







 本文详细介绍了BF算法和KMP算法的原理及应用。BF算法通过暴力匹配完成字符串搜索,而KMP算法则通过计算NEXT数组优化了匹配过程,提高了搜索效率。
本文详细介绍了BF算法和KMP算法的原理及应用。BF算法通过暴力匹配完成字符串搜索,而KMP算法则通过计算NEXT数组优化了匹配过程,提高了搜索效率。
1.BF算法
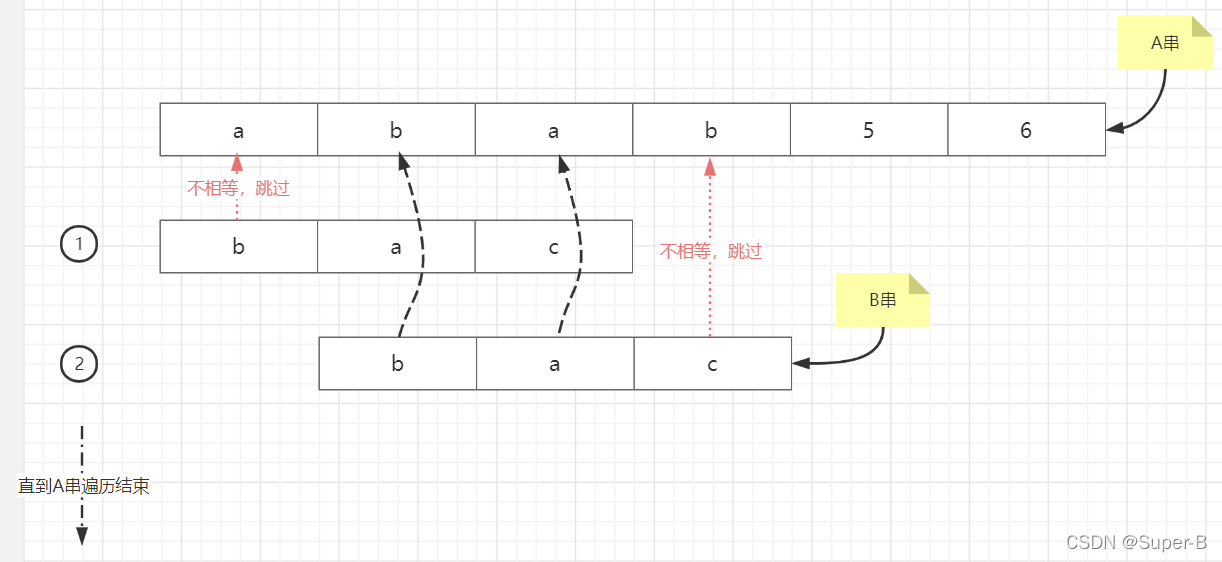
一开始解决这题的基本思想就是暴力匹配了,也就是BF算法,主串A,模式串B、
对A串从头遍历到尾,每个位置都和B串进行一一比对,有一个位置不等,那么遍历A串的下一个位置,直到A串中字串有和B相等的或者A串遍历到尾部了就结束。
实现代码如下:
public int strStr(String haystack, String needle) {
if (needle == null || needle.length() == 0) {
return 0;
}
if (haystack == null || haystack.length() < needle.length()) {
return -1;
}
char[] chars1 = haystack.toCharArray();
char[] chars2 = needle.toCharArray();
for (int i = 0; i <= chars1.length - chars2.length; i++) {
