







前言
现如今,随着用户对于容器化技术掌握的越来越成熟,越来越多相应的应用被进行了基于容器的现代化构建,其中 Amazon EKS 又是其中的首选支撑平台。在实际走访中发现,对于 Infra 或者容器平台的责任人来说,有一类问题经常会被反复探讨:为了保障各个应用都能够稳定的运行,该应用什么样的隔离保障措施,都有什么样的资源需要进行隔离,相应的优劣势是什么?从整体上来说,EKS/Kubernetes 本身不存在多租户相关的内置资源对象,不过其生态中存在着两大类可以采用的隔离措施,借助这些隔离措施可以实现多租户的效果, 其简单的示意图如下所示:
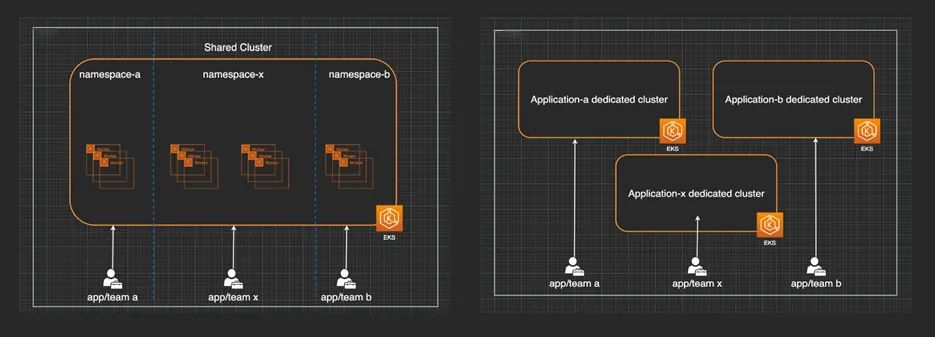
▌“软”隔离(上图左):即多个应用运行在同一个集群,利用 namespace 及相关策略进行资源隔离
● 优点:
• EKS 单集群可支撑上千节点的工作负载,单集群可减少多控制平面的花费
• 资源利用率相对较高
• 省去了多集群管理的复杂工作
● 缺点:
• 需要考虑单集群运维对各个应用团队的影响
• 需要考虑集群内各种资源隔离的配置
▌“硬”隔离(上图右):即不同的应用运行在不同的集群之中,甚至不同的 vpc 之中,实现“物理”意义上的隔离
● 优点:
• 没有吵闹的邻居影响
• 不需要配置复杂的集群内策略
● 缺点:
• 控制平面会产生额外的花费
• 需要设计集群切分的粒度
• 资源利用率相对较低
• 跨集群访问和相应的监控较为复杂
对于“硬”隔离来说,其在网络层面,计算资源等层面都是默认“物理”隔离,因此在 kubernetes 层面并不需要太多关注。对于“软”隔离来说,应用处于同一集群之中,计算资源、网络资源、存储资源等默认都是可通可达,那么如何利用云原生和 Amazon 服务处理“软”隔离便是本系列的探讨重点。对于“软”隔离策略来说,其主要的关注点如下:
● 计算资源隔离
● 网络隔离
● 存储隔离
● 服务等级(SLA)
● 租户计费
● 租户连通性
● 其他
在本文中主要集中对于“软”隔离策略下计算资源隔离的讨论,其他内容会在后续的文章进行展开。
方案概述
考虑计算资源隔离,其主要涉及的内容为:Namespace 隔离,底层计算资源的隔离及对应资源的隔离。对应于以上考量点,我们主要分为如下两个场景进行展开讨论。
● 场景1: 负载稳定,不涉及到工作节点的自动伸缩
● 场景2: 负载不稳定,涉及到工作节点的自动伸缩
场景1 /
负载稳定,不涉及到工作节点的自动伸缩
对于企业内部应用或者负载较为平稳的应用来说,对隔离程度的需求不同,通常情况下我们采用的策略也分为两种:
● namespace 级别的资源限制
● 指定工作节点 +namespace 级别的资源限制
▌方案1
可以根据各个应用部门申请的资源额度,设置对应 namespace 的资源限额(Quota)。然后统计出集群中整体对于资源的申请情况,从而确定集群工作节点所需要的数量。配置如下:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-quota
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi如果需要把对应的 Quota 应用到指定的 Namespace 只需要:kubectl xx.yaml --namespace = target-namespace即可。在示例中,大家可以看到 limit 的值是 request 的值的两倍,这样设置是为了让集群内的资源利用更高,客户可以根据自身的波动情况进行对应改造。
▌方案2
相对于方案1来说,我们需要为不同的业务应用做资源隔离,也就是创建不同的 nodegroup。实际应用中,只需要将不同 namespace 的 Quota 和对应 nodegroup 的资源匹配,即可满足不同应用的计算资源需求。比如,application-a 需要 8core16g 的资源,application-b 需要 8core32g 的资源,那么对应的 ResourceQuota 可以分别配置如下。
# for application a
kubectl create ns namespace-a
cat <<EOF | kubectl apply -n namespace-a -f -
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-quota
spec:
hard:
requests.cpu: "8"
requests.memory: 16Gi
limits.cpu: "8"
limits.memory: 16Gi
EOF
# for application b
kubectl create ns namespace-b
cat <<EOF | kubectl apply -n namespace-b -f -
