







背景
众所周知,机器学习领域的飞速发展带来了巨大的商机,而机器学习在工程化道路的发展上,也从手工作坊和验证试运行的工作模式,逐步过渡到大规模部署的生产模式,这是可预见到的 AI/ML 发展的必然趋势。
谈到 MLOps 的发展就不能不提到它的起源,这要回溯到2018年,在谷歌举办的一场演讲中,业内专业人士首次公开谈及了在生产环境中对机器学习生命周期进行管理的必要性。
作为一个趋势,到2024年底,75%的企业在 AI/ML 的交付模式会从“Pilot/PoC 模式”逐步转换为“可运维的 AI/ML ”模式 —— Gartner。
这是 Gartner 对 MLOps 的一个预测。这里面提到的“Pilot/PoC 模式”实际上指的是一种我们现在在机器学习领域进行开发和最终发布时,通常看到的一种工作方式,亦即一切都基本上以模糊的、实验性的、手工操作为主的方式。而与之相反的就是“可运维的 AI/ML”模式,这种方式是今天我要探讨的主题——这是一种能帮助企业在机器学习领域达到生产级别的工作模式。生产级别的机器学习,具备大规模扩展、可持续、可审计、可靠、可重复等五大要素的工程模式。
另外,无论对于任何一个 IT 企业,只有产品上线到生产环境里,才能真正的产生价值,机器学习领域也不例外,而 MLOps 正是可以实现这个目标的有效保障,接下来我们谈一下什么是 MLOps?
什么是 MLOps?
MLOps 是 DevOps 的近亲,它是一种哲学和实践的结合,它借鉴并基于 DevOps 的大量基础方法论和技术栈,旨在使数据科学和 IT 团队能够快速开发、部署、维护和扩展机器学习模型。
同时,它也是跨数据工程、数据科学和开发人员与系统运维团队的统筹与协调方面的方法论和实践,以管理机器学习模型从数据准备,训练到部署的整个生命周期。

正如 IT 产业内许多新事物的发展规律一样,MLOps 从2018年第一次被提出之后至今的短短几年之中,业内雨后春笋般诞生了各种与 MLOps 相关的技术和产品,他们当中有开源的也有闭源的,有的是 MLOps 复杂工具链中的一环,有的则是全栈产品;有的是云平台从自身平台属性出发设计的产品,而还有的是从数据工程师的角度去设计的。总之,大家都说自己是 MLOps!
然而遗憾的是,当最终用户想把上述产品拿来直接开始使用时,他们会发现很多功能强大的产品,却无法控制不同角色操作者(数据工程师、开发和运维)的权限,或者需要高昂的学习成本,或者需要在不同的控制台之间切来切去…….这种不甚完美的事情一直在发生着,仿佛是所有工程效能领域领域的一个永远解不开的谜。
本文将描述一个十分轻量级、学习成本非常低的端对端的 MLOps 解决方案的具体实现,它充分利用了 GitOps 思想,把 git 作为用户唯一需要理解的用户接口,并融入了基于主干的开发的思想,还利用了 Gitlab Hook 来帮助企业建立代码的合规性、把大部分 MLOps 涉及到的开发流程结合在了一起。这样,企业可以以极低的学习和部署成本,快速建立起不同角色间的协作关系,便于快速将 AI/ML 投入到快速迭代的良性循环之中。
Micro-MLOps 系统架构

系统流程
开始训练
当算法工程师开始自己的工作时,其可以通过从主干(main)代码上建立一个名为“feature-xxx”的自有分支来作为每次工作的开始点。注意这个分支的命名规范通常是提前和最终用户约定好的,本实现中默认为“feature-”作为前缀。如果工程师不按照这个约定来创建的分支,将不会触发后续自动流水线。由于本文对应的源代码可以在 Amazon samples(https://github.com/aws-samples/micro-mlops) 得到,所以您可以根据实际落地客户的喜好,通过源代码的修改来默认命名规范,比如将前缀命名为“experiment-”等,本文的后面部分将会介绍代码结构。如图:
该分支的拉取和命名,建议遵循敏捷开发的最佳实践,功能尽量小而紧凑,能够快速验证并能够尽快回到主干。
本方案的设计之中,采用了基于主干的开发(https://trunkbaseddevelopment.com)作为分支策略。如下图所示:

每次当算法工程师进行 push 操作时,将会触发 GitLab 的训练/测试流水线,并且每次训练的结果,将会以 comments 的形式追加到当前 feature 分支的 commit 里。如下图所示:

由于不同的训练代码,总会产生出不同的测试结果和图形,为了让流水线能够进行灵活的衔接,在本方案里,用一个名为“.feature.settings”配置文件给 feature 分支的操作者(通常是 ML 算法工程师)。该文件是一个 json 格式的配置文件,内容如下。
{
"feature": {
"FEATURE_REPORT": "metrics.txt,confusion_matrix.png",
"FEATURE_DEPENDENCIES": "requirements.txt",
"FEATURE_TRAIN_ENABLED": "yes",
"FEATURE_TRAIN": "train.py -d xxx.data",
"FEATURE_TEST_ENABLED": "yes",
"FEATURE_TEST": "test.py -d xxx.data"
}
}左滑查看更多
配置说明如下:

这个配置文件,控制了训练代码,和训练测试代码的行为,给操作提供了灵活性。如果想添加更多的控制,可以修改源代码去提供这样的支持。
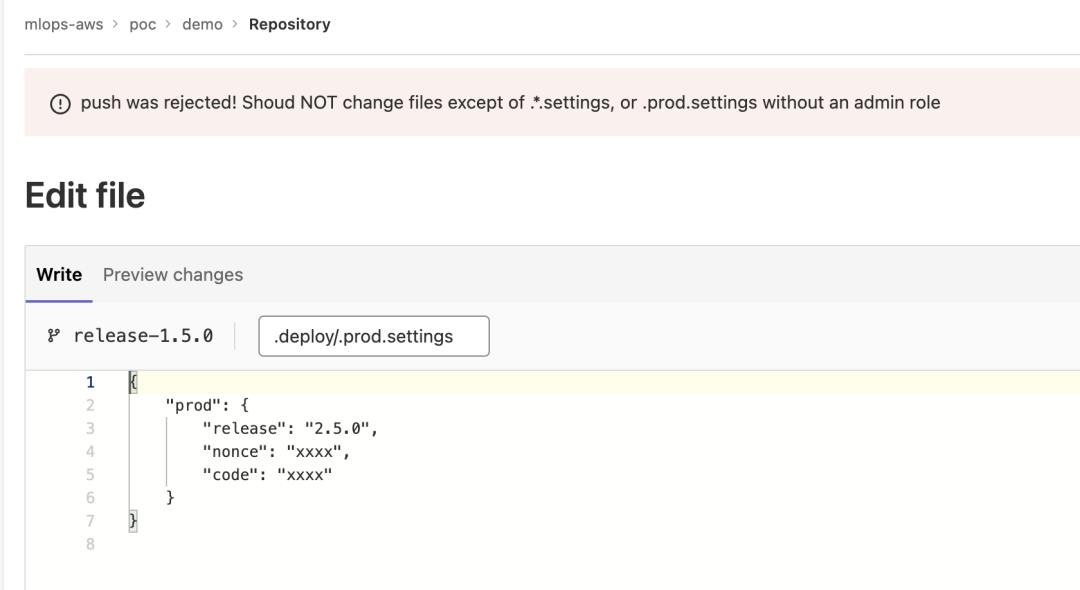
需要注意的是,该文件必须由 feature 分支的拥有者方可编辑并 push,否则合规性检测将会给予错误提示,最终将不能成功提交。反之,如果在 feature 分支上修改了.deploy 目录下的文件,也会被合规检测拦截。如图所示:
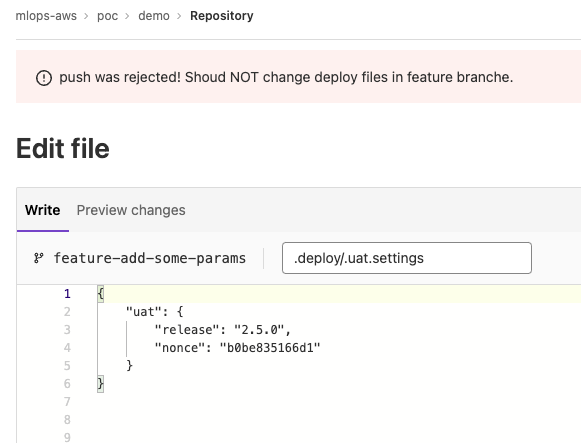
同样,如果一次 feature 分支上的 commit 里包含了一部分“合法的”的可以变更的文件,和一部分不合法的文件变更(比如 .deploy 下面的文件),都会被系统拦截。
数据工程师,经过反复的 push 代码来迭代自己的训练,直到觉得训练结果满意为止。
按照 DevOps 的最佳实践原则,我们鼓励测试人员编写所有与当前 feature 有关的测试用例,在 py 中,并在每次训练执行之后,执行测试并输出测试结果(如 testResult.txt,同样可以放到 FEATURE_REPORT 中去,以 comment 的最终形式展现给开发者/QA,以得到最佳效果。
合并到主干
当算法工程师认为训练已经达到了某种最佳状态,可以通过提交合并请求(Merge Request, MR)进入到代码审核(Code Review)环节。在该环节,需要按照一般的软件开发共识来进行代码审核,比如指定有经验的代码审查人(Reviewer)来做这件事。
当算法工程师,将合并请求提交成功之后,也就是 MR 创建之后,系统将自动触发 MR 流水线,在该环节,系统将自动将当前主干的代码与当下 feature 分支的代码进行合并(称之为“预合并”),如果发现有合并冲突导致失败,将失败整个流水线,此情况下,流程将不能往下继续进行,数据开发者将必须在 feature 分支上解决掉潜在的合并冲突后,再次申请代码合并。

