninitialized data segment (bss)
1. 前言
最近和师兄正在打集创赛,终于在Windows下用Visual Studio成功完成了符合比赛要求的C语言程序编写。接下来的任务是将程序迁移到Ubuntu系统上,并利用make工具进行编译。不错所料的是,原本在Windows上使用VS顺利运行的C语言程序(实际上原因并不是系统问题,见后文),在迁移到Ubuntu后果然出现了一些问题。
可以看到我想使用程序进行编码,这时出现了 Segmentation fault ,搜索了一下主要都是内存错误、指针管理错误等。
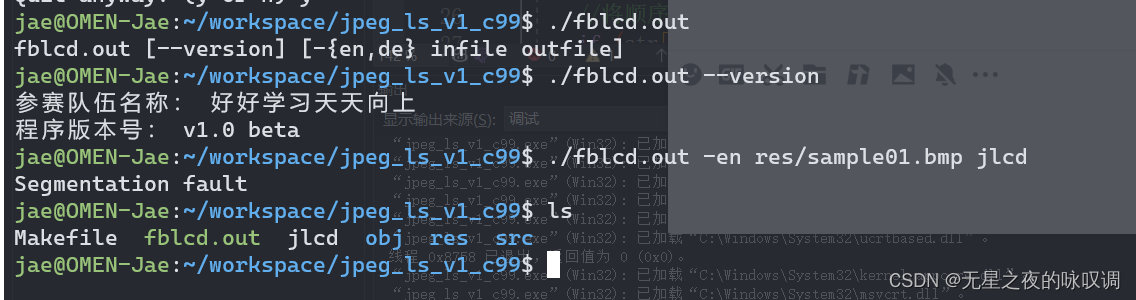
使用gdb进行调试后发现是运行到"encoder_main.c"文件的163行出错。
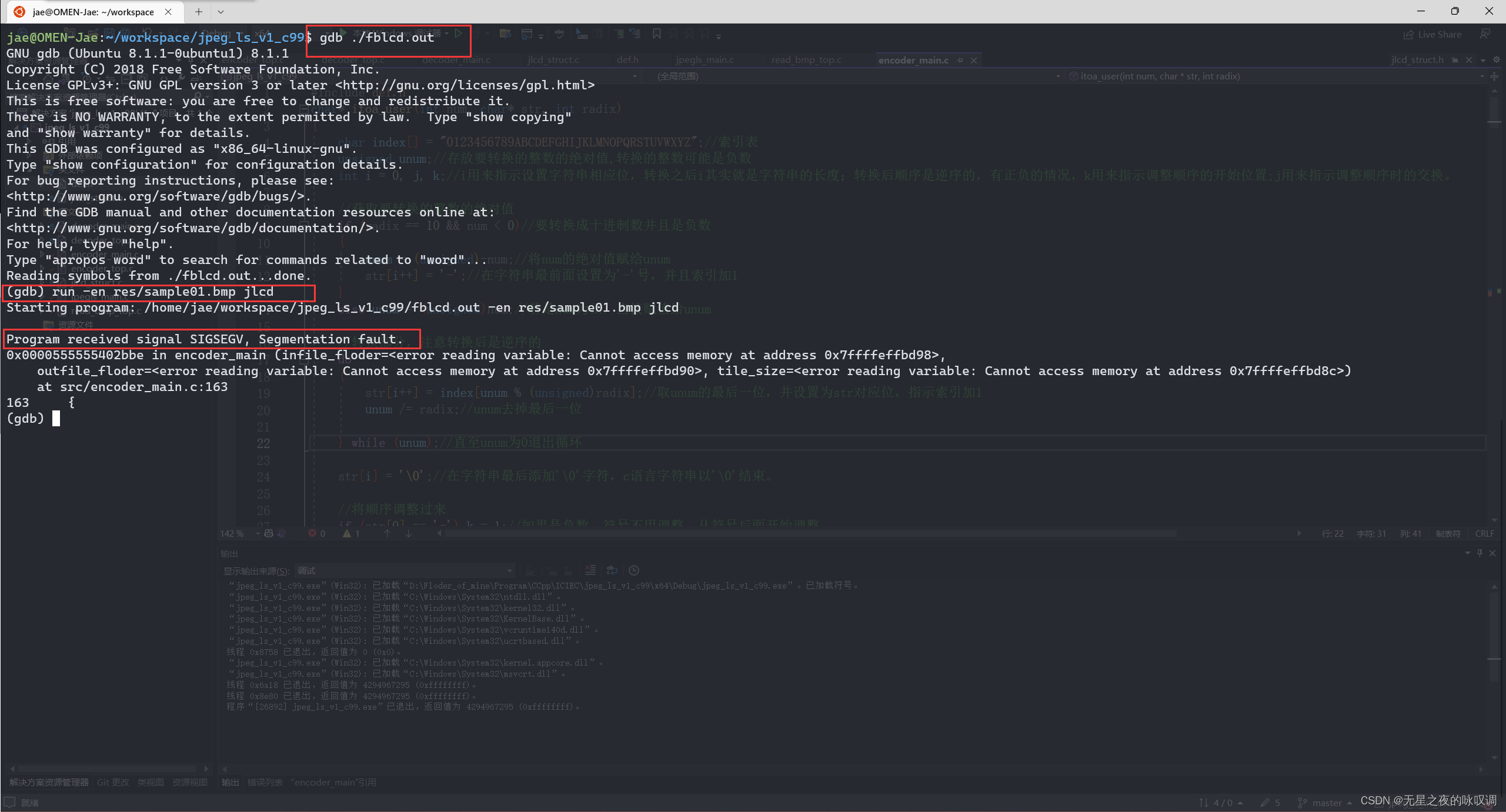
才疏学浅,我没有看出来任何错误...在请教我同学后才知道原来是栈溢出的问题。
165-168行定义了4个10M的数组,这已经超出了 Linux GCC 默认的 8M栈大小。
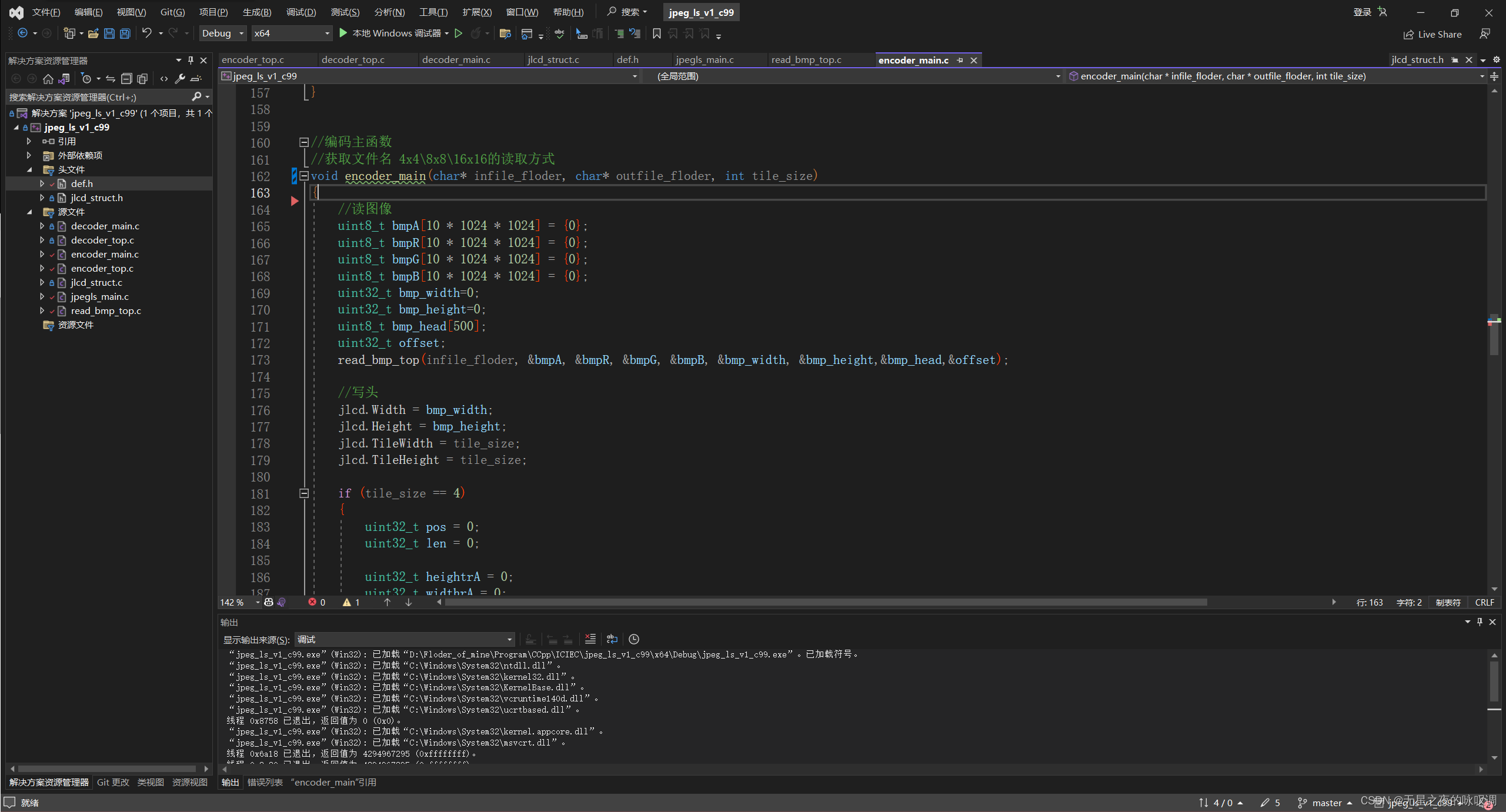
