







itchat是一个微信的python包,原理是模拟微信网页版环境,抓取发送相关request,达到网页版上几乎所有的功能。可以用该包实现很多有意思的微信小功能,如智能回复,流程化客服回复,自动添加好友,自动建群,群发消息等...
实验环境
我的实验环境如下:python 3.7 + PyCharm + Windows操作系统
- pip安装itchat方法
pip install itchat --upgrade- PyCharm安装itchat方法
点击"File" → "Settings" → "Defauilt Settings"(如果你对该项目有自己的设置,则点击"Settings")→ "Project Interpreter"→右上角选择你的python库位置(Project Interpreter:)→ 点击右侧的“+”→弹出的框中搜索"itchat",然后install即可。
入门上手
1. 实现微信文本消息的获取
先看代码实现:
import itchat
# 注册文本消息的监听
@itchat.msg_register(itchat.content.TEXT)
def print_content(msg):
print(msg['Text'])
itchat.auto_login()
itchat.run()
微信中定义了多种类型的数据,例如文本,图片,语音等,不同类型也对应了itchat中不同的注册参数,具体如下:
| 消息类型 | 注册参数 |
|---|---|
| 文本 | itchat.content.TEXT |
| 地图 | itchat.content.MAP |
| 名片 | itchat.content.CARD |
| 笔记 | itchat.content.NOTE |
| 分享 | itchat.content.SHARING |
| 图片 | itchat.content.PICTURE |
| 语音 | itchat.content.RECORDING |
| 文件 | itchat.content.ATTACHMENT |
| 视频 | itchat.content.VIDEO |
| 好友(添加消息等) | itchat.content.FRIENDS |
| 系统消息 | itchat.content.SYSTEM |
| 所有消息 | itchat.content.INCOME_MSG |
我们要监听哪种类型的消息,就需要写对应的注册参数,如果想要监听所有消息,可以使用itchat.content.INCOME_MSG
回到以上的代码例子,这里监听的是文本消息,运行该代码,会弹出一个二维码,用手机微信扫该二维码授权登录。这时,其他人给你发送的微信文本消息就可以直接输出在控制台了。可以自己给自己发送一条微信消息做测试。效果如下:

2. 实现消息发送
还是先看代码:
# coding=utf8
import itchat
itchat.auto_login(hotReload=True)
itchat.send('这是我的测试消息', 'filehelper')
这里,我们给微信上的“文件传输助手”发送了一条信息,打开手机微信可以看到该消息发送成功了。
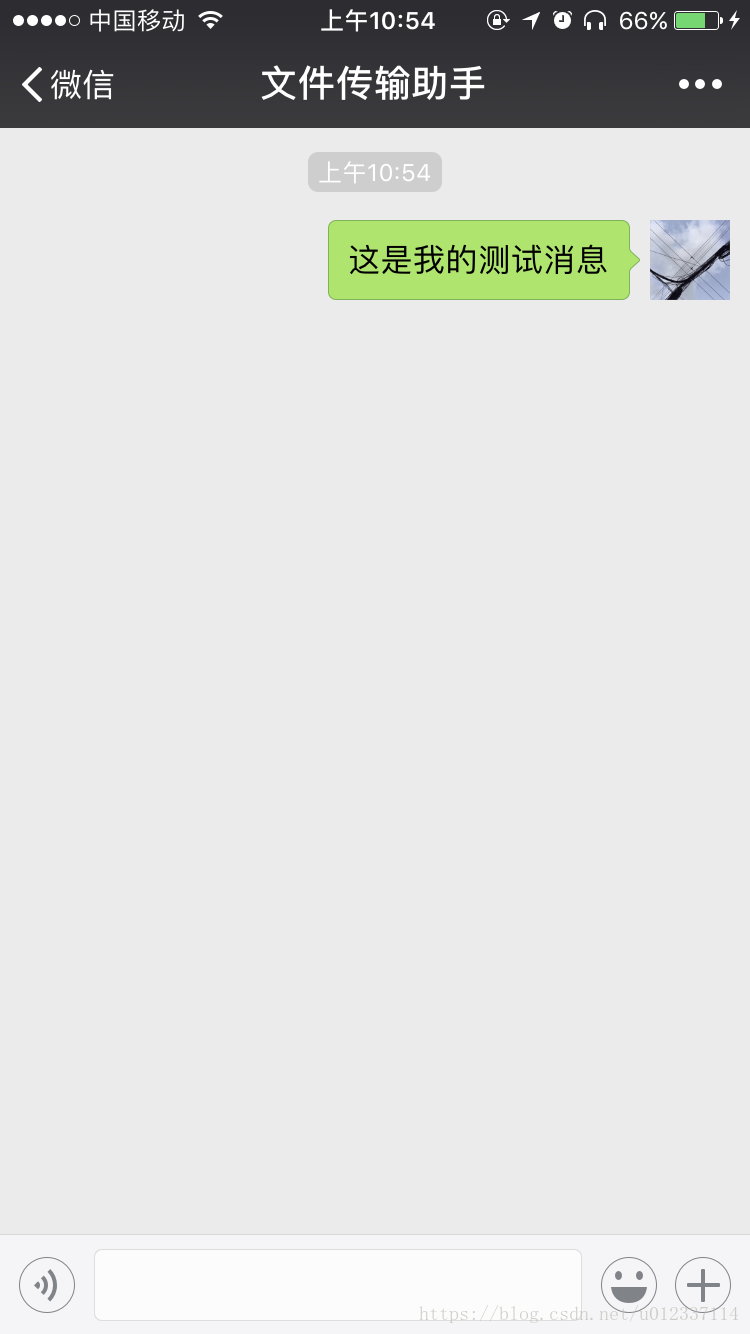
此处,我们将文本发送给了filehelper,如何发送给指定好友,或者指定群呢?这里就需要传该好友或群的UserName了,这个UserName不是微信名也不是微信号,如何获取后面再说。
至此,我们就已经完成了itchat的安装与消息收发。后面会尝试用它来实现更多有意思的功能。














 4337
4337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









