







转载地址:http://blog.csdn.net/google19890102/article/details/45848439
一、牛顿法
在博文“优化算法——牛顿法(Newton Method)”中介绍了牛顿法的思路,牛顿法具有二阶收敛性,相比较最速下降法,收敛的速度更快。在牛顿法中使用到了函数的二阶导数的信息,对于函数") ,其中
,其中 表示向量。在牛顿法的求解过程中,首先是将函数在
表示向量。在牛顿法的求解过程中,首先是将函数在 处展开,展开式为:
处展开,展开式为:
其中,") ,表示的是目标函数在的梯度,是一个向量。
,表示的是目标函数在的梯度,是一个向量。") ,表示的是目标函数在处的
Hesse
矩阵。省略掉最后面的高阶无穷小项,即为:
,表示的是目标函数在处的
Hesse
矩阵。省略掉最后面的高阶无穷小项,即为:
上式两边对求导,即为:
在基本牛顿法中,取得最值的点处的导数值为 ,即上式左侧为。则:
,即上式左侧为。则:
求出其中的:
从上式中发现,在牛顿法中要求
Hesse
矩阵是可逆的。
当 时,上式为:
时,上式为:
此时,是否可以通过 ,
, ,
,") 和
和") 模拟出
Hesse
矩阵的构造过程?此方法便称为拟牛顿法
(QuasiNewton),上式称为拟牛顿方程。在拟牛顿法中,主要包括DFP拟牛顿法,BFGS拟牛顿法。
模拟出
Hesse
矩阵的构造过程?此方法便称为拟牛顿法
(QuasiNewton),上式称为拟牛顿方程。在拟牛顿法中,主要包括DFP拟牛顿法,BFGS拟牛顿法。
二、DFP拟牛顿法
1、DFP拟牛顿法简介
DFP拟牛顿法也称为DFP校正方法,DFP校正方法是第一个拟牛顿法,是有Davidon最早提出,后经Fletcher和Powell解释和改进,在命名时以三个人名字的首字母命名。
对于拟牛顿方程:
化简可得:
令 ,可以得到:
,可以得到:
在DFP校正方法中,假设:
2、DFP校正方法的推导
令: ,其中
,其中 均为
均为 的向量。
的向量。-\bigtriangledown f\left ( x_k \right )") ,
, 。
。
则对于拟牛顿方程-\bigtriangledown f\left ( x_k \right ) \right ]=x_{k+1}-x_k") 可以简化为:
可以简化为:
将 代入上式:
代入上式:
将代入上式:
已知: 为实数,
为实数, 为的向量。上式中,参数
为的向量。上式中,参数 和
和 解的可能性有很多,我们取特殊的情况,假设
解的可能性有很多,我们取特殊的情况,假设 ,
, 。则:
。则:
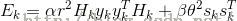
代入上式:
令 +1=0") ,
, -1=0") ,则:
,则:
则最终的
DFP
校正公式为:
3、DFP拟牛顿法的算法流程
设 对称正定,
对称正定, 由上述的
DFP
校正公式确定,那么对称正定的充要条件是
由上述的
DFP
校正公式确定,那么对称正定的充要条件是 。
。
在博文“优化算法——牛顿法(Newton Method)”中介绍了非精确的线搜索准则:Armijo搜索准则,搜索准则的目的是为了帮助我们确定学习率,还有其他的一些准则,如Wolfe准则以及精确线搜索等。在利用Armijo搜索准则时并不是都满足上述的充要条件,此时可以对DFP校正公式做些许改变:
DFP
拟牛顿法的算法流程如下:

4、求解具体的优化问题
求解无约束优化问题
其中,^T\in\mathbb{R}^2") 。
。
python
程序实现:
- function.py
- dfp.py
- testDFP.py















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