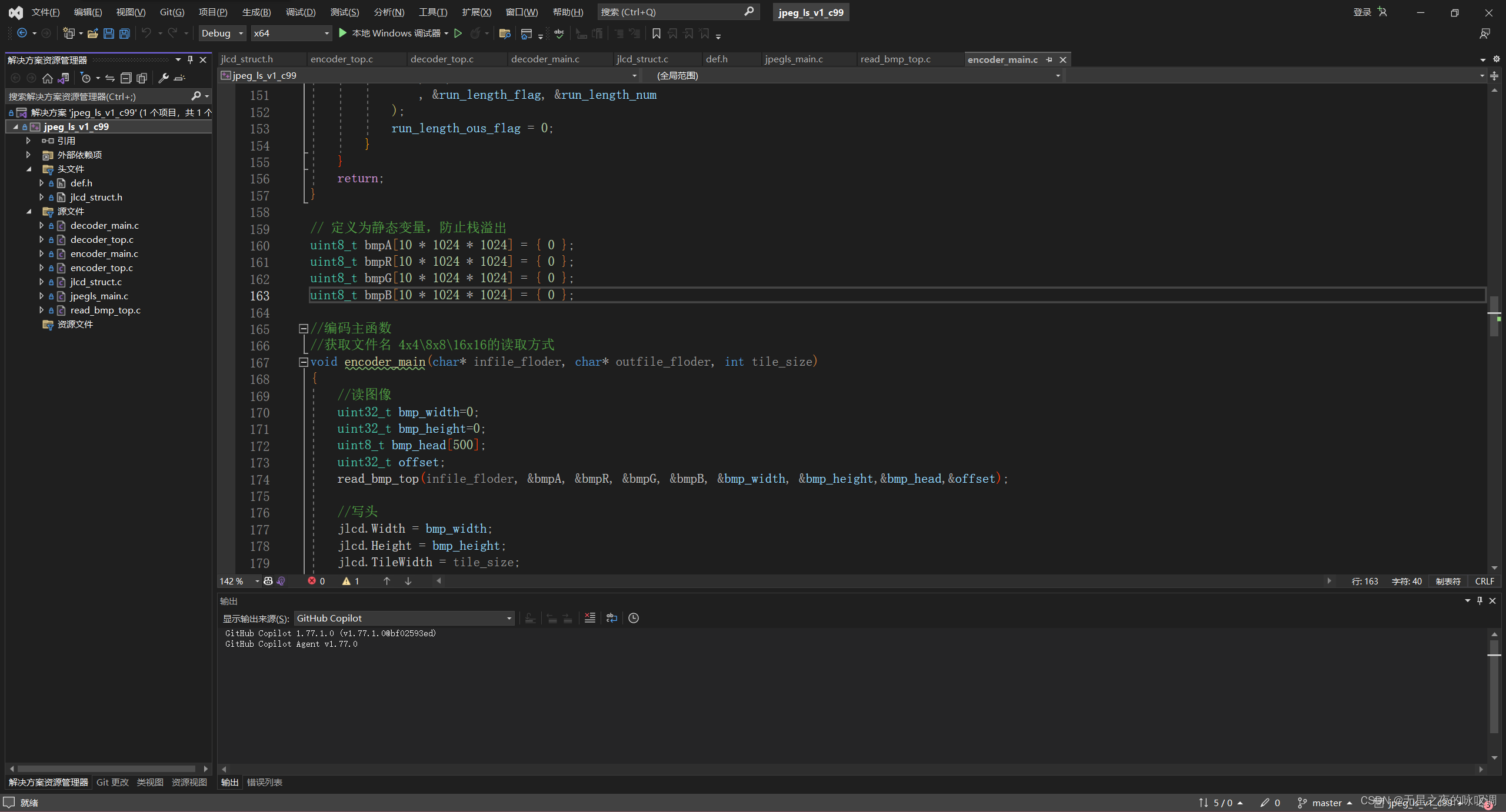
一种改正的方法则是把165-168行定义了4个10M的数组移动到函数外,使其成为静态变量,从而占用的静态变量区的空间。
本文主要参考以下文章,对这次遇到的问题进行总结学习。
(C语言内存九)Linux下C语言程序的内存布局(内存模型)
(C语言内存十二)栈(Stack)是什么?栈溢出又是怎么回事?
www.geeksforgeeks.org | Memory Layout of C Programs
2. C语言程序的内存模型
说明:以下 未做特殊说明的运行环境均为Ubuntu18.04.5、64位操作系统、使用gcc编译器、C语言程序遵循C99标准。
2.1 内存模型
一个典型的C程序内存表示由以下部分组成:
- 程序代码段 Text segment
- 初始化数据段 Initialized data segment
- 未初始化的数据段 Uninitialized data segment (bss)
- 堆 Heap
- 栈 Stack
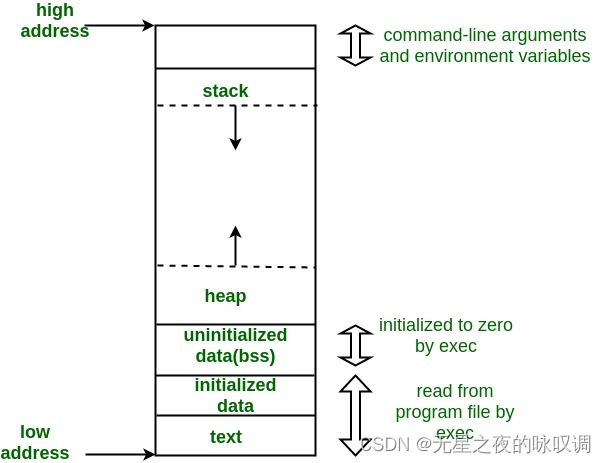
