







背景介绍
Amazon EKS 是一项全托管的 Kubernetes 服务,可帮助您轻松地在 Amazon 上运行 Kubernetes 应用程序。在 EKS 中,Amazon Load Balancer Controller 是一种 Kubernetes 控制器,监视 Services 或 Ingress 资源,用于创建和管理 Network Load Balancer (NLB) 和 Application Load Balancer (ALB)。
通常在 Kubernetes 场景下,为实现应用新版本的零停机升级,会采用多副本部署,并在升级时使用 Rolling Update 策略,保证在旧的容器实例被终止前,有新的实例被创建来为后续的新请求服务。同时使用 Readiness 探针机制来确认只有 Pod 中的应用已经就绪时才加入到前端 Service 的 Endpoints 列表中,从而正常接受请求输入。
在使用 Amazon 托管的 EKS 和 Amazon Load Balancer Controller 时,除将 Pod 加入到Services 的 Endpoints 列表中,还需通过 Instance 或者 IP 模式将 NodePort 或者 Pod 注册成为负载均衡器的目标。使用 Instance 模式时请求流量进入负载均衡器后先转发至节点 NodePort 然后抵达 Pod,而 IP 模式时请求流量进入负载均衡器后即转发至 Pod 中,IP 模式减少了一层流量转发因此更多的被采用。
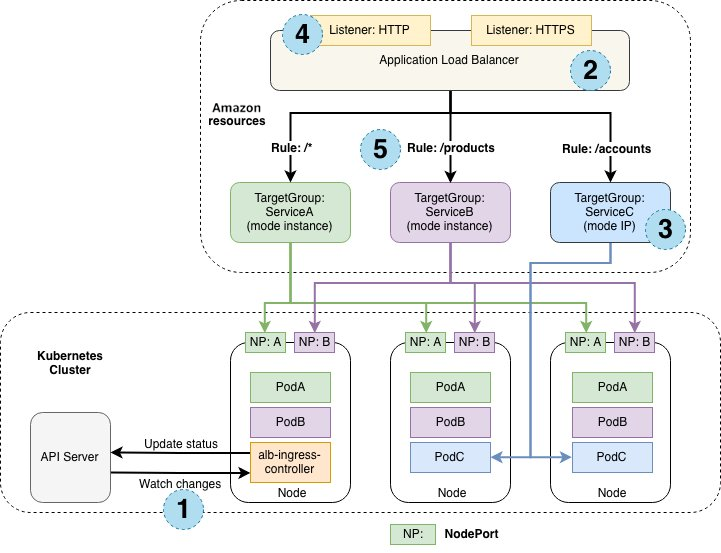
除了 Instance 模式和 IP 模式下的流量路径不同,负载均衡器的目标类型不同也会给应用升级带来不同的影响。
当采用 Instance 模式注册目标,如果不涉及到新旧节点的更换,NLB / ALB 目标组中的目标不会发生变化,NodePort 服务类型下请求会通过 Iptables / IPVS 的方式转发到相应的 Pod,此时实现 Deployment 级别的无停机更新即可。
