






背景
因为客户使用的es版本为6.3.2,项目开发阶段一直用的es7.9.3,需要对项目中es降版本开发。实践开发中遇到的一系列问题,记录一下。本文的前提是项目中已经实现类es7.9.3版本的对接及增删改查接口的实现。
Es7.9.3整合springboot
主要是两块内容,配置ElasticSearchConfig,开发ElasticSearchService的实现es的增删改查接口,代码如下:
@Slf4j
@Configuration
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
private String esHost;
@Value("${elasticsearch.port}")
private Integer esPort;
@Value("${elasticsearch.username}")
private String userName;
@Value("${elasticsearch.password}")
private String password;
@Bean(name = "restHighLevelClient")
public RestHighLevelClient tqHighLevelClient() {
HttpHost host = new HttpHost(esHost, esPort, "http");
RestClientBuilder builder= RestClient.builder(host);
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
//设置用户名和密码:
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));
builder.setHttpClientConfigCallback(httpClientBuilder -> {
RequestConfig.Builder requestConfigBuilder = RequestConfig.custom()
.setConnectTimeout(28_800_000)
.setSocketTimeout(28_800_000)
.setConnectionRequestTimeout(28_800_000);
httpClientBuilder.setDefaultRequestConfig(requestConfigBuilder.build());
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
// httpclient保活策略
httpClientBuilder.setKeepAliveStrategy(
CustomConnectionKeepAliveStrategy.getInstance(10));
return httpClientBuilder;
});
RestHighLevelClient restClient = new RestHighLevelClient(builder);
return restClient;
}
}@Component
@Slf4j
public class ElasticsearchService {
@Autowired
private RestHighLevelClient tqHighLevelClient;
private static final String COMMA_SEPARATE = ",";
/**
* 创建索引
* @param index
* @return
*/
public boolean createIndex(String index) throws IOException {
if (isIndexExist(index)) {
log.error("Index is exits!");
return false;
}
//1.创建索引请求
CreateIndexRequest request = new CreateIndexRequest(index);
//2.执行客户端请求
org.elasticsearch.client.indices.CreateIndexResponse response = tqHighLevelClient.indices()
.create(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
}
/**
* 判断索引是否存在
* @param index
* @return
*/
public boolean isIndexExist(String index) throws IOException {
GetIndexRequest request = new GetIndexRequest(index);
boolean exists = tqHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
// tqHighLevelClient.close();
return exists;
}
/**
* 删除索引
* @param index
* @return
*/
public boolean deleteIndex(String index) throws IOException {
if (!isIndexExist(index)) {
log.error("Index is not exits!");
return false;
}
DeleteIndexRequest request = new DeleteIndexRequest(index);
AcknowledgedResponse delete = tqHighLevelClient.indices()
.delete(request, RequestOptions.DEFAULT);
return delete.isAcknowledged();
}
/**
* 数据添加,自定义id
* @param object 要增加的数据
* @param index 索引,类似数据库
* @param id 数据ID,为null时es随机生成
* @return
*/
public String addData(Object object, String index, String id) throws IOException {
//创建请求
IndexRequest request = new IndexRequest(index);
//规则 put /test_index/_doc/1
request.id(id);
request.timeout(TimeValue.timeValueSeconds(1));
//将数据放入请求 json
IndexRequest source = request.source(JSON.toJSONString(object), XContentType.JSON);