if (chars1[i] == chars2[0]) {
int j = 0;
for (; j < chars2.length; j++) {
if (chars1[i+j] != chars2[j]) {
break;
}
}
if (j >= chars2.length) {
return i;
}
}
}
return -1;
}
leetcode运行的结果如下:
这样做的算法复杂度还是挺高的,A串长度是n,B串长度是m,那么最坏的情况是o(n*m)时间复杂度,有没有办法缩短遍历时间呢?答案是有的,接下来看看怎么优化这个遍历过程。
2.KMP算法
BF算法里面,由于每次对比之后发现不相等的字符,就直接到下一个字符从头开始对比,这样每次对比失败的信息无法进行利用,效率低下。KMP算法会在对比失败的情况下,确定下一个对比的起点在哪里,比如下面这个例子:
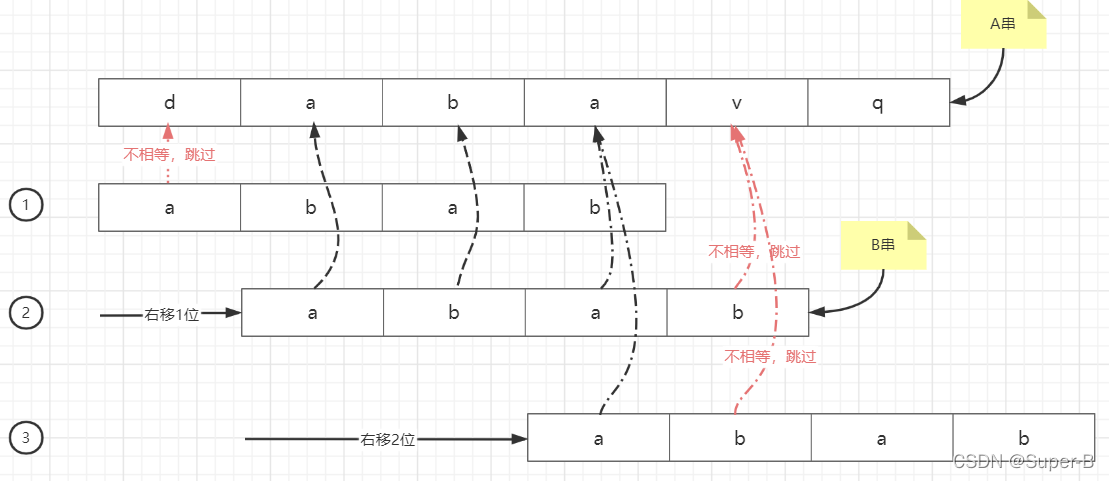
第二趟对比,在最后一个字符’b‘处,A串是’v‘,不相等,因此需要向右继续遍历,我们发现如果右移一位继续从头对比,B串“abab”和A串第2位(从0开始index)开始的字符“bava”开始对比,明显是必然不相等的,因此这次比较是可以跳过的,如果我们移动两位那么B串“abab” 和A串从第3位开始的字符“avq”(a之后的字符我们没有遍历到因此用省略号代替)是有可能相等的,因此在第二趟结束之后,右移两位开始对比字符串,以此类推直到相等字串找到或者index结束为止。