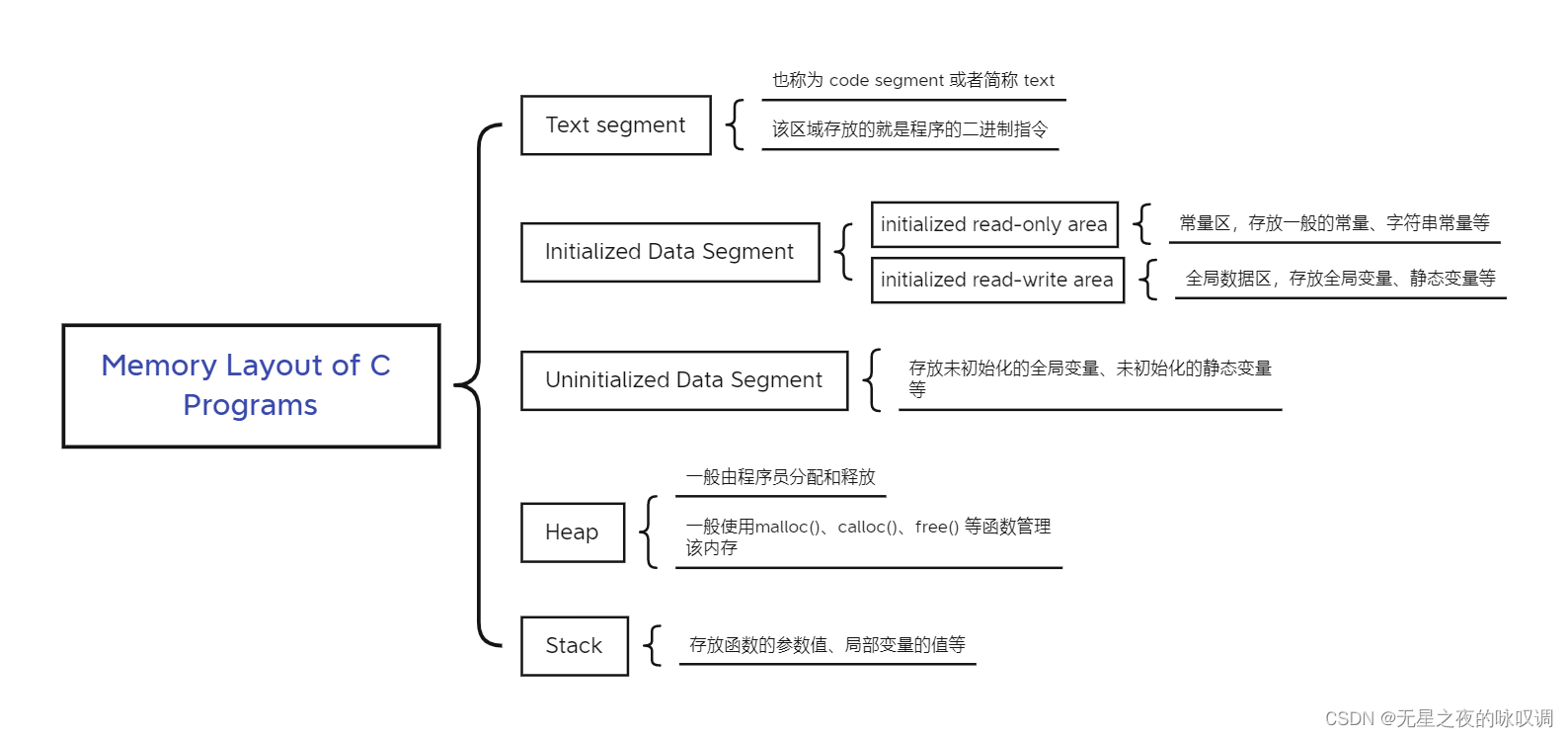
接下来详细了解一下这5个组成
2.1.1 程序代码段 Text segment
Text segment称为 code segment 或者简称 text。在运行一个程序时,操作系统首先会将这个程序从硬盘加载到内存中,程序的可执行的二进制指令存放的区域就是程序代码段。
2.1.2 初始化数据段 Initialized data segment
初始化数据段,通常简称为数据段(Data Segment)。数据段是程序虚拟地址空间的一部分,其中包含由程序员初始化的全局变量和静态变量。
该段又可以分为初始化只读区(initialized read-only area)也称为常量区和初始化读写区(initialized read-write area)也称为全局数据区。
举个例子
例如,在C语言中由char s[] = "hello world "定义的全局字符串和main之外(即全局)的int debug=1这样的C语句将被存储在初始化读写区。