如果上述过程都没有问题,流水线将执行预合并后的代码,并进行相应的测试,如果全程没有问题,则测试结果将在 comments 里予以体现。
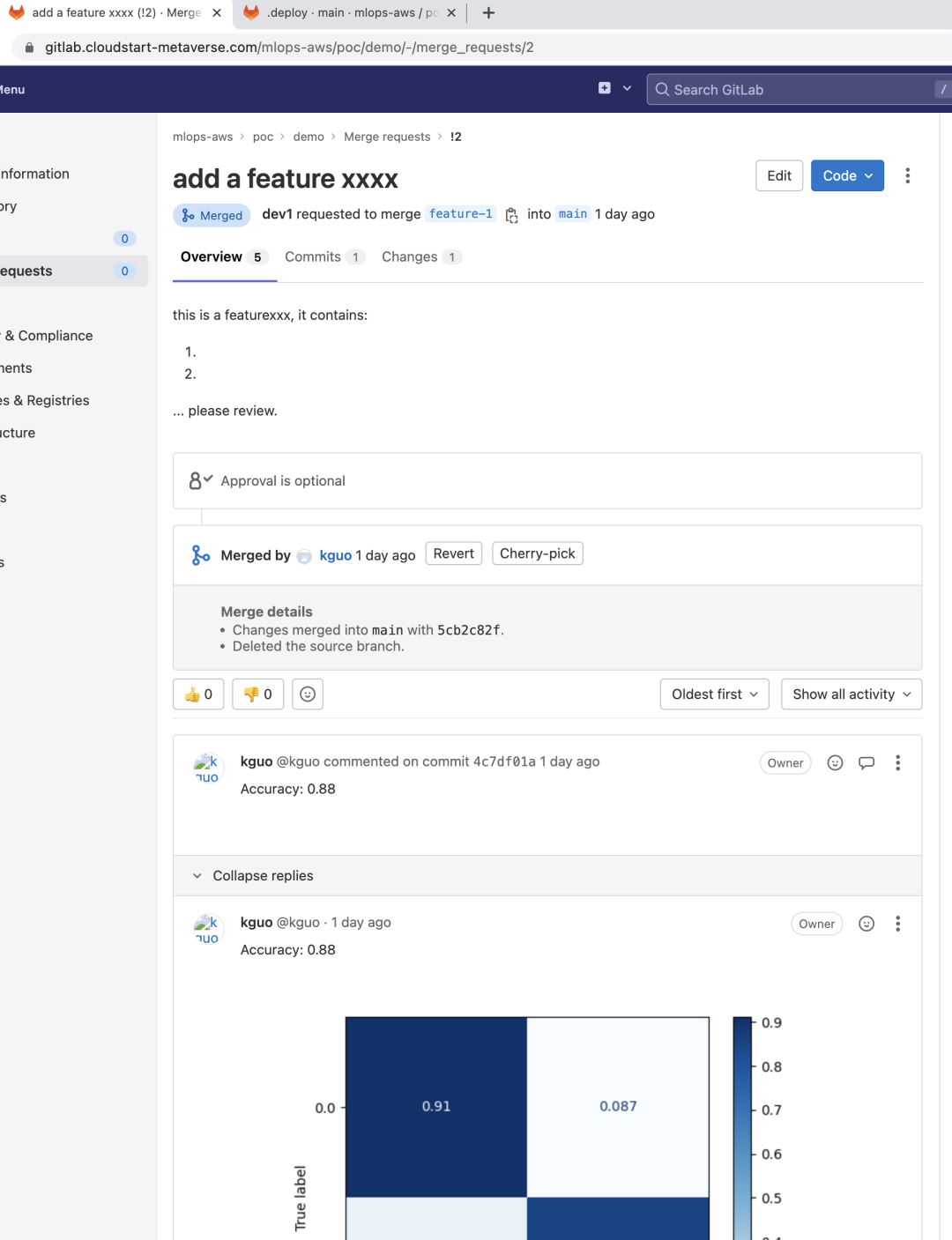
当代码审核者打开此 MR 时,他需要做的是,查看自动流水线完成后给予的测试结果,如果是流水线失败了,则意味着数据工程师需要重新提交 Code Review。
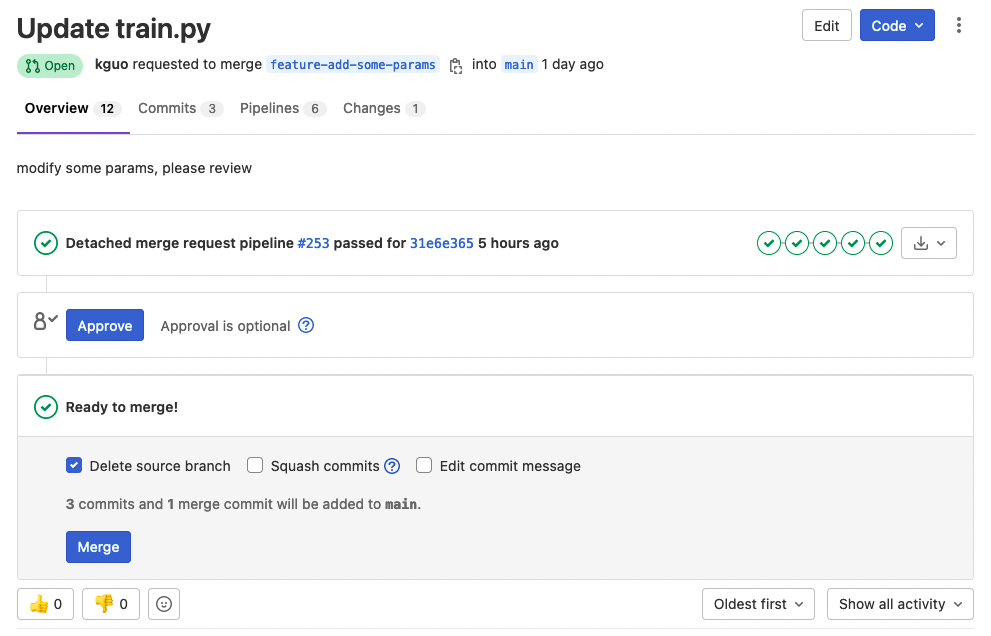
如果自动流水线给出了正确的结果,代码审核人如果在查看了代码的变更之后仍然觉得有问题,则可以让这次合并请求失败,不予放行。
因此,作为最重要的一个环节,我们需要流水线和代码审核人都赞同,才能过进行一次成功的代码合并。这样设计的目的是尽可能保障主干的安全。
当代码被最终推入主干之后,系统会自动触发一个新的流水线,这个流水线的任务是将本次合并的代码版本,进行镜像的构建,并将其传输到 Amazon ECR 中备用,同时,还会自动将其部署到开发环境(Dev Environment)。在本实现中,训练模型和推理代码将被部署到 EKS 上,并以 Repo 所在的分组名称,以及项目名称作为关键字,拼接在一起,形成独特的 Namespace/Deployment/Service/Ingress 命名。本文展示的 Kubernetes 命名空间为“mlops-aws-poc–dev”,如图。

