







PC2/PC3上部署Hadoop
1、在PC2,PC3部署hadoop,Hadoop+flume用来收集日志.
1)/data/hadoop/下解压文件。
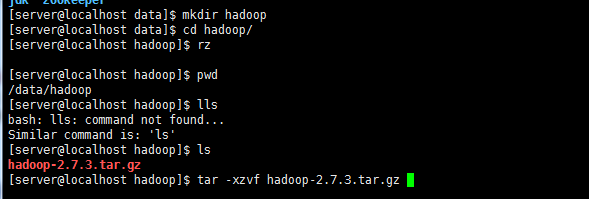
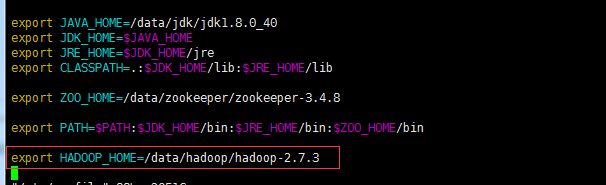
2)在 /etc/profile 后面配置 HADOOP_HOME 变量,为 flume 启动添加 hadoop classpath
export HADOOP_HOME=/data/hadoop/hadoop-2.7.3

3)修改 ${HADOOP_HOME}/etc/hadoop/core-site.xml 配置文件
<configuration>
<property>
<name>fs.defaultFS</name> <!-- 配置NN节点地址和端口号 -->
<value>hdfs://192.168.47.133:8020</value>
</property>
<property>
<name>io.file.buffer.size</name> <!-- 用作序列化文件处理时读写buffer的大小 -->
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name> <!-- hadoop临时目录用来存放nn临时文件,该目录必须预先手工创建不能删除 -->
<value>file:/data/hadoop/hadoop-2.7.3/data/tmp</value>
</property>
<property>
<name>fs.hdfs.impl</name> <!-- 针对hdfs的文件系统实现 -->
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
<property>
<name>fs.file.impl</name> <!-- 针对file的文件系统实现 -->
<value>org.apache.hadoop.fs.LocalFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
</configuration>

这里PC2/PC3的配置一样,另一台作为灾备存在;还有存放临时文件的data目录必须手动创建
4)修改 ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml配置文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name> <!-- NN所使用的元数据保存路径 -->
<value>file:/data/hadoop/hadoop-2.7.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> <!-- 真正的datanode数据保存路径 -->
<value>file:/data/hadoop/hadoop-2.7.3/data/datanode</value>
</property>
<property>
<name>dfs.replication></name>
<value>1</value><!-- 灾备数 -->
</property>
</configuration>