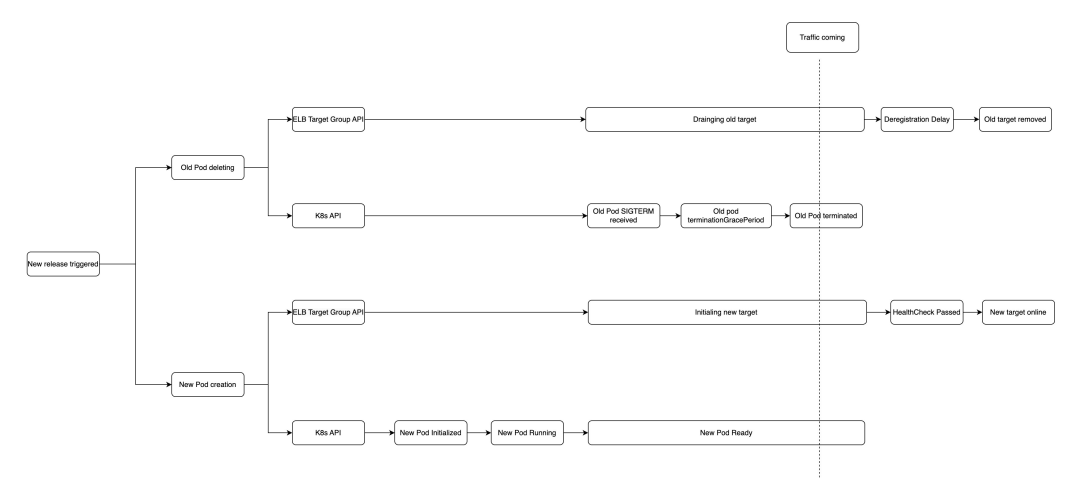
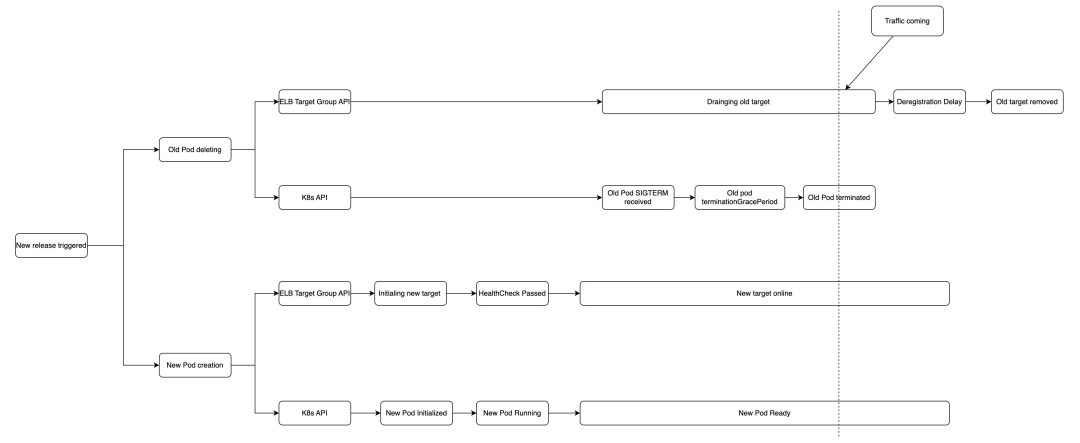
当采用 IP 模式注册目标,更新时 NLB / ALB 目标组需删除原有 Pod 并加入新的 Pod 目标,此时 EKS 的应用更新会涉及到 ELB Target Group 和 K8s API 的调用且这两个调用是异步的,ELB 目标和 Pod 处在的不同状态及其时间长短会对流量的处理带来不同的结果,因此极有可能会引入中断。整体的处理流程可参考下图:
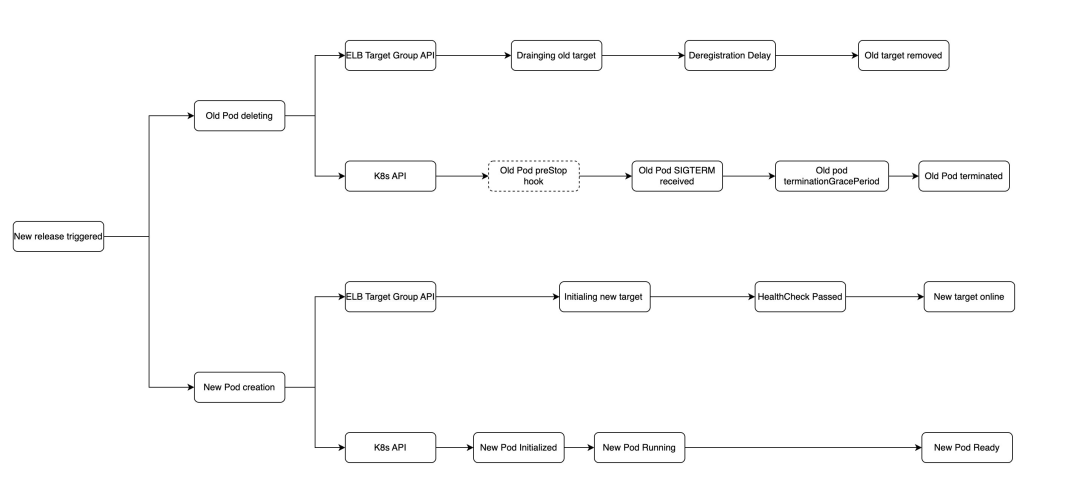
上图可见应用升级的过程中,Pod 和负载均衡器目标的会分别经历不同的状态,其中 Pod 的启停时间由于工作负载内容各不相同也有所差异。为实现应用的零停机升级,需要充分测试并了解处在不同阶段的 Pod 和负载均衡器目标所带来的影响。
本文目的
本文将以 ALB + IP 模式实现服务暴露为例,逐步测试和分析 EKS 应用升级中遇到的 50x 问题,并采取相应的方案以最终实现应用零停机升级。
环境准备
为方便复现测试场景,本文采用官方发布的 EKS workshop 环境和 game 2048(请根据 API 版本调整相应的 YAML 文件字段,文中实验为方便观察将默认 replicas 数目由默认的 5 减少至 2 )应用作为示例,此外根据文档开启 ALB 日志。
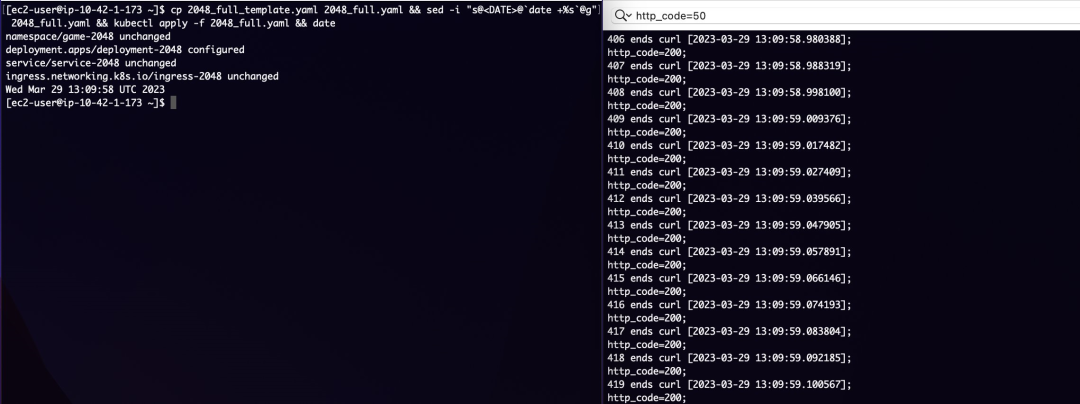
首先将官方 game 2048 Yaml 文件中的 Deployment 添加 date 注解并保存为 2048_full_template.yaml 文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-2048
namespace: game-2048
spec:
selector:
matchLabels:
app: app-2048
replicas: 2
template:
metadata:
labels:
app: app-2048
annotations:
date: "<DATE>"使用如下命令实现通过改变 date 的简单更新部署并显示当前时间以做观察:
cp 2048_full_template.yaml 2048_full.yaml && \
sed -i "s@<DATE>@`date +%s`@g" 2048_full.yaml && \
kubectl apply -f 2048_full.yaml && \
date左滑查看更多
初次部署 game 2048 应用后,如下图所示在 EC2 控制台中找到相应的目标组获得其 ARN:
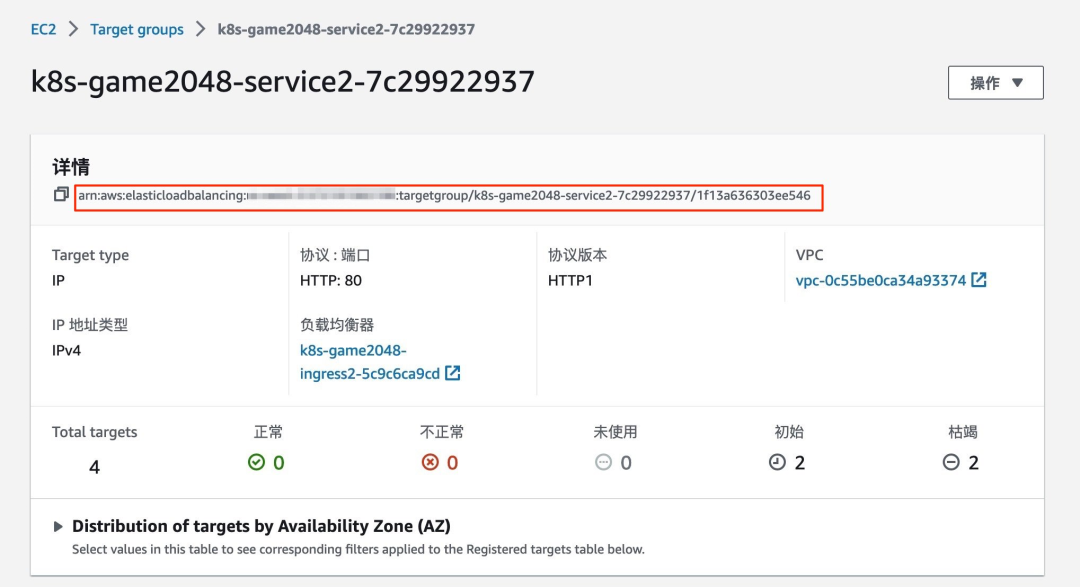
并通过以下命令获取 ALB URL:
kubectl get ingress/ingress-2048 -n game-2048NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-2048 <none> * k8s-game2048-ingress2-xxxxxxxxxx-yyyyyyyyyy.region-code.elb.amazonaws.com 80 2m32s左滑查看更多
根据以上信息编写测试脚本 aws_alb_test_2048.sh ,此测试脚本将持续获得应用 Pod 和 ALB 目标组状态,并返回对 game 2048 的 curl 请求结果。
#!/bin/bash
for i in {1..999};
do
echo "$i starts kube pod" $(date "+[%Y-%m-%d %H:%M:%S.%6N]") \;
kubectl get pods --selector=app.kubernetes.io/name=app-2048 -o wide -n game-2048;
aws elbv2 describe-target-health \
--target-group-arn arn:aws:elasticloadbalancing:region-code:xxxxxxx:targetgroup/k8s-game2048-service2-xxxxxxx/xxxxxxx;