知道了如何节省遍历次数之后,现在问题就来了,如何确定每次不相等之后,需要跳过的位置是多大。
2.1 NEXT数组
next数组是对于模式串而言的。B串的 next 数组定义为:next[i] 表示 P[0] ~ P[i] 这一个子串,使得 前k个字符恰等于后k个字符 的最大的k. 特别地,k不能取i+1(因为这个子串一共才 i+1 个字符,自己肯定与自己相等,就没有意义了)。
就比如字符串:“abaabac” next数组为:[0,0,1,1,2,3,0],next[i]意思就是[0~i]这一段字符串的前缀和后缀字符相等的最大长度。
i = 0,“a”,自己不能等于自己,最大长度0;
i = 1,“ab” ,最大长度0;
i = 2,“aba”,前缀“a”,后缀“a”,最大长度是1;
i = 3,“abaa”,前缀“a”,后缀“a”,最大长度是1;
i = 4,“abaab”,前缀“ab”,后缀“ab”,最大长度是2;
i = 5,“abaaba”,前缀“aba”,后缀“aba”,最大长度是3;
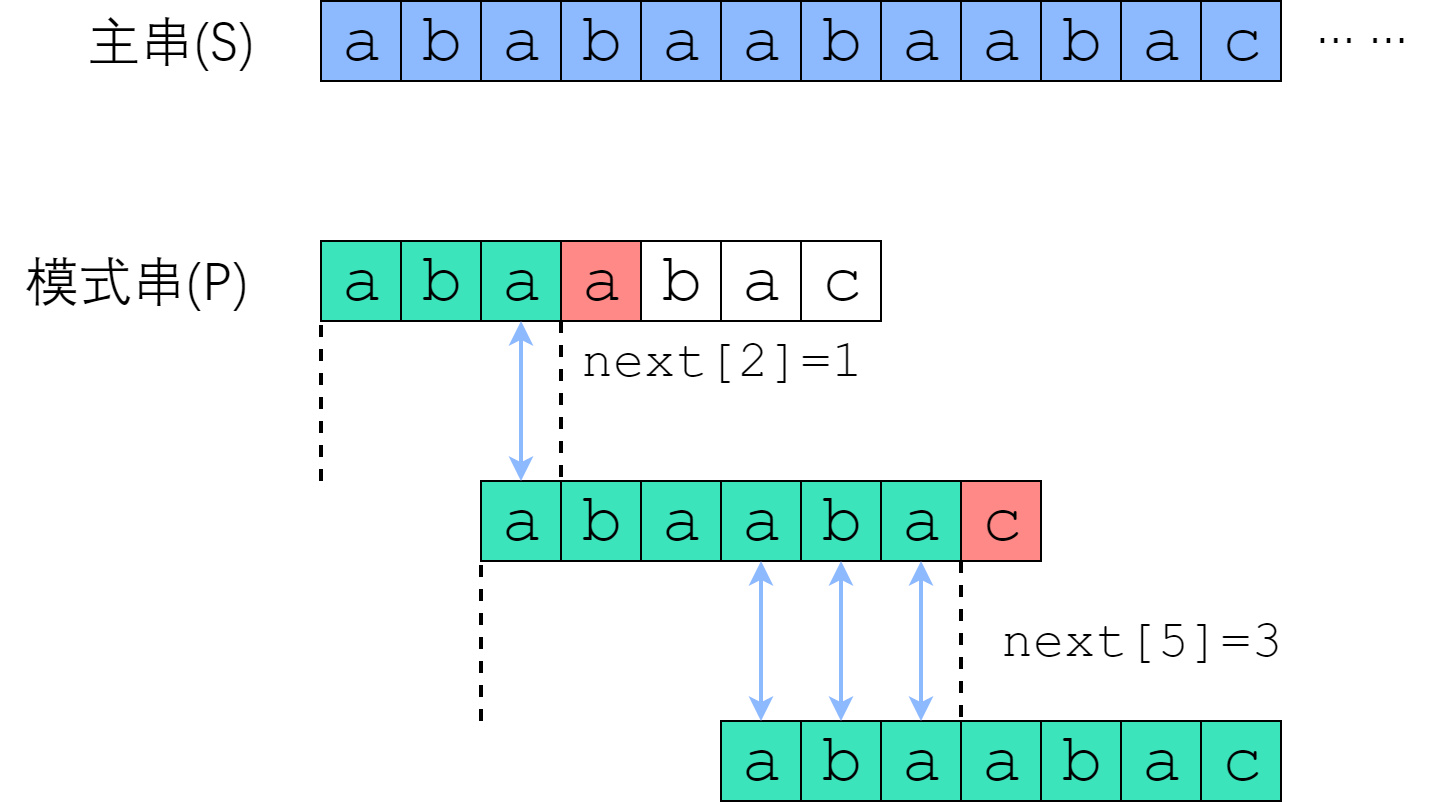
让我们看看上图,主串S和模式串P进行比对,从index 0开始,第一趟在p[3]处不相等,那么需要右移模式串p。
移动多少呢?
答:next求得的是pre前缀suffix后缀子串相等最大长度;根据next数据来决定向右移动多少。
为啥这样定义?