这里需要手动创建data目录以及对应的namenode、datanode目录,file对应的目录名必须存在
5)修改 ${HADOOP_HOME}/etc/hadoop/yarn-site.xml 配置文件
<configuration>
<property>
<name>yarn.resourcemanager.address</name><!--ResourceManager 对客户端暴露的地址。-->
<value>192.168.47.133:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name><!--ResourceManager 对ApplicationMaster暴露的访问地址-->
<value>192.168.47.133:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name><!--esourceManager 对NodeManager暴露的地址-->
<value>192.168.47.133:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name><!--ResourceManager 对管理员暴露的访问地址-->
<value>192.168.47.133:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name><!--对外web ui地址-->
<value>192.168.47.133:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name><!--NodeManager上运行的附属服务-->
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><!--跟aux一起才能运行-->
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
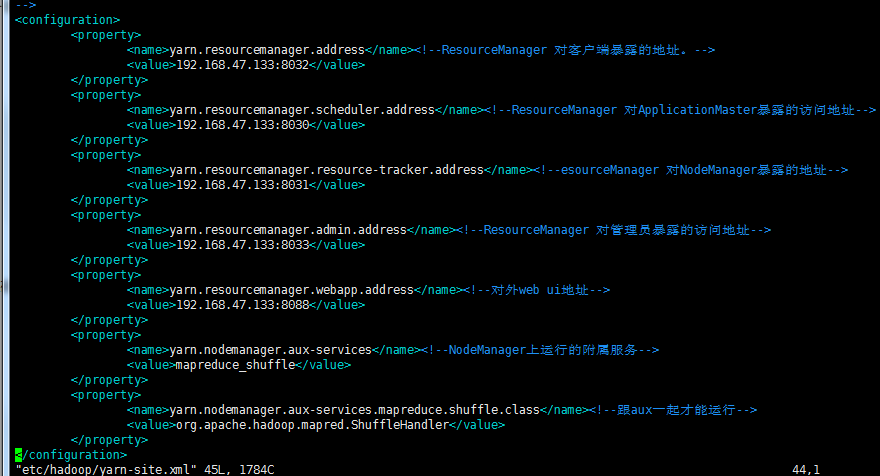
这里PC2/PC3的配置一样,另一台作为灾备存在
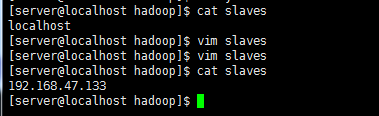
6)修改 ${HADOOP_HOME}/etc/hadoop/slaves 配置文件
修改localhost为配置文件中对应的主PC的IP,这里主配置IP为PC3,两台PC都是同一个配置
7)修改 ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh 文件,设置JAVA_HOME路径


8)启动前先格式化 namenode(第一次配置的时候格式化就OK了)
${HADOOP_HOME}/bin/hdfs namenode -format
启动有错误的话会直接提示,根据错误提示进行修改。
我这里hdfs-site.xml中,配置文件name属性结尾的时候少了一个结束符号

没有错误则表示format成功
9)启动 HDFS,${HADOOP_HOME}/sbin/start-dfs.sh
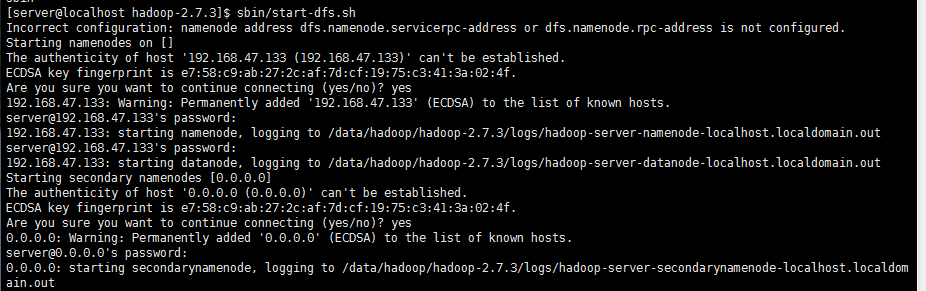
启动之后,输入jps服务没有启动起来,我检查发现配置文件有空格导致,修改后重启,小细节要多注意。
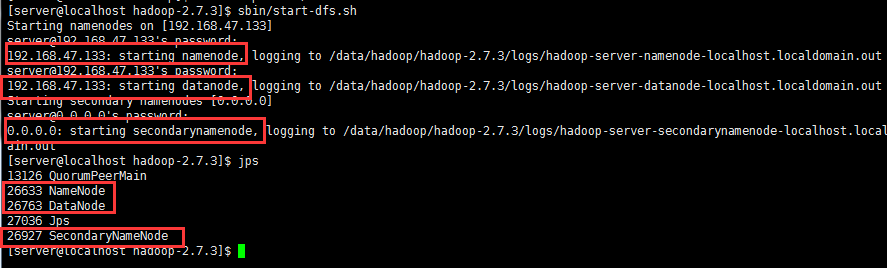
启动成功后,输入jps,主服务器上会有这三个node服务
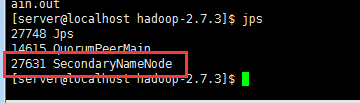
follow容灾服务,启动完成后只会有一个node















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