echo "$i starts curl " $(date "+[%Y-%m-%d %H:%M:%S.%6N]") \;
curl -s -o /dev/null -w "http_code=%{http_code}" https://k8s-game2048-ingress2-xxxxxxxxxx-yyyyyyyyyy.region-code.elb.amazonaws.com/;
echo \;
echo "$i ends curl" `date "+[%Y-%m-%d %H:%M:%S.%6N]"`\;
done左滑查看更多
应用更新的同时在新的终端窗口运行上述脚本监控应用状态:
sh aws_alb_test_2048.sh测试一:
使用多副本、滚动升级 和 Readiness 探针
根据前文所提到的通常在 Kubernetes 场景下的零停机更新方法,将 2048_full_template.yaml 文件中 deployment 配置为 2 replicas ,采用默认的 Rolling Update 更新策略,并添加 Readiness 探针。
spec:
containers:
- image: public.ecr.aws/l6m2t8p7/docker-2048:latest
imagePullPolicy: Always
name: app-2048
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10左滑查看更多
更新 game-2048 部署并执行 aws_alb_test_2048.sh 监测应用状态,观察到更新过程中至少有一个 Pod 处于 running 状态:
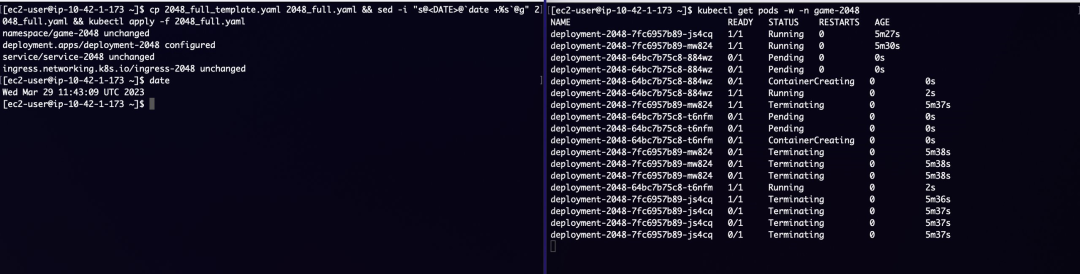