答:假设我们next定义的是pre前缀和模式串P中子串sub相等的最大长度,那么可以知道子串sub不一定就是模式串的末尾的字符串,那么按照当前next数组的定义,将相同的两个模式串p和p1按照前缀和字串sub对齐的话,sub字符串开始位置到p1结束的位置也不是所有字符和模式串p都相等。如图:
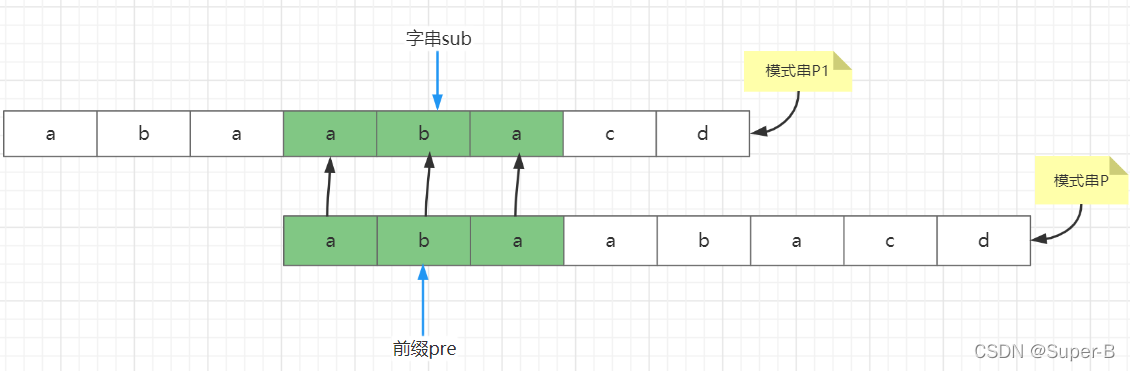
那么我们按照这种相等的子串最大长度去求next数组其实是没有意义的,假设我们主串S和模式串p对比的时候对比到模式串p的‘d’处不相等(那么可以说明s串可以表示为”…abaabac…“),那么我们需要右移模式串跳过无意义的对比,模式串p向前移动三位,对齐前缀pre和主串S(主串S可以用模式串p1代替,因为对比到‘d’位置都是同样的字符),因为最长的子串是”aba“,到了‘c’处不相等,那么这次右移三次位对比是必然不成功的,可以看出来子串sub的末尾必然需要在字符‘d’前一位,这样的话,右移三位之后,对比可以进行到‘d’处,之后是不确定是不是相等的,做到了尽可能的减少无意义的对比,所以结论就是next[i]代表这前缀和后缀相等的最长长度。
用最少的时间复杂度计算出Next数组
如果我们用很长的时间复杂度计算出next数组,那也没有意义,这样的损耗会和跳过的对比所节省的时间抵消,那就没有意义了,采用动态规划求得。
计算next数组:
定义模式串为P,next数组,当前位置是x;
- x == 0 时候,自己不能等于自己,next[0] = 0;
- p[x] = p[next[x-1]] 时候,next[x] = next[x-1] + 1;
- p[x] != p[next[x-1]] 时候,那么需要在p串的范围[0~next[x-1]]内寻找最长子串,如下图p[x]位置:
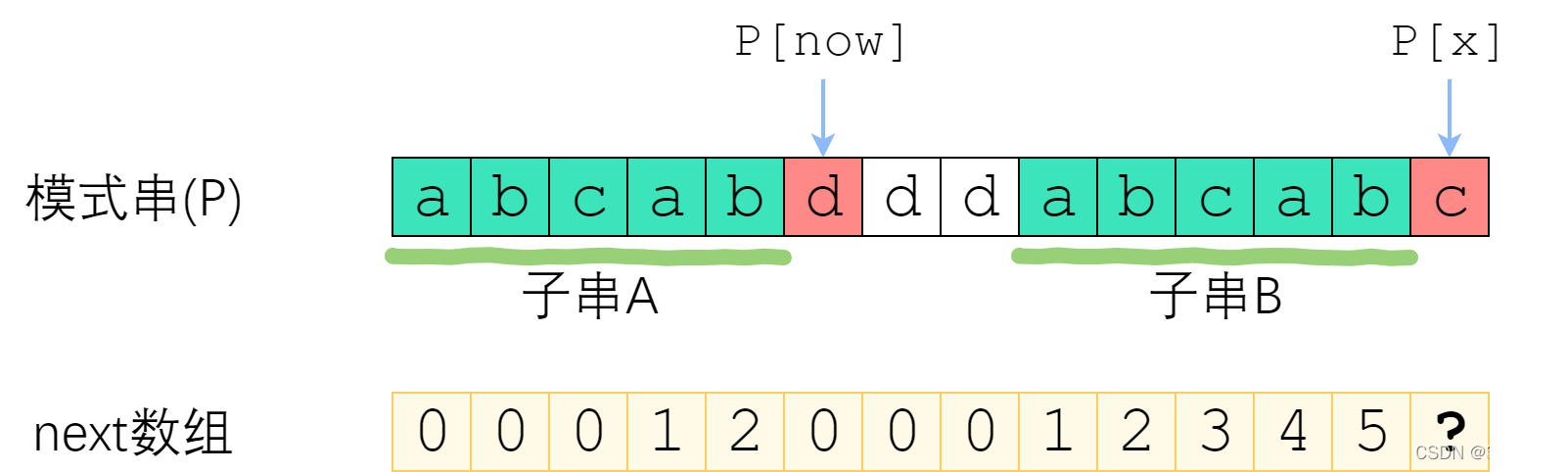 末尾的‘c’对比p[now]不相等,那么需要在范围[0~now]内继续寻找,就是要找到子串A的前缀,和子串B的后缀串相等的最长子串,由于子串A和子串B是相等的,那么就是寻找子串A的前后缀相等的最长子串,等于next[next[x-1]-1],假如p[next[next[x-1]-1]]还是和p[x]不相等的话,那么继续重复上面的步骤,直到0位置或者找到相等的字符‘c’就结束。
末尾的‘c’对比p[now]不相等,那么需要在范围[0~now]内继续寻找,就是要找到子串A的前缀,和子串B的后缀串相等的最长子串,由于子串A和子串B是相等的,那么就是寻找子串A的前后缀相等的最长子串,等于next[next[x-1]-1],假如p[next[next[x-1]-1]]还是和p[x]不相等的话,那么继续重复上面的步骤,直到0位置或者找到相等的字符‘c’就结束。
now的数值取决于迭代次数n,now(n) = next[now(n-1)],很显然n==1时候,now(1) = next[x-1];
