







KMP算法快在哪?
先看看下面例子, 假设原串当前匹配的位置为i, 匹配串位置为j. (i下标绿色打底, j下标红色打底)
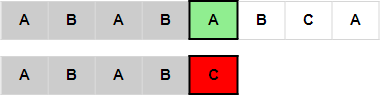
当原串与模式串(pattern)匹配失败后, i下标之前的字符肯定都是配对成功的。
KMP的核心思路是,我们能不能通过这些失配信息(匹配串的子串x, 即上图的"ABAB"), 找其中可能与子串x的前缀和后缀的最大重叠部分,使得j下标不总是从头开始匹配
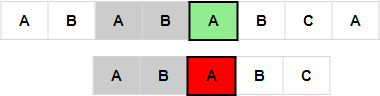
如上图所示,子串x的前缀"AB"和子串的后缀"AB"就是最大的重叠部分。我们只需将j下标移动到0 + 最大重叠部分的长度就可以省去中间无效的匹配。
什么是next数组?
next数组就是保存子串x的前缀和后缀最大重叠长度的数组。
在本文中next[k]代表着, 子串x的前缀和后缀公共部分的最大长度。(假设匹配失败时,模式串的下标为j, 那么子串x就是匹配失败时pattern[0 : j], 不包含j下标的字符)
一般而言,为了编程方便都会将next数组向右移动一个单位. 为了容易理解KMP算法,本文不做这一步处理。这意味在代码实现中
next[k]并不代表j的下一个值,而next[k-1]才是。
如何构建next数组?
关于如何使用next数组,上面我们的简单例子其实已经展示出来了,更重要的是怎么构建next数组
其实相当于模式串自己跟自己进行匹配
1.初始条件 next[0] = 0
p[0 : 0] 不存在前缀和后缀,最大长度必为0

2. 从第二个字符开始匹配, i = 1, j = 0, p[1] != p[0], 由于j == 0, next[1] = 0
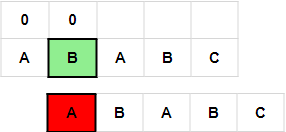
3. i = 2, j = 0, p[2] == p[1]; j = j + 1, next[2] = 1
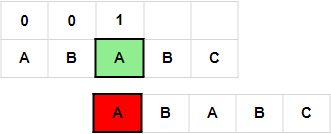
4. i = 3, j = 1, p[3] == p[1]; j = j + 1, next[3] = 2
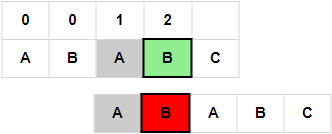
5. i = 4, j = 2, p[i] != p[j]; j = next[j-1]
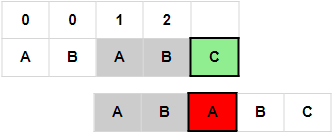
6. i = 4, j = 0, p[i] != p[j]; 由于, j == 0, next[4] = 0;
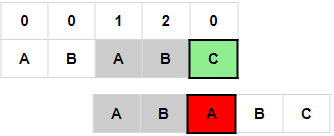
7.i = 5, next数组构造完成
代码实现
/**
* @brief Construct an array of maximum common substring lengths for
* prefixes and suffixes. "pmt[k]" means, the max length of common
* substring lengths for prefixes and syffixes of pattern's substr
* p[0: k + 1]. (it cotains character "p[k]")
*
* @param p pattern of matching.
* @return pointer to the table.
*/
unique_ptr<int[]> GetMaxComLenTable(const string& p) {
unique_ptr<int[]> pmt(new int[p.length()]);
int j = 0;
pmt[0] = 0; // 只有一个字符时没有前后缀.
// i指向的其实是后缀
// j指向的其实是前缀
for (int i = 1; i != p.length(); ++i) {
// 遇到不匹配的情况,利用已建好的信息快速调整.
while (j > 0 && p[j] != p[i]) j = pmt[j - 1];
if (p[j] == p[i]) ++j;
pmt[i] = j;
}
return std::move(pmt);
}
/**
* @brief Gets the position of the first matching pattern
* @param s matching string.
* @param p pattern string.
* @return : index of substr index.
* if length of p is 0, return 0.
* if failed return -1.
* @see the same as "strstr()" in glibc.
*/
int substr(const string& s, const string& p) {
int n = s.length();
int m = p.length();
if (m == 0) return 0;
auto next = GetMaxComLenTable(p);
int j = 0;
for (int i = 0; i != s.length(); ++i) {
// 当p[j]不匹配时,利用已匹配成功的子串信息
// 移动j到可能匹配的地方,从而减少匹配次数。
// j移动的下标恰为模式串(pattern)的子串p[0:j]
// 的公共前后缀最大长度
while (j > 0 && s[i] != p[j]) j = next[j - 1];
if (s[i] == p[j]) ++j;
if (j == m) {
return i - m + 1;
}
}
return -1;
}
另一个·版本
void BuildNextArr(vector<int>& next, const string& pattern) {
int i = 1, j = 0;
next[0] = 0;
while (i != next.size()) {
if (pattern[i] == pattern[j]) {
next[i] = j + 1;
++i;
++j;
continue;
}
while (j != 0 && pattern[i] != pattern[j]) {
j = next[j - 1];
}
if (j == 0 && pattern[i] != pattern[j]) {
next[i++] = 0;
}
}
}
int FindByKmp(const string& src, const string& pattern) {
if (pattern.size() == 0) return -1;
vector<int> next(pattern.size());
BuildNextArr(next, pattern);
int i = 0, j = 0;
while (i < src.size() && j != pattern.size()) {
if (src[i] == pattern[j]) {
++i;
++j;
continue;
}
while (j != 0 && src[i] != pattern[j]) {
j = next[j - 1];
}
if (j == 0 && src[i] != pattern[j]) {
++i;
}
}
return j == pattern.size() ? i - j : -1;
}
相关概念
前缀、后缀
例如, 字符串"abab"
其前缀包括{a, ab, aba},后缀包括{b, ab, bab}
前缀和后缀的最长公共部分为"ab"















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