而像 const char* string = "hello world" 这样的全局C语句会使字符串字面意思 "hello world "存储在初始化的只读区域,而字符指针变量string存储在初始化的读写区域。
例如:静态int i = 10将被存储在数据段中,全局int i = 10也将被存储在数据段中。
2.1.3 未初始化的数据段 Uninitialized data segment (bss)
未初始化的数据段通常称为bss,bss这个名称来自于一个古老的汇编运算符“block started by symbol”。在程序开始执行之前,该段中的数据由内核初始化为0,未初始化的数据从数据段的末尾开始。
该段包含所有初始化为零或在源代码中没有显式初始化的全局变量和静态变量。
举个例子
例如,声明为 static int i 的变量将包含在 BSS 段中。
例如,声明为 int j 的全局变量将包含在 BSS 段中。
2.1.4 堆 Heap
堆是通常发生动态内存分配的段。
堆区域从 BSS 段的末尾开始,地址由低到高增长。
堆区由malloc()、realloc()和free()管理,若程序员申请堆区内存后不释放,程序运行结束时堆区内存由操作系统回收。
Heap 区域由进程中的所有共享库和动态加载的模块共享。
2.1.5 栈 Stack
传统上,栈与堆相邻,并以相反的方向增长;当栈指针与堆指针相遇时,可用内存被耗尽。(有了现代的大地址空间和虚拟内存技术,它们几乎可以被放置在任何地方,但它们仍然通常以相反的方向增长)。
栈是储存自动变量的地方,同时每次调用函数时的相关信息也存在栈中。每次函数被调用时,返回的地址和关于调用者环境的某些信息,如一些机器的寄存器,都被保存在栈中。然后,新调用的函数在栈上为其自动变量分配空间。这就是C语言中递归函数的工作方式。每次递归函数调用自己时,都会使用一个新的栈帧(stack frame),所以一组函数中的变量不会干扰的另一个函数的变量。
通俗来讲,栈存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈。
2.2 内存模型的例子
#include <stdio.h>
char* str1 = "cyberbrain.top"; // 字符串在常量区,str1在全局数据区
int global; // 未初始化的变量在bss
int year = 2023; // 初始化的变量在data segment