通过以上的过程就可以求出next数组了,代码如下:
public int[] getNextArray(char[] chars) {
int[] next = new int[chars.length];
for (int i = 0; i < chars.length; i++) {
if (i == 0) {
continue;
}
if (i == 1) {
if (chars[1] == chars[0]) {
next[1] = 1;
}
continue;
}
int pos = next[i-1];
while (pos > 0) {
if (chars[i] == chars[pos]) {
next[i] = pos + 1;
break;
} else {
pos = next[pos - 1];
}
}
if (pos == 0 && chars[0] == chars[i]) {
next[i] = 1;
}
}
return next;
}
既然我们已经知道了next数组了,那么我们怎么利用next数组来优化我们的BF算法呢?
2.2 优化BF算法
我们在遍历主串S的时候,对比模式串p的过程中,如果需要不相等的情况,如图中红色方块的位置x,那么根据next数组,移动主串S的索引,index = index + (x-next[x]),移动之后,模式串开始和主串S比对,比对的起点要从前缀后一位开始,因为前缀已经确定是和主串相等的部分了。
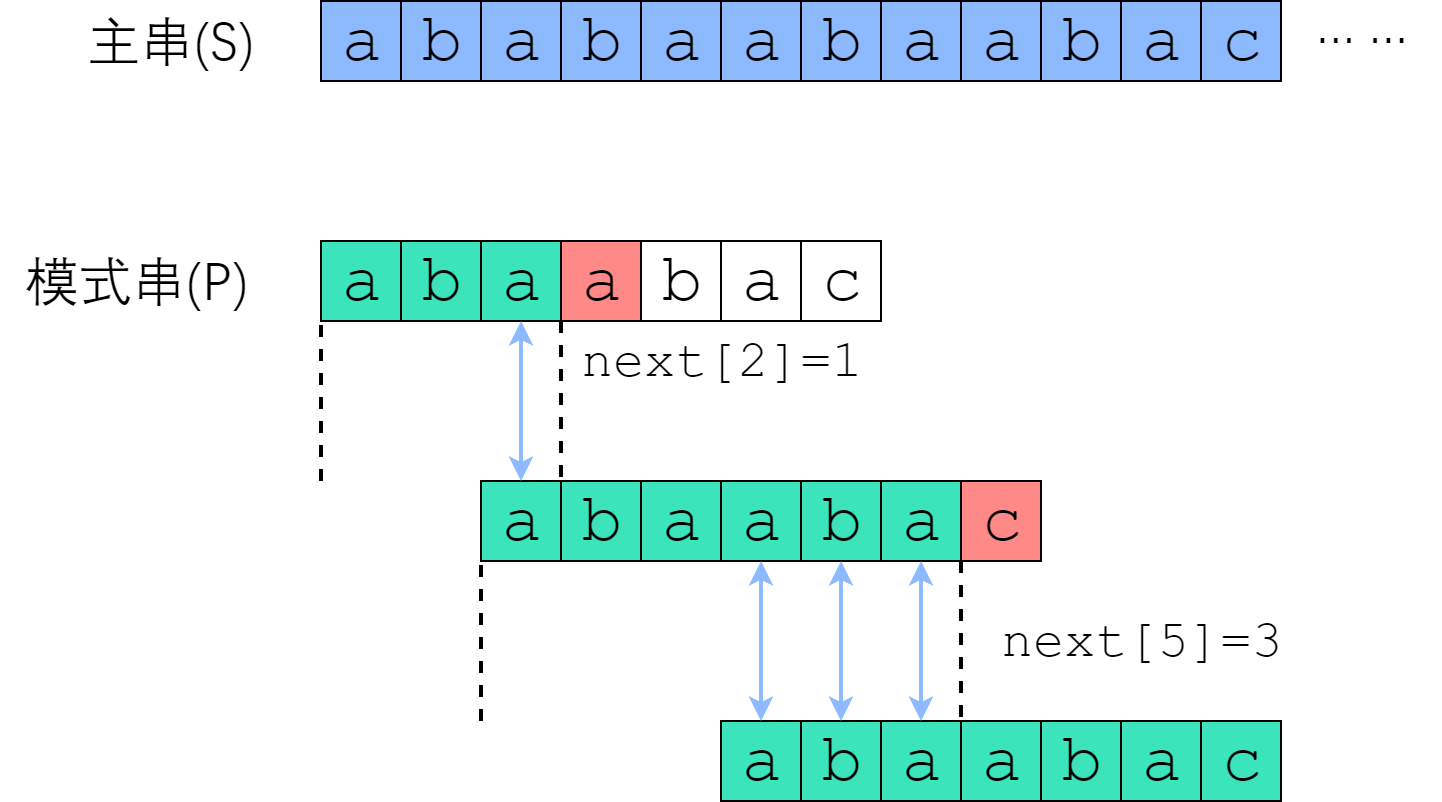
实现代码如下:
public int strStr(String haystack, String needle) {
if (needle == null || needle.length() == 0) {
return 0;
}
if (haystack == null || haystack.length() < needle.length()) {
return -1;
}
char[] chars1 = haystack.toCharArray();
char[] chars2 = needle.toCharArray();
int[] next = getNextArray(chars2);
int lastStep = 0;
for (int i = 0; i <= chars1.length - chars2.length; i++) {
if (chars1[i] == chars2[0]) {
int j = lastStep;
for (; j < chars2.length; j++) {
if (chars1[i+j] != chars2[j]) {
lastStep = next[j-1];
i += (j-next[j-1]) - 1;
break;
}
}
if (j >= chars2.length) {