//客户端发送请求
IndexResponse response = tqHighLevelClient.index(request, RequestOptions.DEFAULT);
return response.getId();
}
/**
* 数据添加 随机id
* @param object 要增加的数据
* @param index 索引,类似数据库
* @return
*/
public String addData(Object object, String index) throws IOException {
Class<?> clazz = object.getClass();
Field[] fields = clazz.getDeclaredFields();
String idStr = UUID.randomUUID().toString().replaceAll("-", "").toUpperCase();
for (Field field : fields) {
field.setAccessible(true);
//判断字段是否包含注解
try {
Object id = field.get(object);
if (field.isAnnotationPresent(ESId.class)) {
if (id != null) {
idStr = id.toString();
}
break;
}
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
return addData(object, index, idStr);
}
/**
* 通过ID删除数据
*
* @param index 索引,类似数据库
* @param id 数据ID
* @return
*/
public void deleteDataById(String index, String id) throws IOException {
DeleteRequest request = new DeleteRequest(index, id);
tqHighLevelClient.delete(request, RequestOptions.DEFAULT);
}
public void deleteDataByQuery(String index, String id) throws IOException {
DeleteByQueryRequest request = new DeleteByQueryRequest(index);
request.setQuery(new TermQueryBuilder("fileId",id));
tqHighLevelClient.deleteByQuery(request, RequestOptions.DEFAULT);
}
/**
* 通过ID 更新数据
*
* @param object 要更新数据
* @param index 索引,类似数据库
* @param id 数据ID
* @return
*/
public void updateDataById(Object object, String index, String id) throws IOException {
UpdateRequest update = new UpdateRequest(index, id);
update.timeout("1s");
update.doc(JSON.toJSONString(object), XContentType.JSON);
tqHighLevelClient.update(update, RequestOptions.DEFAULT);
}
/**
* 通过ID获取数据
*
* @param index 索引,类似数据库
* @param id 数据ID
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @return
*/
public Map<String, Object> searchDataById(String index, String id, String fields) throws IOException {
GetRequest request = new GetRequest(index, id);
if (StringUtils.isNotEmpty(fields)) {
//只查询特定字段。如果需要查询所有字段则不设置该项。
request.fetchSourceContext(new FetchSourceContext(true, fields.split(","), Strings.EMPTY_ARRAY));
}
GetResponse response = tqHighLevelClient.get(request, RequestOptions.DEFAULT);
return response.getSource();
}
public <T> T searchDataById(String index, String id, Class<T> tClass) throws IOException {
GetRequest request = new GetRequest(index, id);
GetResponse response = tqHighLevelClient.get(request, RequestOptions.DEFAULT);
return JSON.parseObject(response.getSourceAsString(), tClass);
}
/**
* 查询全量(其实也是分页循环查询)
*
* @param indices 索引名称,多个时逗号分隔
* @param searchSourceBuilder 查询的builder
* @param options 请求类型
* @param tClass 返回对象的类
* @param propertyNamingStrategy 转换策略(PropertyNamingStrategyConstant.class)
* @param <T> 泛型
* @return 返回查询出来的全量数据
* @throws IOException 抛出io异常
*/
public <T> List<T> searchAll(@NonNull String indices, @NonNull SearchSourceBuilder searchSourceBuilder,
@NonNull RequestOptions options, @NonNull Class<T> tClass, Integer propertyNamingStrategy) throws IOException {
String[] indexArray = indices.split(COMMA_SEPARATE);
