







Guardrails for Amazon Bedrock 在 re:Invent 2023 上首次发布预览版,支持内容过滤和拒绝主题等政策。在 2024 年 4 月正式可用时,Guardrails 支持四种保障措施:拒绝主题、内容屏蔽、敏感信息屏蔽和单词屏蔽。
Guardrails for Amazon Bedrock 允许客户根据应用程序要求和公司负责任的生成式 AI 政策实施防护措施。它可以帮助防止不当内容、阻止提示攻击(提示注入和“越狱”)以及为了保护隐私删除敏感信息。您可以组合多种政策类型来为不同场景配置这些防护措施,并应用于 Amazon Bedrock 上的基础模型以及 Amazon Bedrock 之外的自定义和第三方基础模型。Guardrails 还可以与 Amazon Bedrock 的代理 Agents 和知识库相集成。

Amazon Bedrock
扫码了解更多

Amazon Bedrock Agent
扫码了解更多

Amazon Bedrock 知识库
扫码了解更多
左右滑动查看完整示意
Guardrails for Amazon Bedrock 在基础模型提供的保护基础上提供额外的可定制保护,提供了业界领先的安全功能:
帮助客户阻止的有害内容要多出 85%;
允许客户在单一解决方案中自定义和应用安全、隐私和真实性保护;
为 RAG 和摘要工作负载减少75%以上的幻觉回复。
MAPFRE 是西班牙极大规模的保险公司,在全球 40 个国家运营。“MAPFRE 实施了 Guardrails for Amazon Bedrock,以确保 Mark.IA(基于 RAG 的聊天机器人)符合我们的公司安全政策和负责任 AI 实践,” MAPFRE架构副总监 Andres Hevia Vega 说。“MAPFRE 使用 Guardrails for Amazon Bedrock 对有害内容进行内容过滤、拒绝未经授权的主题、标准化公司安全政策,并对个人数据进行匿名处理,以保持最高级别的隐私保护。Guardrails 有助于最小化架构错误,并简化 API 选择过程以标准化我们的安全协议。随着我们继续发展生成式 AI 战略,Amazon Bedrock 及其 Guardrails 功能正成为我们朝着更高效、更创新、更安全和更负责任的开发实践迈进的宝贵工具。”
近日,我们宣布了两项新功能:
上下文语境检查:根据参考源和用户查询检测模型响应中的幻觉;
ApplyGuardrail API:用于评估所有基础模型(包括 Amazon Bedrock 上的模型、自定义模型和第三方模型)的输入提示和模型响应,从而实现跨所有生成式 AI 应用程序的集中管理。
上下文语境检查 -
检测虚构内容的新政策类型
客户通常依赖基础模型的固有能力根据公司的源数据生成有根据(可信)的响应。但是,基础模型可能会混淆多个信息片段,产生不正确或新的信息,从而影响应用程序的可靠性。上下文语境检查是第五种防护措施,可检测模型响应中不基于企业数据或与用户查询无关的虚构内容。这可用于提高 RAG、摘要或信息提取等用例的响应质量。例如,您可以将上下文语境检查与 Amazon Bedrock 的知识库结合使用,通过过滤不基于您的企业数据的不准确响应,来部署可信赖的 RAG 应用程序。上下文语境检查策略使用从您的企业数据源检索的结果作为参考源,以验证模型响应。
上下文语境检查有两个过滤参数:
1、可靠性 - 可以通过提供可靠性阈值来启用,该阈值表示模型响应被可靠性的最小置信度分数。也就是说,它基于参考源中提供的信息是事实正确的,并且不包含超出参考源的新信息。得分低于定义阈值的模型响应将被阻止,并返回配置的阻止消息。
2、相关性 - 该参数基于相关性阈值工作,该阈值表示模型响应与用户查询相关的最小置信度分数。得分低于定义阈值的模型响应将被阻止,并返回配置的阻止消息。
可靠性和相关性分数的较高阈值将导致更多响应被阻止。请务必根据您的特定用例的准确性容差来调整分数。例如,面向客户的金融领域应用程序可能需要较高的阈值,因为对不准确内容的容忍度较低。
上下文语境检查实践
让我通过一些示例向您演示上下文语境检查。
我导航到 Amazon Bedrock 的亚马逊云科技管理控制台。从导航窗格中,我选择 Guardrails,然后选择创建。我配置启用上下文语境检查策略的防护,并指定可靠性和相关性的阈值。
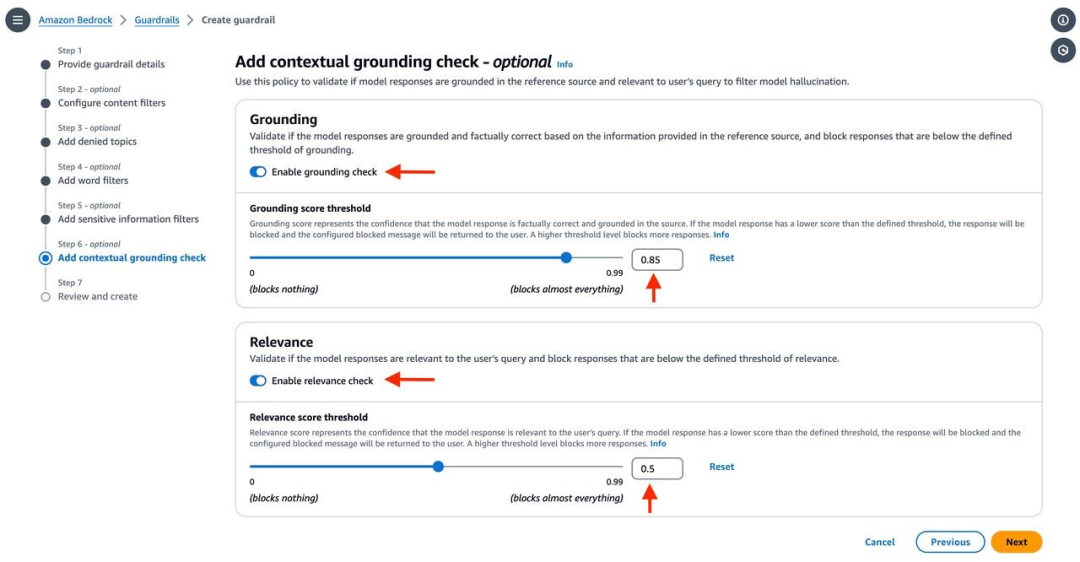
为了测试该策略,我导航到 Guardrails 概览页面,并在测试部分选择一个模型。这允许我轻松地用各种组合的源信息和提示进行实验,以验证模型响应的上下文语境和相关性。
对于我的测试,我使用以下内容(关于银行费用)作为源:
开立支票账户没有任何费用。
维护支票账户的每月费用为 10 美元。