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-quota
spec:
hard:
requests.cpu: "8"
requests.memory: 32Gi
limits.cpu: "8"
limits.memory: 32Gi
EOF左滑查看更多
配置完 quota 后,还需要在应用和 nodegroup 上做相应的配置。其中,nodegroup 上需要添加对应的标签。
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: managed-cluster
region: us-west-2
managedNodeGroups:
- name: application-a-ng
type: m5.2xlarge
tags:
app/team: application-b对于应用 b 的 deployment 需要添加相应的节点选择器来选中上述节点组中的节点。
namespace: namespace-b
nodeSelector:
app/team: application-b对于应用 a 来说,配置类似,在此就不展开赘述。如果希望在 node 侧做进一步限制的话,可以额外添加如下配置:
# 在node上的配置
$ kubectl taint nodes node1 app/team=application-a:NoSchedule
# 需要添加在pod上的配置
apiVersion: v1
kind: Pod
```
spec:
containers:
```
tolerations:
- key: "app/team"
operator: "Equal"
value: "application-a"
effect: "NoSchedule"左滑查看更多
在 eksctl 中也有通过脚本统一为 nodegroup 中节点打标签的配置,可参考:
https://eksctl.io/usage/nodegroup-taints/
场景2 /
负载不稳定,涉及到节点的自动伸缩
在场景2中,由于负载的不稳定,导致集群中工作负载(Pod)和底层的工作节点(EC2)会出现波动,如何使得业务容器的扩缩容和其底层工作节点得到匹配便是最主要的挑战。场景2本质上是场景1方案2的一个扩展,我们不仅需要为不同的应用配置不同 nodegroup,还需节点扩展工具能够支持基于 namespace 业务应用进行扩容。虽然在 kubernetes 中并没有一个工具直接支持 namespace 级别的扩容,但是基于目前主流工具对标签的支持,我们可以实现类似的功能。具体来讲
▌基于 Cluster AutoScaler 实现租户资源的定向扩展
● 创建多个 nodegroup,每个 nodegroup 具有指定的标签
• 比如如下两个 nodegroup,分别对应 app/team: application-x 的标签
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: managed-cluster
region: us-west-2
managedNodeGroups:
- name: application-a-ng
labels: {app/team: application-a}
- name: application-b-ng
labels: {app/team: application-b}左滑查看更多
● 对于应用来说,创建对应业务应用的 deployment 文件,设定 node selector 到上述对应的节点上。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec
```
nodeSelector:
app/team: application-a● 当对应的应用扩容,但是底层没有节点的时候,CA 会依据策略调用 nodegroup 进行扩容
CA 遵循 nodeSelector 和 requiredDuringSchedulingIgnoredDuringExecution,不遵循软限制如:preferredDuringSchedulingIgnoredDuringExecution
▌基于 Karpenter 实现租户资源的定向扩展
● 因为 Karpenter 为 groupless 模式,所以其不需要预先配置 nodegroup
● Karpenter 支持两种模式的定向扩展
• 多provisioner模式
• 其本质跟基于 CA 的定向扩展原理相同,不同的 provisioner 对应不同的资源池,应用通过亲和性标签从而触发对应资源池的扩展。
• 单 provisioner 模式
(https://karpenter.sh/v0.16.3/tasks/scheduling/)
• 只需要在 provioner 配置类似如下的标签
...