此时,数据开发者或者 QA 便可以在测试环境中,对最终发布的微服务进行手工或自动的集成测试,以验证其功能的正确性。在此再次重申自动化测试的重要性,虽然它的确不容易达成。
以上步骤将由企业内的所有算法开发者并行操作,周而复始,不断迭代。
以上整个过程,我们称之为 MLOps 流程当中的持续集成(CI)部分。
Release/Hotfix 流程
当开发者在主干不断迭代的同时,在某个时刻,企业的产品拥有者(PO)会从商业角度来决定何时进行 Release,一旦决定下来,他将会从主干的某一次提交,建立出一个 release 分支,来正式进入一个产品版本的发布工作。
Release 分支的命名依旧是遵从事前的约定,否则拉出的分支将无法触发后续的自动流水线,也无法最终被部署到测试环境和生产环境。在这里,Release 分支的命名规范为“release-1.5.0”,不但格式是强约束的,而且最后一位一定是“0”。如图所示。

同理,hotfix 分支的命名规范形如“hotfix-1.5.1”,注意最后一位一定不是“0”,后台流水线会首先检查分支命名的合理性。
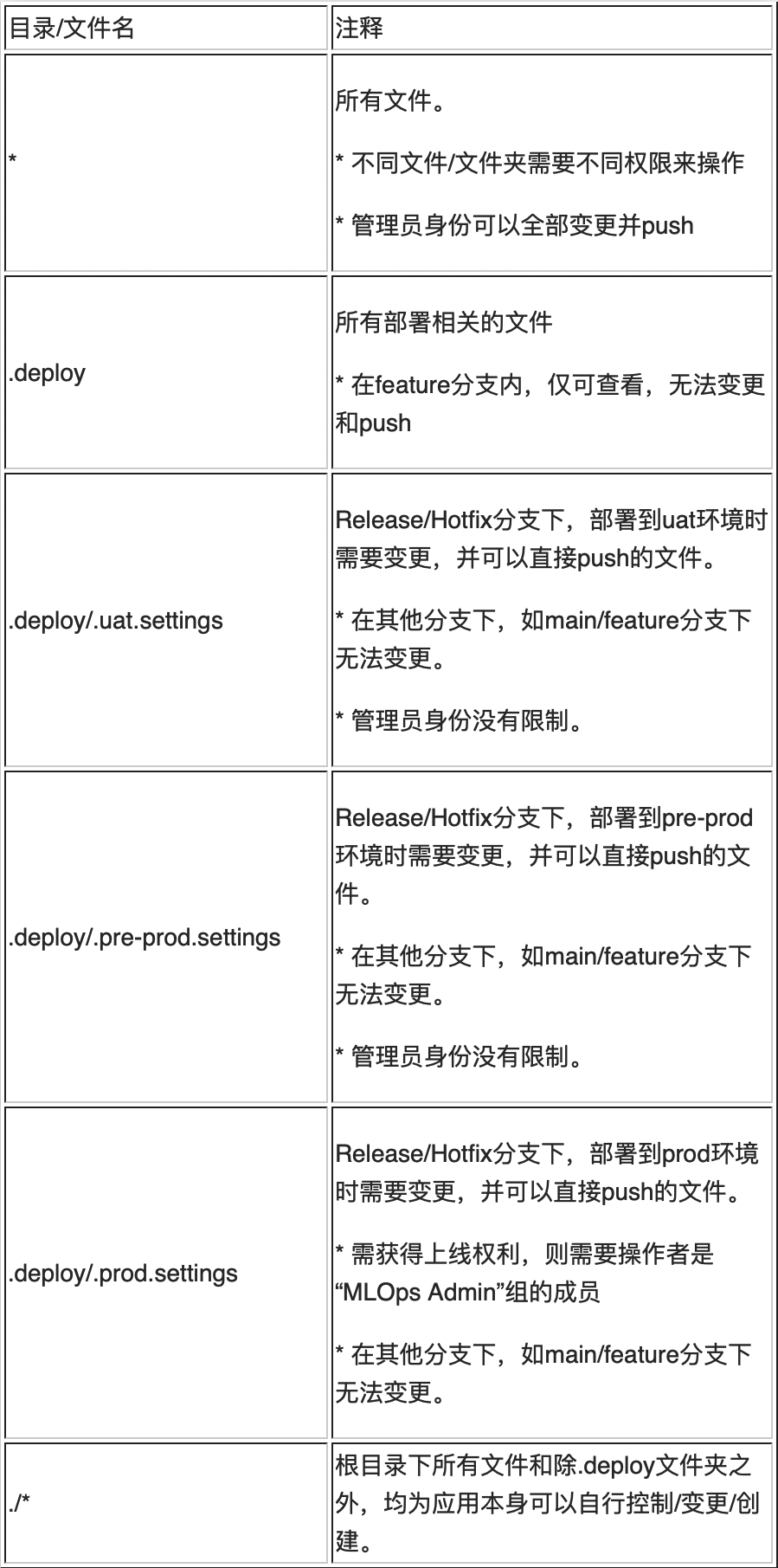
在 Release 分支拉出,到最终部署到生产,通常会遵从 uat(用户接受测试),和 pre-prod(预生产),本实现提供了极简的操作方案:以部署到 uat 环境为例,仅需要有权限的人,在 release 分支内变更“.deploy/.uat.settings”文件,并 push 即可触发相应的自动化流水线进行相应的部署。
部署到 pre-prod(预生产)环境与部署到 uat(用户接受测试)环境的过程一致,仅需修改“.pro-pred.settings”文件并 push。