Objects.requireNonNull(indices, "indices must not be null");
for (String index : indexArray) {
Objects.requireNonNull(index, "index must not be null");
}
if (ORIGINAL.equals(propertyNamingStrategy)) {
} else if (PropertyNamingStrategyConstant.UNDERSCORE_TO_CAMEL.equals(propertyNamingStrategy)) {
} else {
throw new RuntimeException("propertyNamingStrategy is not found");
}
return searchAll(indexArray, null, searchSourceBuilder, options, tClass, propertyNamingStrategy);
}
}问题一:Springboot版本与es版本不一致
如图所示,项目中springboot版本2.4.2,与其对应的es版本是7.9.3,我们要改es版本为6.3.2,对应springboot版本为2.1.x。此时需要做一个选择,是否要降springboot版本适应es6.3.2。因为项目比较复杂,降springboot版本影响较大,为避免出现其他jar版本冲突或者api不兼容问题,非bi必须,不考虑降低springboot版本。
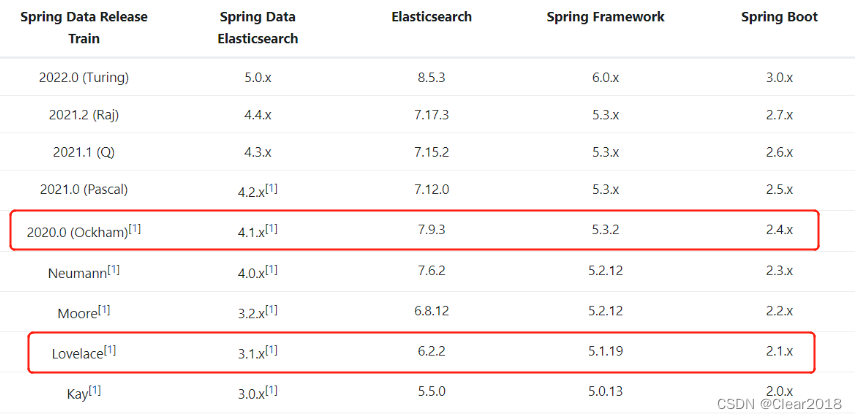 多模块项目中需要在parent.pom中定义es相关jar的版本,不然会在子模块中出现springboot一致的es7.9.3版本。定义如下:
多模块项目中需要在parent.pom中定义es相关jar的版本,不然会在子模块中出现springboot一致的es7.9.3版本。定义如下:
<!-- 版本依赖管理器 -->
<dependencyManagement>
<dependencies>
<!-- SpringBoot 版本管理器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<groupId>org.elasticsearch.client</groupId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<artifactId>elasticsearch</artifactId>
<groupId>org.elasticsearch</groupId>
<version>${elasticsearch.version}</version>
</dependency>
</dependencies>
</dependencyManagement>问题二:重写es6.3.2的api
因为es6.3.2api与7.9.3版本不一致,需要重新编写ElasticsearchService
增删改demo参考es6.3.2增删改查demo
问题三:业务需求多字段分组聚合计算词频分页查询
业务需求,根据关键词检索文献,要求文献按上传时间排序,分页查询结果,因上传的文献存在超大文档,会对超大文档进行切分上传到es中,所以此需求需要根据fileId,createTime分组,汇总词频值,根据createTime排序后进行分页。
注意:因为没找到排序、分页的方法,所以获取到所有结果,在java应用中排序分页...
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.should(QueryBuilders.wildcardQuery("text.keyword", "*" + dto.getKeyword() + "*"));
sourceBuilder.query(boolQueryBuilder);
sourceBuilder.fetchSource(false);
Map<String, Object> paramsMap = new HashMap<>();
paramsMap.put("key", dto.getKeyword());
//词频计算脚本,painless语言(和java类似)
String scriptStr = "xxx";
Script script = new Script(ScriptType.INLINE, "painless", scriptStr, paramsMap);
//构建聚合
List<CompositeValuesSourceBuilder<?>> sources = new ArrayList<>();
sources.add(new TermsValuesSourceBuilder("fileId").field("fileId.keyword"));
sources.add(new TermsValuesSourceBuilder("createTime").field("createTime.keyword"));
CompositeAggregationBuilder compositeAggregationBuilder = new CompositeAggregationBuilder("multi_field_agg", sources);
compositeAggregationBuilder.size(10000);
compositeAggregationBuilder.subAggregation(AggregationBuilders.sum("total_keywordCount"). script(script));
sourceBuilder.aggregation(compositeAggregationBuilder);
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
//hit是所有命中文档数,作为分页查询的total并不准确,需要做一步去重
long total = searchResponse.getHits().getTotalHits();
//处理搜索结果
RestStatus restStatus = searchResponse.status();
if (restStatus != RestStatus.OK) {
log.error("检索报错 restStatus={}",restStatus);
throw new RuntimeException("文献检索报错");
}
Aggregation agg = searchResponse.getAggregations().get("multi_field_agg");













 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