requirements:
- key: company.com/team
operator: Exists
...那么当应用的节点选择器中包含如下标签的时候,对应启动的 EC2 节点都会被打上 team-a 相关的标签,后续对应的应用也只会落在存在 team-a 相关标签的 EC2 资源池中
nodeSelector:
company.com/team: team-a如果应用不添加对应标签,那么会给该类应用对应的工作节点随机打一标签。
实验
本环节会针对于场景2的描述进行展开试验,其大致步骤如下:
● 创建 namespace-a、namespace-b、namespace-c;
● 基于 yaml 文件生成带有 app/team=application-b、app/team=application-a 的工作节点;
● 部署 nginx 应用,并且指定部署在 namespace-c、namespace-a、namespace-b 以及对应 namespace 所匹配的工作节点,观察是否能够部署成功,以及相应启动速度;
● 使用 OPA/Gatekeepr 等 mutation webhooks 工具自动化完成租户匹配和相关策略限制。
基于 CA 的定向扩展
▌前提条件
● 安装 eksctl、kubectl
● 配置好对应的 IAM 权限
● 基于官方文档进行 CA 在 EKS 上的安装,详情见最后参考章节
配置除了集群名称,都保持默认即可
● 创建三个 namespace
执行如下语句,创建三个租户 a、b、c 所使用的 namespace
kubectl create ns namespace-b
kubectl create ns namespace-a
kubectl create ns namespace-c● 下载 Github repo
git clone jansony1/container-lab
通过下面的指令,修改模版中 ${Cluster-name} 为当前集群名称,然后添加 namespace-a 和 namespace-b 所对应的工作节点组
$ eksctl create ng -f multi-tenant/yaml/cluster/cluster.yaml
[ec2-user@ip-10-1-1-239 ~]$ kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
ip-10-1-4-230.us-west-2.compute.internal Ready <none> 46m v1.23.9-eks-ba74326 alpha.eksctl.io/cluster-name=test-eks,alpha.eksctl.io/nodegroup-name=application-b-ng,app/team=application-b
ip-10-1-4-89.us-west-2.compute.internal Ready <none> 46m v1.23.9-eks-ba74326 alpha.eksctl.io/cluster-name=test-eks,alpha.eksctl.io/nodegroup-name=application-a-ng,app/team=application-a左滑查看更多
本步骤中如果不采用现有模版,也可自行通过 kubectl label 相关的指令给每个节点打上对应的标签。
▌实验部分
首先查看示例代码
[ec2-user@ip-10-1-1-239 blog]$ cat multi-tenant/yaml/nginx/nginx-dp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app/team: application-c
namespace: namespace-c
spec:
replicas:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: app/team
operator: In
values:
- application-c
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80左滑查看更多
其中上图中的 requiredDuringSchedulingIgnoredDuringExecution,强制性指定需要匹配 label 含有 app/team=application-c 的节点。通过观察,我们发现 pod 一直处于 pending 状态,进而查看 pod 状态。
[ec2-user@ip-10-1-1-239 blog]$ kubectl describe pods nginx-deployment-5b8c88f7dc-2s9tn -nnamespace-c
Name: nginx-deployment-5b8c88f7dc-2s9tn
Namespace: namespace-c
Warning FailedScheduling 51s default-scheduler 0/4 nodes are available: 4 node(s) didn't match Pod's node affinity/selector.左滑查看更多
可以看到,因为集群中并没有 application-c label 的节点,故一直无法启动。那么接下来我们实验把上面 nginx-dp 的匹配选项改为 app/team=application-b,namespace 也改为 application-b,并且把节点数量扩展到5个,如下图所示
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app/team: application-b
namespace: application-b
spec:
replicas: 10
···
spec:
···
- key: app/team
operator: Exist
values:
- application-b左滑查看更多
需要注意的是,默认情况下基于 nodegroup 自动发现的逻辑,CA 只会调整 ASG 中 desired 的机器数量,会遵循 nodegroup 配置的 min 和 max;所以如果我们没有在创建 nodegroup 显示配置的话,那这一步 pod 的启动会被卡住。
查看对应的 pod 状况:
[ec2-user@ip-10-1-1-239 blog]$ kubectl get pods -nnamespace-b -w
NAME READY STATUS RESTARTS AGE
nginx-deployment-5dc75cb7c4-2m9ph 1/1 Running 0 27s
nginx-deployment-5dc75cb7c4-8nx2g 1/1 Running 0 26s
nginx-deployment-5dc75cb7c4-9tb4d 1/1 Running 0 117s
nginx-deployment-5dc75cb7c4-jrs8b 1/1 Running 0 119s
nginx-deployment-5dc75cb7c4-x4mv2 1/1 Running 0 120s左滑查看更多
排除两个已有的节点,可以看到大概花费了120秒的时间,能够实现额外三个节点加入集群,以及基础的 nginx 应用的部署。另外通过查看 CA 的日志,可以发现 CA 遵循了对应的亲和性,可以达到定向扩展的需求。
$ kubectl log -nkube-system cluster-autoscaler-787b49979f-zfllk -f
I1003 14:25:59.757031 1 filter_out_schedulable.go:157] Pod namespace-b.nginx-deployment-7b599f7555-f9wf2 marked as unschedulable can be scheduled on node ip-10-1-4-97.us-west-2.compute.internal. Ignoring in scale up.