当所有上线前的测试都完成之后,可以进行生产环境的上线。如果是具备权限的人修改“.prod.settings”文件并 push,则可以部署到生产环境。如果是没有权限的操作者,试图去提交对 .deploy/.prod.settings 文件变更的时候,会被提示不合规而最终不能提交代码到 feature 分支上。
源代码
工程样例
代码结构

说明
流水线
代码结构

说明
目录/文件名 | 注释 |
custom_hooks/pre-received.d | Gitlab 的服务端 Hook代码 |
Dockerfiles | Gitlab 流水线用到的 docker image 文件 |
Jobs | Gitlab 流水线代码 |
Templates | Gitlab 流水线代码 |
安装和配置
Gitlab 安装
选择一台 EC2,x 社区版本安装,参见本文(https://gitlab.cn/install/#amazonlinux-2)。
确保系统上包含 x。
运行 pip install –upgrade python-gitlab。
确保系统上安装了 git。
Gitlab 配置 Hook
Ssh登录到 Gitlab 服务器,选择一个目录(basedir),git clone https://github.com/aws-samples/micro-mlops.git ,拷贝 <basedir cicd-templates/ custom_hooks/* 到 /var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/
执行 chmod +x /var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/*.sh
执行chown git:git /var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/*
编辑 /etc/gitlab/gitlab.rb, 找到“gitaly[‘custom_hooks_dir’]”的配置项,并去掉去掉注释状态。
gitaly['custom_hooks_dir'] = "/var/opt/gitlab/gitaly/custom_hooks"左滑查看更多
在 Gitlab 中配置一个 Private Access Token(PAC),具体步骤见本文
(https://docs.gitlab.com/ee/user/profile/personal_access_tokens.html)。
修改 /var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/.gitlab.conf 如下。
[main]
url = http://localhost
private_token = <PAC>
api_version = 4执行 gitlab-ctl reconfigure 使 Gitlab Hook 生效。
Gitlab Runner 安装和配置
选择另一台 EC2,安装 Gitlab Runner,具体步骤参见本文(https://docs.gitlab.com/runner/install/linux-manually.html)。
ssh 登录到 Runner 所在的 EC2,修改配置文件 /etc/gitlab–runner/config.toml,在[[runners]]下添加下列配置。
[runners.custom_build_dir]
enabled = true执行 gitlab-runner restart 使配置生效。
Gitlab 配置环境变量
在合适的范围内,如 repo 或者某个组上,配置 Gitlab 几个环境变量,如图所示。