而在执行 aws_alb_test_2048.sh 脚本的终端窗口中除正常返回 200 的 http_code,如下图所示存在某时刻两个新 Pod 处于 running 状态,而目标组中四个 Target 皆处于 registration 和 deregistration 的过程中,game-2048 服务返回 http_code=504。
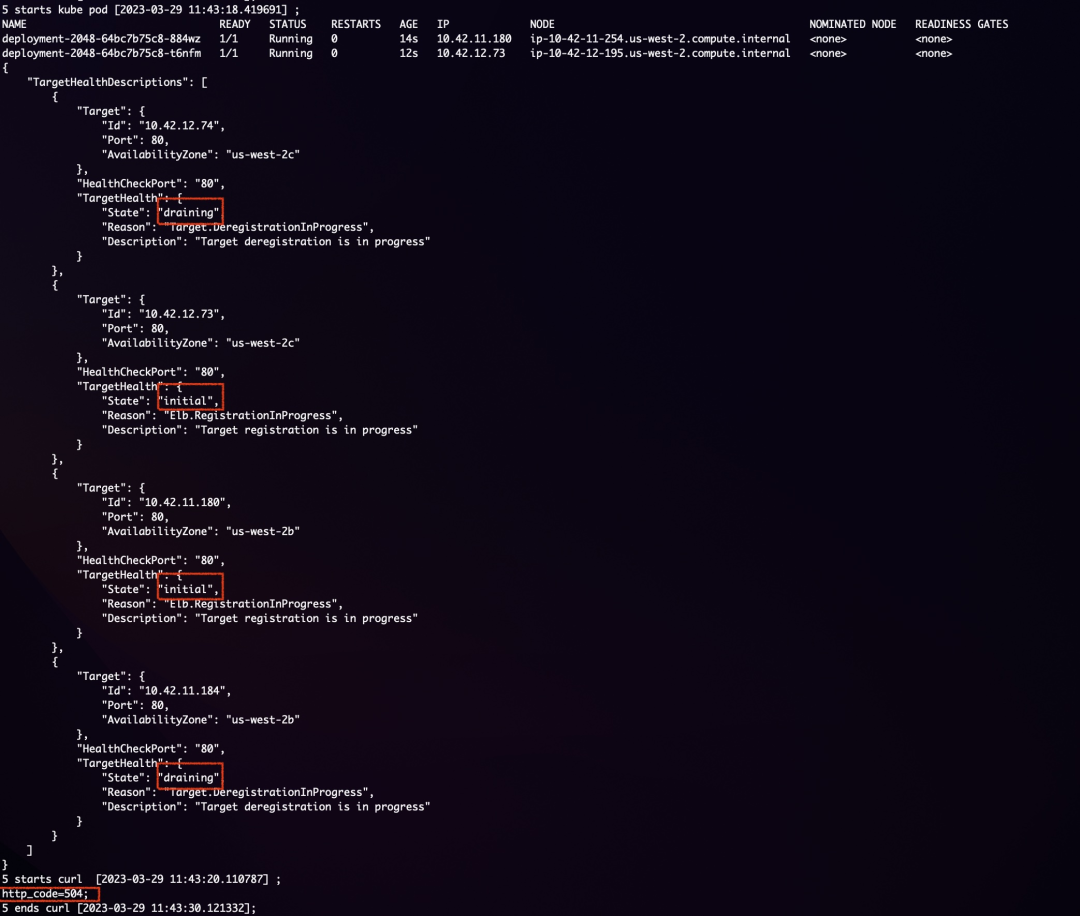
此时如在控制台观察 ALB 目标组,会发现目标组中并无任何 healthy 状态的目标。
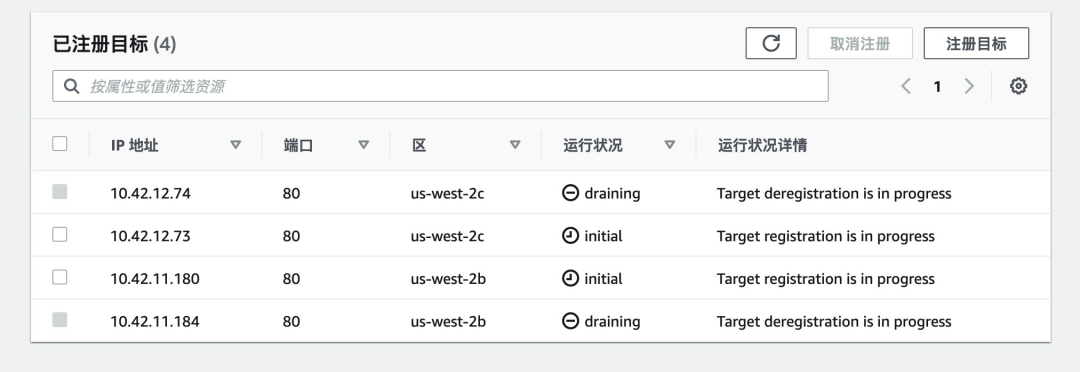
如上所述,即使采用了滚动升级和 Readiness 探针,ALB 目标组的健康检查状态并没有和 Pod 的生命周期联动,旧的 Pod 已经 terminated,处于 running 状态的新 Pod 在 ALB 中的目标状态不是 healthy 无法接受请求,导致响应状态码为 504。
测试二:
使用多副本、滚动升级和 Amazon Load Balancer Controller Pod Readiness Gate
Amazon Load Balancer Controller Pod Readiness Gate 可通过 EKS 持续监控 ELB 目标状态,直到其状态为 healthy 才认为 Pod 已经就绪,将 READNIESS GATES 设为 1 。
启用 Pod Readiness Gate 并更新应用后,可查看 Pod 的 STATUS 和 READNIESS GATES 的两个状态。


此时再次更新 game-2048 部署并执行 aws_alb_test_2048.sh 监测应用状态,控制台中 ALB 目标组未出现所有目标不健康的状况,可见 pod_readiness_gate 保证了目标组在有新的目标注册且 healthy 后才会取消注册旧目标。
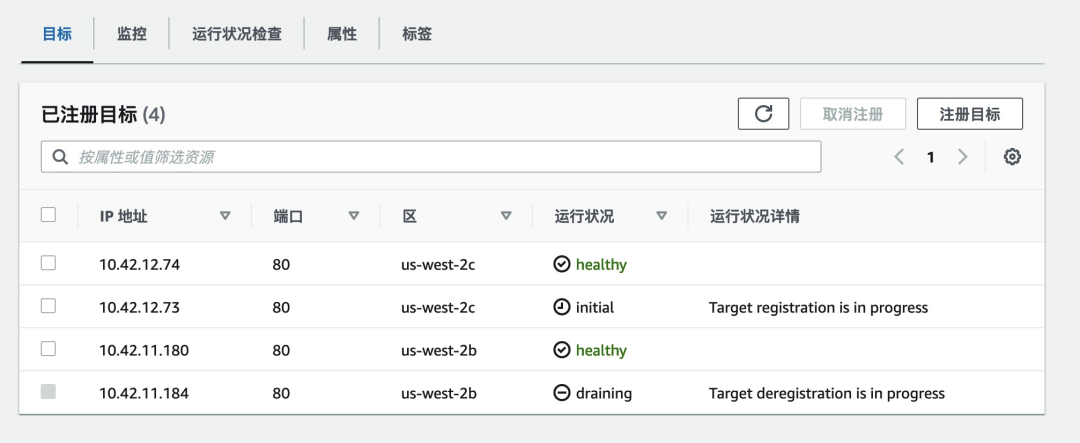
但在应用状态监测的终端中仍然出现了 http_code=504,如下图所示,新的 Pod 处于 running 状态且目标状态为 healthy,旧的 Pod 已删除而其目标仍处在取消注册进度中。