I1003 14:25:59.757076 1 filter_out_schedulable.go:157] Pod namespace-b.nginx-deployment-7b599f7555-ndvgq marked as unschedulable can be scheduled on node template-node-for-eks-application-b-ng-fac1cc71-cf13-3164-1368-9f9140e422e8-7129107115182662064-upcoming-1. Ignoring in scale up.
I1003 14:25:59.757103 1 filter_out_schedulable.go:157] Pod namespace-b.nginx-deployment-7b599f7555-jbsqh marked as unschedulable can be scheduled on node ip-10-1-4-53.us-west-2.compute.internal. Ignoring in scale up.
I1003 14:25:59.757125 1 filter_out_schedulable.go:171] 3 pods marked as unschedulable can be scheduled.
I1003 14:25:59.757135 1 filter_out_schedulable.go:79] Schedulable pods present
I1003 14:26:09.774263 1 static_autoscaler.go:230] Starting main loop
I1003 14:26:09.774713 1 clusterstate.go:248] Scale up in group eks-application-b-ng-fac1cc71-cf13-3164-1368-9f9140e422e8 finished successfully in 1m30.437631771s左滑查看更多
▌清理
为了避免 CA 和 karpenter 互相干扰,在下一实验开始前,请卸载 CA,以及通过如下指令清除 deployment。
kubectl delete deployment nginx-deployment -nnamespace-b
基于 Karpenter 的定向扩展
▌前提条件
● 部署 Kapenter 在集群中, 详见最后的参考部分
▌实验部分
制作 provisioner,本环节将会分别生成 application-a-provisioner 和 application-b-provisioner,分别负责应用 a 和应用 b 的计算资源需求。执行下述操作生成 provisioner,注意在执行前把 ${CLUSTER_NAME} 换成自己的
kubectl apply -f multi-tenant/yaml/provisioner/
我们可以看到对应的两个 provisioner 已经生成。
[ec2-user@ip-10-1-1-239 blog]$ kubectl get provisioners
NAME AGE
application-a-provisioner 38s
application-b-provisioner 17s左滑查看更多
两个 provisioner 的主要区别,主要为下面的 taint 对应的应用部门不同,即工作节点不同。
kind: Provisioner
metadata:
name: application-x-provisioner
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["m5.large", "m5.2xlarge"]
taints:
- key: app/team
value: application-x
effect: NoSchedule
labels:
app/team: application-a左滑查看更多
该 provisioner 生成的节点都具有 app/team=application-x label 和 污点,应用如果想落在对应的机器,需要有对应的 toleration 和 nodeselector 才可。继续查看 nginx 的代码,我们可以看到其对应的 toleration 和资源的配置。
$ cat nginx-dp-kpt.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-kpt
labels:
app/team: application-a
namespace: namespace-a
spec:
replicas: 5
...
spec:
nodeSelector:
app/team: application-a
tolerations:
- key: app/team
operator: "Equal"
value: "application-a"
effect: "NoSchedule"
containers:
...