return i;
}
}
}
return -1;
}
运行效率还是不错的,结果如下:
2.3 用next算法计算
将模式串p和主串S进行拼接,中间使用不会出现的字符’#'或者什么进行链接,如 p = “abc”,S = “aabdefjabc”,拼接之后 res = “abc#aabdefjabc”,使用next算法计算,因为求前后缀子串最大长度的话,只要前后缀子串最大长度等于模式串P长度,那么就说明字符串匹配成功了,用“#”分割正好可以把模式串P和主串S分隔开,前缀和后缀不可能有相交的部分,代码实现如下:
public int strStr(String haystack,String needle) {
if (needle == null || needle.length() == 0) {
return 0;
}
if (haystack == null || haystack.length() < needle.length()) {
return -1;
}
String comStr = needle + "#" + haystack;
return getNextArray(comStr.toCharArray(),needle.length());
}
public int getNextArray(char[] chars,int length) {
int[] next = new int[chars.length];
for (int i = 0; i < chars.length; i++) {
if (i == 0) {
continue;
}
if (i == 1) {
if (chars[1] == chars[0]) {
next[1] = 1;
}
continue;
}
int pos = next[i-1];
while (pos > 0) {
if (chars[i] == chars[pos]) {
next[i] = pos + 1;
if (next[i] == length) {
return i - 2 * length;
}
break;
} else {
pos = next[pos - 1];
}
}
if (pos == 0 && chars[0] == chars[i]) {
next[i] = 1;
if (next[i] == length) {
return i - 2 * length;
}
}
}
return -1;
}
leetcode允许结果如下:
3.结论
最优算法:BF算法使用next数组进行优化的算法,时间复杂度o(n+m)。
稍微差点:next算法查找拼接后的字符串的算法,时间复杂度o(n+m)。
最差:BF算法,时间复杂度o(n*m)。

















 3754
3754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