int main(){
static int local; // 未初始化的变量在bss
static int people = 6000; // 初始化的变量在data segment
int k; // 栈区
char str2[20] = "cyberbrain.top"; // str2和字符串常量都在栈区
char* str3 = "cyberbrain.top"; // str3在栈区,字符串在常量区
printf("str1:%#X\n&global:%#X\n&year:%#X\n", str1, &global, &year);
printf("&local:%#X\n&people:%#X\n", &local, &people);
printf("&k:%#X\nstr2:%#X\nstr3:%#X\n", &k, str2, str3);
printf("&str3:%#X\n", &str3);
return 0;
}
代码运行效果如下:
| str1: | 0XC4400838 |
| &global: | 0XC4601028 |
| &year: | 0XC4601010 |
| &local: | 0XC4601024 |
| &people: | 0XC4601014 |
| &k: | 0X87B5E194 |
| str2: | 0X87B5E1A0 |
| str3: | 0XC4400838 |
| &str3: | 0X87B5E198 |
可以看到str1和str3这两个指针指向的都是同一个地址为0XC4400838的区域,也就是"cyberbrain.top"这个字符串所在的常量区,也就是在数据段中。而str2虽然内容相同,但是它是储存在栈区。
同理可以看到&k、str2、&str3均为0X87B5Exxx,表面他们在内存空间上很接近,实际上都存在栈区。
2.3 栈大小与栈溢出
栈空间是有限的,对于一个程序的每一个线程来说,它能够使用的栈空间在编译时就已经注定了,如果该线程使用的栈内存超过最大值,就会发生栈溢出(Stack Overflow)错误。
栈内存的大小和编译器有关,编译器会为栈内存指定一个最大值,在 VC/VS 下,默认是 1M,在 C-Free 下,默认是 2M,在 Linux GCC 下,默认是 8M。