resources:
requests:
memory: "2048Mi"
cpu: "1500m"
limits:
memory: "2048Mi"
cpu: "1500m"左滑查看更多
执行部署
kubectl apply -f multi-tenant/yaml/nginx/nginx-dp-kpt.yaml
观察执行结果
[ec2-user@ip-10-1-1-239 blog]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-kpt-585c679d5d-5kc8r 1/1 Running 0 96s
nginx-deployment-kpt-585c679d5d-j9g6t 1/1 Running 0 96s
nginx-deployment-kpt-585c679d5d-jgkvh 1/1 Running 0 96s
nginx-deployment-kpt-585c679d5d-lhx6s 1/1 Running 0 96s
nginx-deployment-kpt-585c679d5d-p54h5 1/1 Running 0 96s左滑查看更多
可以看到,所有 pod 在 100s 内完成了就绪。查看 karpenter 的日志,我们发现其遍历了多个 provisioner,并从中选择了匹配的 provisioner-a,且自动合并了我们多个 pod 请求,从而在列表中选择了较大的机型进行启动,避免了多次调用 Amazon API,以及相应时间的消耗。
2022-10-04T07:12:17.207Z INFO controller.provisioning Found 3 provisionable pod(s) {"commit": "5d4ae35-dirty"}
2022-10-04T07:12:17.207Z INFO controller.provisioning Computed 1 new node(s) will fit 3 pod(s) {"commit": "5d4ae35-dirty"}
2022-10-04T07:12:17.207Z INFO controller.provisioning Launching node with 3 pods requesting {"cpu":"4594m","memory":"6Gi","pods":"6"} from types m5.2xlarge {"commit": "5d4ae35-dirty", "provisioner": "application-a-provisioner"}
2022-10-04T07:12:17.389Z DEBUG controller.provisioning.cloudprovider Discovered security groups: [sg-049758300817976ce] {"commit": "5d4ae35-dirty", "provisioner": "application-a-provisioner"}
2022-10-04T07:12:17.393Z DEBUG controller.provisioning.cloudprovider Discovered kubernetes version 1.23 {"commit": "5d4ae35-dirty", "provisioner": "application-a-provisioner"}
2022-10-04T07:12:17.428Z DEBUG controller.provisioning.cloudprovider Discovered ami-050d93f2ea83da19d for query "/aws/service/eks/optimized-ami/1.23/amazon-linux-2/recommended/image_id" {"commit": "5d4ae35-dirty", "provisioner": "application-a-provisioner"}
2022-10-04T07:12:17.588Z DEBUG controller.provisioning.cloudprovider Created launch template, Karpenter-test-eks-1-4579713353214019755 {"commit": "5d4ae35-dirty", "provisioner": "application-a-provisioner"}
2022-10-04T07:12:20.650Z INFO controller.provisioning.cloudprovider Launched instance: i-035a7efc520610dc7, hostname: ip-10-1-4-148.us-west-2.compute.internal, type: m5.2xlarge, zone: us-west-2a, capacityType: on-demand {"commit": "5d4ae35-dirty", "provisioner": "application-a-provisioner"}左滑查看更多
利用 Gatekeeper 实现 namespace 级别的管控和注入
无论在3.1和3.2的实验中,实验中都是手动修改应用的 namespace 归属,以及对应的亲和性设置。那么从安全性和便利的角度来说,都不是一个好的实践,这时候可以引入 Gatekeeper 等 mutation webhook 工具,来使得部署在指定 namespaces 的容器必须具备特定的亲和性设置,从而完成自动匹配。此外,基于 namespace 级别设置了对应的 request 和 limit 限制,还需要对于未设置 request 和 limit 值的容器给予禁止部署。其具体的设置如下所示:
▌前提条件
安装 Gatekeeper
helm repo add gatekeeper https://open-policy-agent.github.io/gatekeeper/charts
helm install gatekeeper/gatekeeper --name-template=gatekeeper --namespace gatekeeper-system --create-namespace左滑查看更多
注意使用前记得更新 helm 的版本,否则会出现兼容性 bug。