查看 ALB 日志可发现此时的请求转发给了正在 draining 的目标:
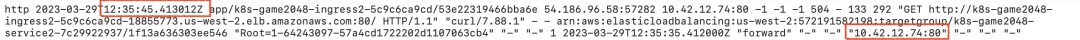
点击查看大图
由此可见,在新的目标处于 healthy 状态时,旧的处于 draining 状态的目标仍有可能接受请求,根据 Deregistration delay 描述 Pod 终止过快时客户端会收到 50x 响应,正如此次测试的结果。
博客提及的测试场景中 Pod Readiness Gate 解决了服务中断问题,而在上述测试中 Pod Readiness Gate 虽然保证了 ALB 中至少有一个 healthy 的目标,但并未能完全解决服务升级中断问题,由此可推测其效果也取决于应用服务本身如 Pod 终止速度及其他因素。
测试三:
使用多副本、滚动升级和 Amazon Load Balancer Controller Pod Readiness Gate、Prestop hook
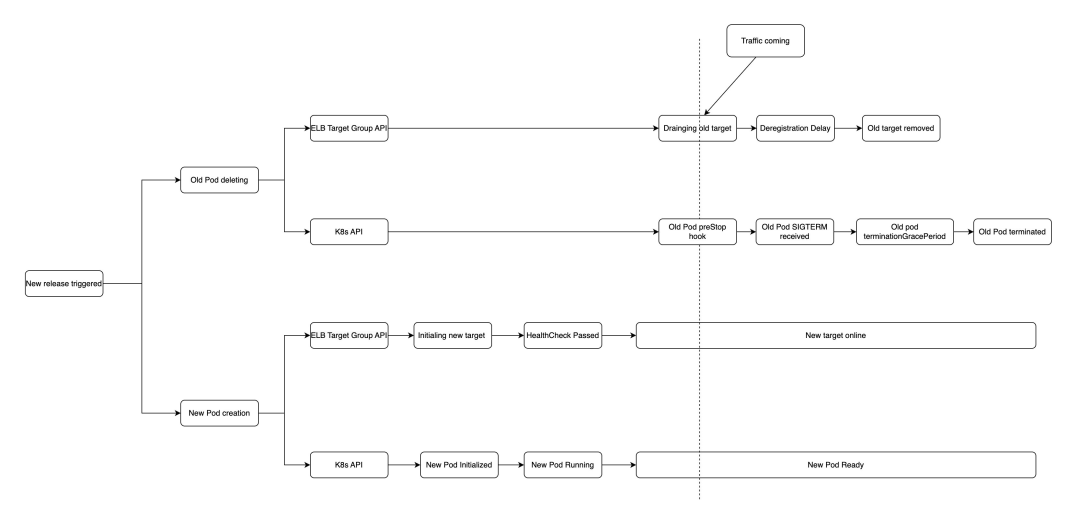
为解决测试二中的问题引入 pre-stop hook 延长 pod terminating 的时间,确保在目标 draining 结束前旧 Pod 不被彻底移除以处理完遗留请求。
在 2048_full_template.yaml 文件中添加 prestop hook,根据上述测试结果请求返回504的整个时间段不长,设置 sleep 20s 即可保证目标 draining 完成前旧 Pod 可继续处理请求。
spec:
containers:
- image: public.ecr.aws/l6m2t8p7/docker-2048:latest
imagePullPolicy: Always
name: app-2048
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 20"]左滑查看更多
更新 game-2048 部署并执行 aws_alb_test_2048.sh 监测应用状态,可发现此次测试中并未收到 http_code=200 以外的响应。