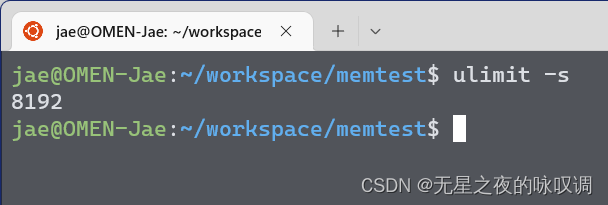
Linux系统下使用 ulimit -s 命令可以查看linux的默认栈空间大小。
3 解决方案
3.1 修改编译器参数
在VS中可以使用在项目的属性页,修改编译器的参数,使其编译的程序能够使用能大的栈空间。
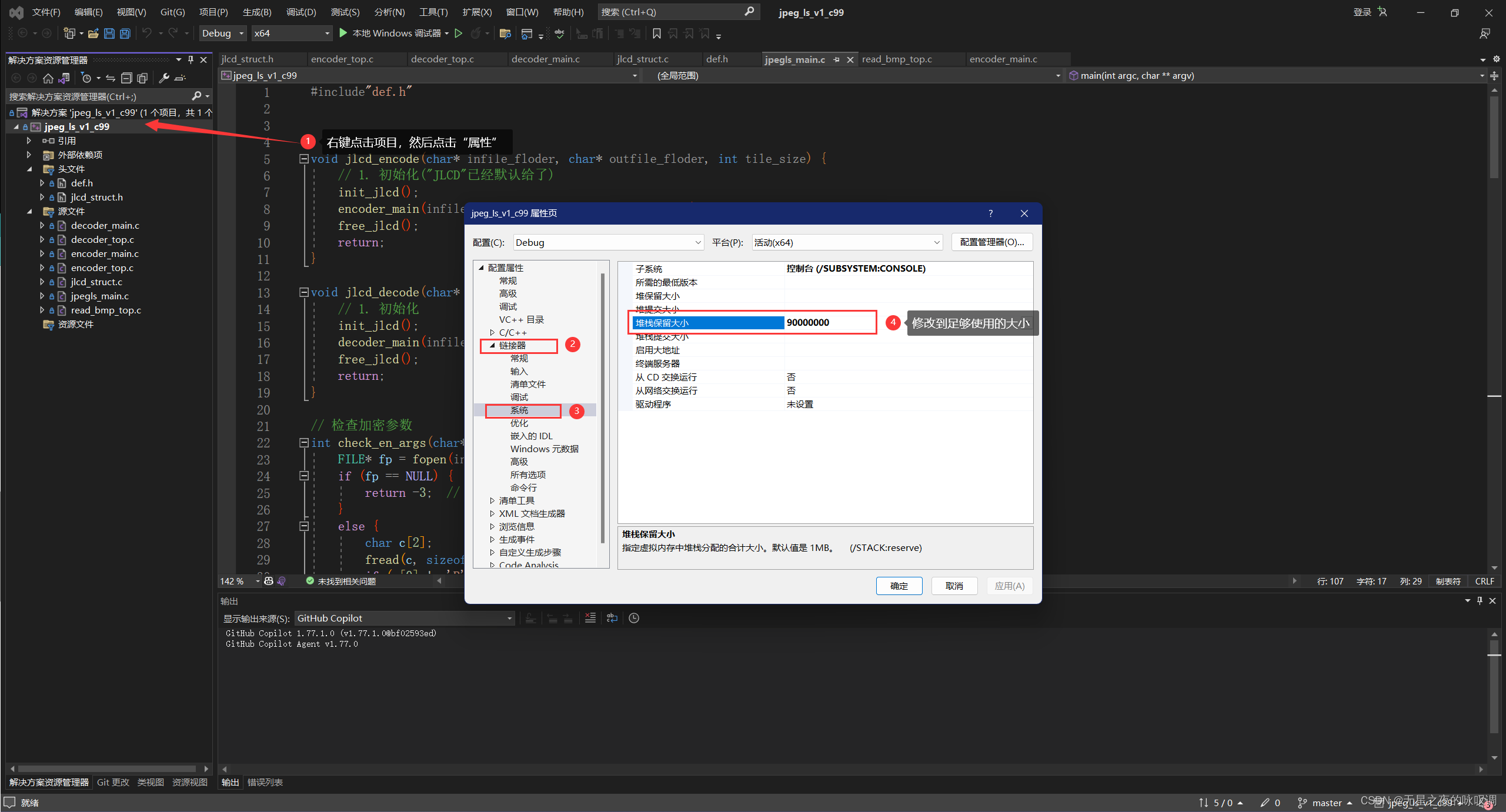
但是关于使用gcc修改这参数的方法暂时没有找到。
3.2 修改程序
既然默认的栈空间只有1M~8M,这样设置肯定是有他的道理的。更简单的方法是将那多达40M的数组放到Data segment。如下图,放到函数外成为全局变量,这样就不会占用栈空间。
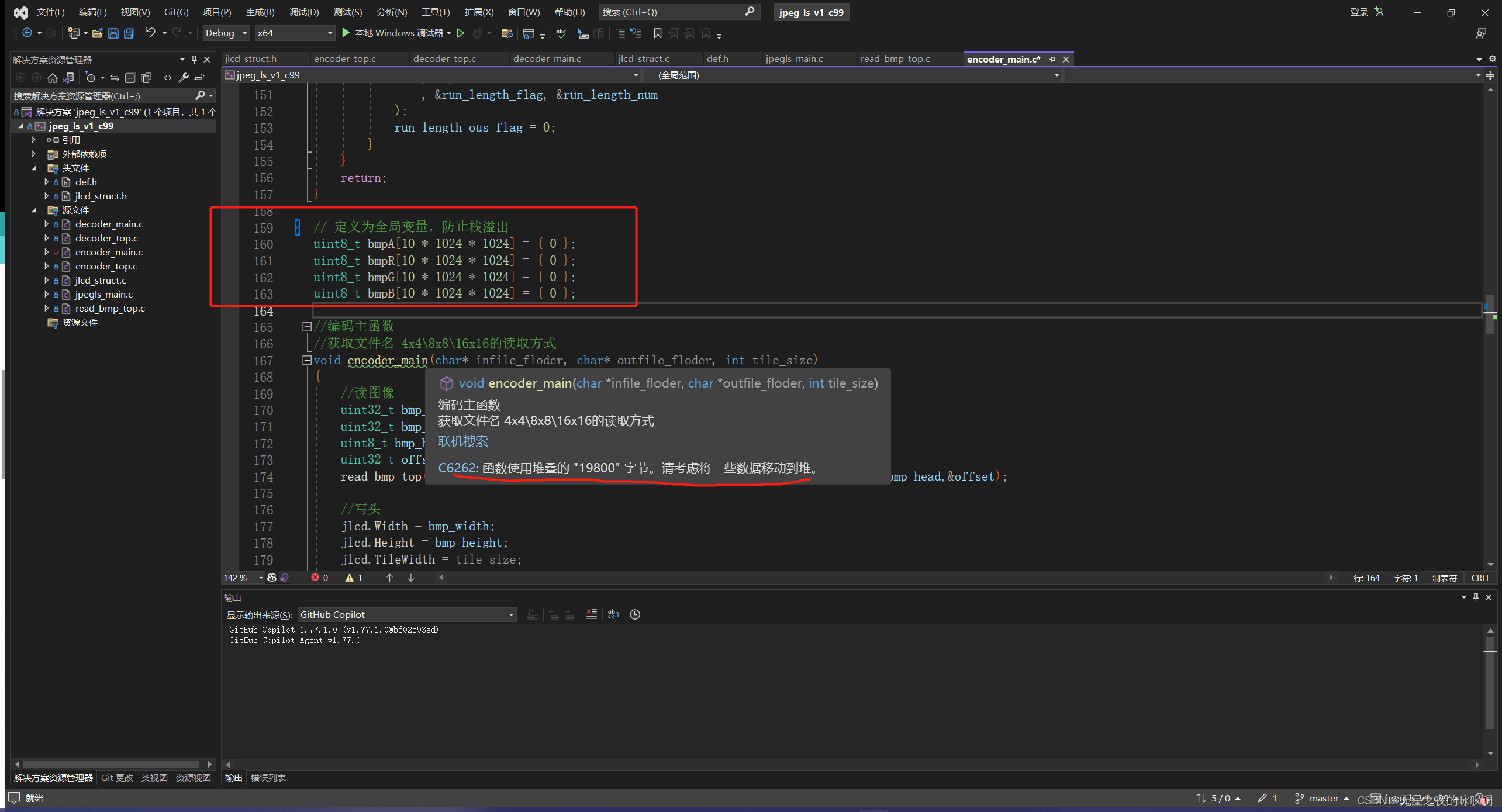
VS也贴心的提醒了我 “C6262:函数使用堆叠的“19800”字节。请考虑将一些数据移动到堆”,之前这个数更大呢,不了解内存模型和栈空间的限制于是就忽略了这个警告。















 1866
1866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