查看状态:
[ec2-user@ip-10-1-1-239 blog]$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
gatekeeper-system gatekeeper-audit-66c58476d7-swq9q 1/1 Running 0 29m
gatekeeper-system gatekeeper-controller-manager-dcb9c7fff-nxmn6 1/1 Running 0 29m左滑查看更多
▌配置限制性 webhook,设定必须填写 Request 值才可进行部署
安装插件
kubectl apply -f https://raw.githubusercontent.com/open-policy-agent/gatekeeper-library/master/library/general/containerrequests/template.yaml
部署策略:
cat <<EOF | kubectl apply -f -
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sContainerRequests
metadata:
name: container-must-have-request
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Pod"]
parameters:
cpu: "2000m"
memory: "2Gi"
EOF左滑查看更多
其中限制了部署应用必须显示指定 request 值以及相应的最大值,否则部署出错。 接下来部署测试应用。
kubectl apply -f multi-tenant/yaml/nginx/nginx-dp-no-request.yaml
查看状态:
## 观察对应的ns无返回
$ kubectl get pods -n namespace-a
## 查看日志,发现请求被deny
$ kubectl logs gatekeeper-controller-manager-dcb9c7fff-nxmn6 -ngatekeeper-system
{"level":"info","ts":1664888600.9350498,"logger":"controller","msg":"constraint added to OPA","process":"constraint_controller","event_type":"constraint_added","constraint_group":"constraints.gatekeeper.sh","constraint_api_version":"v1beta1","constraint_kind":"K8sContainerRequests","constraint_name":"container-must-have-request","constraint_action":"deny","constraint_status":"enforced"}左滑查看更多
修改应用为有 request 值,在 multi-tenant/yaml/nginx/nginx-dp-no-request.yaml 最下方加入如下字段:
resources:
requests:
memory: "2048Mi"
cpu: "1500m"
limits:
memory: "2048Mi"
cpu: "1500m"重新部署,发现容器启动正常
[ec2-user@ip-10-1-1-239 blog]$ kubectl get pods -nnamespace-a
NAME READY STATUS RESTARTS AGE
nginx-deployment-no-request-6f7fdfd875-2f6kv 1/1 Running 0 14s左滑查看更多
▌设定 pod 自动注入亲和性设置的相关 webhook
部署 webhook
cat <<EOF | kubectl apply -f -
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: namespace-a-selector
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["namespace-a"]
location: "spec.nodeSelector"
parameters:
assign:
value:
app/team: "application-a"
EOF左滑查看更多
其中写明了,如果是部署在 namespace-a 的应用,那么会通过 webhook 注入如下的标签, 当然也可以注入其他选项,如 toleration 等。
nodeSelector
app/team: "application-a"部署应用:
## 发现除了三个跑在已有application-a-ng上的pod启动外,其他pod因为注入了selector无法调度
[ec2-user@ip-10-1-1-239 ~]$ kubectl get pods -nnamespace-a -owide
NAME READY STATUS RESTARTS AGE IP
namespace-a nginx-deployment-no-selector-6f7fdfd875-2n8hd 1/1 Running 0
namespace-a nginx-deployment-no-selector-6f7fdfd875-8fp5l 0/1 Pending 0
namespace-a nginx-deployment-no-selector-6f7fdfd875-8qv5g 1/1 Running 0
namespace-a nginx-deployment-no-selector-6f7fdfd875-b2xbm 0/1 Pending 0
namespace-a nginx-deployment-no-selector-6f7fdfd875-zk9hd 0/1 Pending 0左滑查看更多
查看 pod, 发现 selector 已经注入成功
[ec2-user@ip-10-1-1-239 ~]$ kubectl describe pods nginx-deployment-no-selector-6f7fdfd875-2n8hd -nnamespace-a
...