此时请求如果传给新的 healthy 的目标可正确处理,传给旧的目标时 Pod 尚未终止也可正确处理流量。
此外,笔者在相同环境下做了以下测试:
ALB 结合 Ingress 对外暴露应用时,以 Instance 模式注册 NodePort 为 ALB 目标,仅配置滚动升级,应用更新过程中持续 curl 请求的响应状态码皆为 200;
NLB 结合 Services 对外暴露应用时,以 IP 模式注册 Pod 为 NLB 目标,测试结果与 ALB 类似,区别在于 curl 请求暂停响应而不是返回 504 响应状态码;
NLB 结合 Services 对外暴露应用时,以 Instance 模式注册 NodePort 为 NLB 目标,仅配置滚动升级,应用更新过程中持续 curl 请求的响应状态码也皆为 200。
测试过程此文省略。
结论
基于以上测试结果,正如开篇针对 NLB / ALB 的目标生命周期管理的分析,采用 IP 模式注册 Pod 目标时应用更新会产生 50x 问题,此时建议使用 Pod Readiness Gate 关联 ELB 目标状态和 Pod 生命周期以减少服务中断的发生,如若仍不能解决 50x,可根据应用处理请求的时长和 Pod 终止的速度选择设置 pre-stop hook。
最后,请关注 terminationGracePeriodSeconds,Deregistration delay,Connection Idle Timeout 等参数数值大小关系以实现 EKS 环境下的应用零停机升级。
本篇作者

杜晨曦
亚马逊云科技解决方案架构师,负责基于亚马逊云计算方案架构的咨询和设计,在国内推广亚马逊云平台技术和各种解决方案。
2023亚马逊云科技中国峰会即将开启!
👇👇👇点击下方图片即刻注册👇👇👇


听说,点完下面4个按钮
就不会碰到bug了!
















 8786
8786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