环境变量
Variable Name | Value |
AK | Amazon 密钥名称 |
SK | Amazon 密钥密码 |
AWS_DEFAULT_REGION | Region 名,如 us-east-1 |
CLUSTER_NAME | EKS Cluster Name, 如 my-test-k8s |
DOCKER_REGISTRY | 用于存储 ML 推理镜像的私有 ECR 地址 |
DOCKER_REGISTRY_PUBLIC | 用于存储流水线用到的工具镜像的公开 ECR 地址 |
repo_token | 调用 Gitlab API 时所需的 PAC Token |
Gitlab 配置流水线
编辑 cicd-templates/templates/default-pipeline.yaml,修改 EKS 和 ECR 有关配置信息。修改完成后提交到 Gitlab 中,如下。
CLUSTER_NAME: <Your-Kubernetes-Cluster-Name>
DOCKER_REGISTRY_PUBLIC: <public.ecr.aws/Your-Public-Image-Repo Name>
DOCKER_REGISTRY: <Your-Account-Id>.dkr.ecr.<Your- Region>.amazonaws.com
AWS_DEFAULT_REGION: <Your-Region-Name>左滑查看更多
Build 并推送流水线需要的 docker image 到用户亚马逊云科技账号的 ECR 中, 最终效果如图所示。

配置 Micro-MLOps 的权限
权限控制是将特权用户放到一个名为 mlops-admin 的组内。
在这个组的用户将可以执行生产环境的上线操作。
可以利用 GitLab 内置的不同角色(owner/maintainer/developer 等)来设定更复杂的权限,本文仅展示了在/不在这个组内的最简化的权限控制。
推荐的组和项目之间的布局
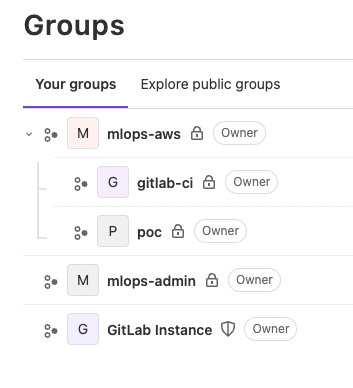
权限控制组为 mlops-admin
mlops-aws 组下有2个子组,gitlab-ci 内包含 cicd-templates 工程。该组只能给使用 pipeline 的所有用户和组以只读权限(reporter),防止对 pipeline 的非法篡改。如图所示:
poc 组下存放开发者日常使用的 ML 工程,并可按照 Gitlab 通常的方式来分配权限。如图所示:
总结
本文提供了一个轻量级的 MLOps 实现,旨在提供一种快速适应客户侧需求变化的 MLOps 流程和框架。后续将根据客户的实际需求继续迭代功能,请随时关注 Amazon samples(https://github.com/aws-samples/micro-mlops)。
本篇作者

Kelvin Guo
亚马逊云科技资深解决方案架构师。主要技术方向为 MLOps, DevOps 容器。20年+软件开发,项目管理,敏捷思想落地,工程效能咨询经验。

冯源
亚马逊解决方案架构师。工作涉及企业混合云环境运维管理、运营管理、混合云平台等。有十余年企业基础设施咨询及实施、项目管理和交付以及混合云平台研发管理经验。2022年加入亚马逊云科技,负责零售、餐饮和制造等行业客户。现阶段在认真学习和熟悉亚马逊云科技服务和产品,关注混合云及混合云环境下的应用部署和管理。


听说,点完下面4个按钮
就不会碰到bug了!

















 9118
9118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