Node-Selectors: app/team=application-a
...左滑查看更多
稍等片刻,发现 pod 已经全部 ready,并且全部落在了 provioner-a 生成的新节点上。
## 前两个属于application-b-ng,
[ec2-user@ip-10-1-1-239 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-10-1-4-197.us-west-2.compute.internal Ready <none> 10h v1.23.9-eks-ba74326
ip-10-1-4-59.us-west-2.compute.internal Ready <none> 86s v1.23.9-eks-ba74326
ip-10-1-4-6.us-west-2.compute.internal Ready <none> 10h v1.23.9-eks-ba74326
ip-10-1-6-111.us-west-2.compute.internal Ready <none> 10h v1.23.9-eks-ba74326
ip-10-1-6-58.us-west-2.compute.internal Ready <none> 10h v1.23.9-eks-ba74326
[ec2-user@ip-10-1-1-239 ~]$ kubectl get pods -nnamespace-a -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-no-selector-6f7fdfd875-2n8hd 1/1 Running 0 5m10s 10.1.4.4 ip-10-1-4-197.us-west-2.compute.internal <none> <none>
nginx-deployment-no-selector-6f7fdfd875-8fp5l 1/1 Running 0 5m10s 10.1.4.114 ip-10-1-4-59.us-west-2.compute.internal <none> <none>
nginx-deployment-no-selector-6f7fdfd875-8qv5g 1/1 Running 0 5m10s 10.1.6.51 ip-10-1-6-58.us-west-2.compute.internal <none> <none>
nginx-deployment-no-selector-6f7fdfd875-b2xbm 1/1 Running 0 5m10s 10.1.4.228 ip-10-1-4-59.us-west-2.compute.internal <none> <none>
nginx-deployment-no-selector-6f7fdfd875-zk9hd 1/1 Running 0 5m10s 10.1.4.113 ip-10-1-4-59.us-west-2.compute.internal <none> <none>左滑查看更多
总结
通过以上的方案的展开,我们了解到了在单集群多 namespace 环境下实现租户之间资源隔离的几种常见划分和对应手段,其可以为客户在制定对应策略时提供基本的参考。
同时我们在与各位客户交流的过程中感受到并没有一概而论的方案去应对多租户场景下,应用到底应该是按集群级别进行隔离,还是 namespace 级别进行隔离。在过往的经历中,我们看到很多进入多租户深水区的客户往往采用了上述两种方式的结合,即他们通常会对 SLA 要求等级比较高的应用进行单集群的部署,SLA 相对较低的应用进行单集群 namespace 级别的隔离。所以采用哪种方式取决于客户当前所属的阶段、应用的大小和多少,以及相关应用 SLA 的要求等。我们通常建议客户刚起步时,可以基于单集群多 namespace 的形态进行划分,然后再进行逐步的演进。
最后,附上相关内容的简要总结:
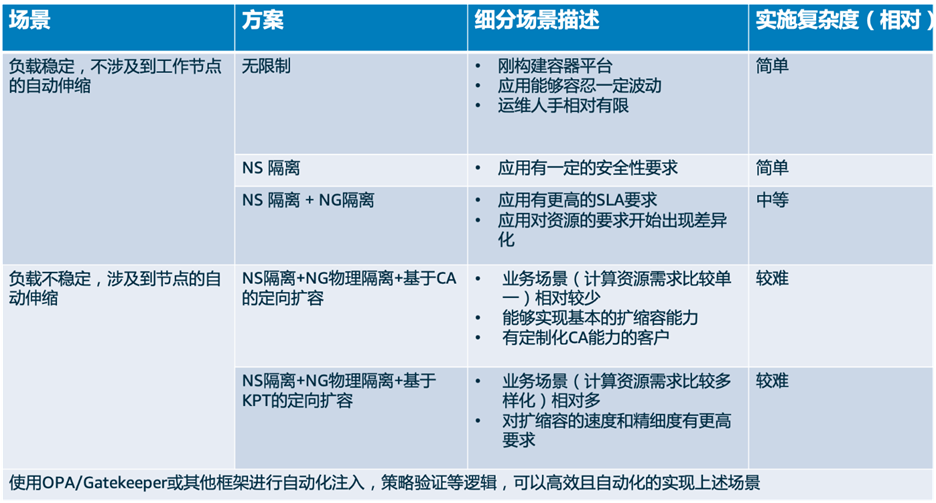
上图缩写说明
● NS: namespace
● NG: nodegroup
● KPT: karpenter
● CA: cluster autoscaler
在后续的文章中,我们将会从网络,存储,以及框架等方面展开近一步的探讨。
参考文档
EKS enhancement:
https://aws.amazon.com/cn/blogs/containers/amazon-eks-control-plane-auto-scaling-enhancements-improve-speed-by-4x/
Cluster Autoscaler:
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#what-are-expanders
Karpenter:
https://karpenter.sh/v0.16.3/tasks/scheduling/
Gatekeeper:
https://github.com/open-policy-agent/gatekeeper
本篇作者

尹振宇
亚马逊云科技解决方案架构师,负责基于亚马逊云科技云平台的解决方案咨询和设计,尤其在无服务器领域和微服务领域有着丰富的实践经验。

听说,点完下面4个按钮
就不会碰到bug了!
















 8882
8882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