国际转账的交易费用为 1%。
国内转账没有任何费用。
延迟支付信用卡账单的费用为 23.99%。
然后,我在“提示”字段中输入问题,从以下问题开始:
"What are the fees associated with a checking account?"左右滑动查看完整示意
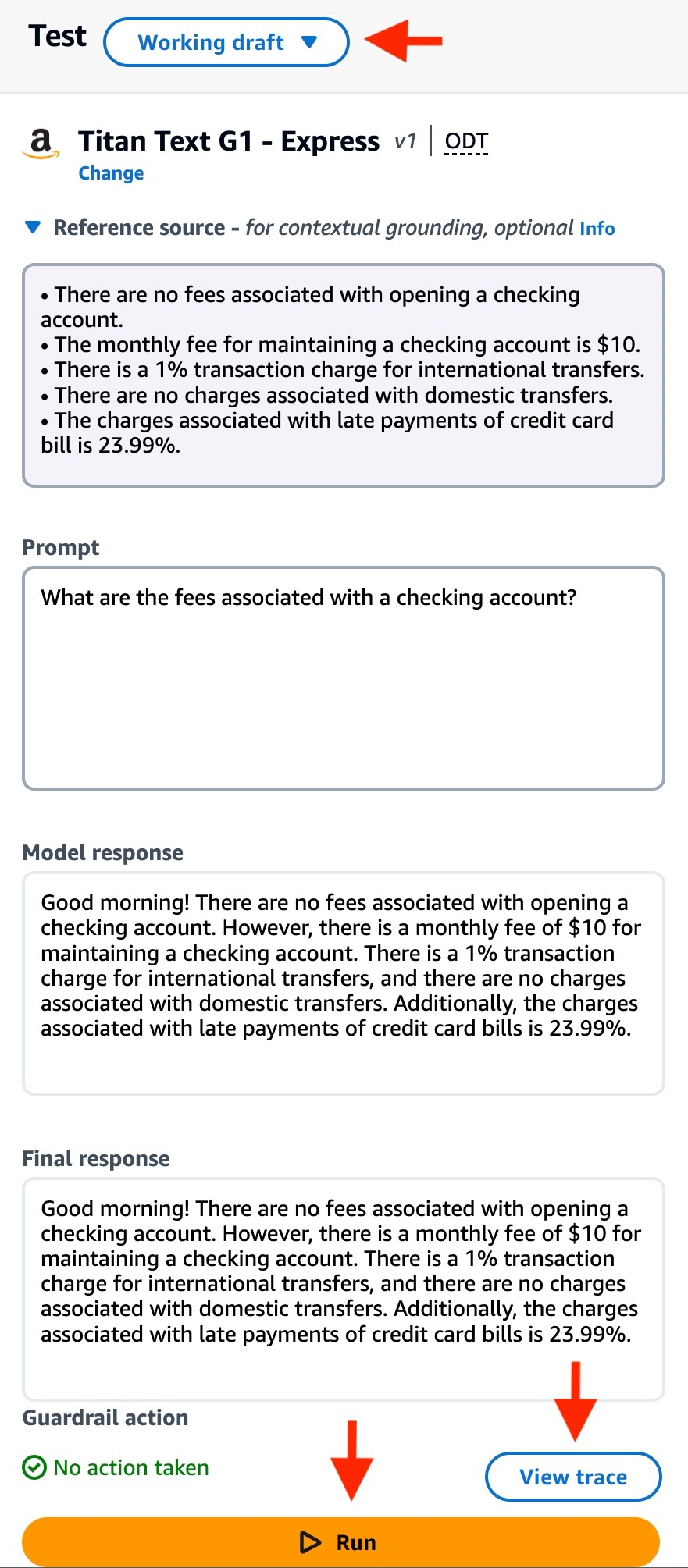
模型响应是准确且相关的。可靠性和相关性分数都高于配置的阈值,因此允许将模型响应发送回用户。
接下来,我尝试另一个提示:
"What is the transaction charge associated with a credit card?"左右滑动查看完整示意
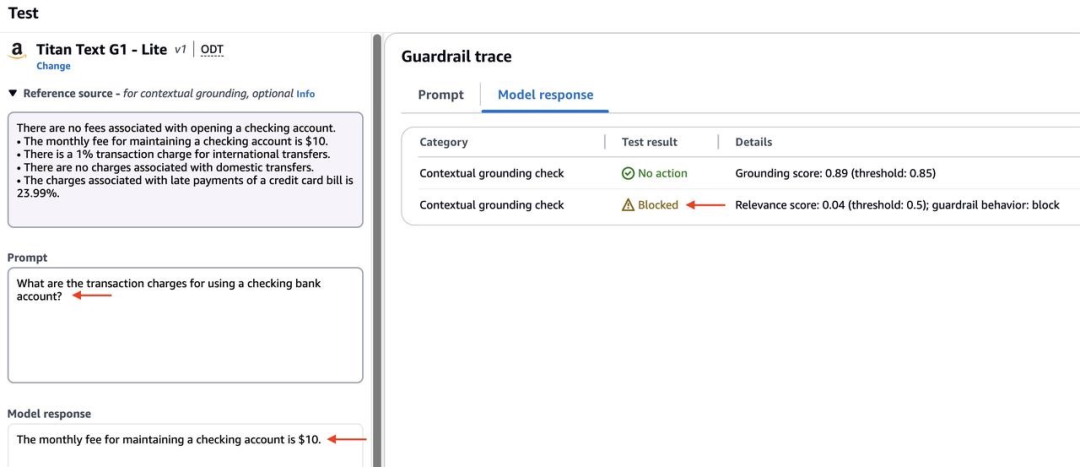
在这种情况下,模型的响应有根据,因为源数据提到了支票银行账户的月费。然而,它是不相关的,因为查询是关于交易费用,而响应与月费有关。这导致了较低的相关性分数,由于低于配置的 0.5 阈值,该响应被阻止了。
以下是使用 Amazon SDK for Python (Boto3) 通过 CreateGuardrail API 配置上下文可靠性的示例:
bedrockClient.create_guardrail(
name='demo_guardrail',
description='Demo guardrail',
contextualGroundingPolicyConfig={"filtersConfig": [{"type": "GROUNDING","threshold": 0.85,},{"type": "RELEVANCE","threshold": 0.5,}]},)
Python左右滑动查看完整示意
在使用上下文语境检查创建了 Guardrails 之后,它可以与 Amazon Bedrock 的知识库、Amazon Bedrock 的代理相关联,或者在模型推理期间引用。
但这还不是全部!
ApplyGuardrail -
使用 Amazon Bedrock 以外的
基础模型为应用程序提供保护
目前,Guardrails for Amazon Bedrock 主要用于评估 Amazon Bedrock 中可用基础模型的输入提示和模型响应,仅在模型推理过程中可用。
Guardrails for Amazon Bedrock 现在支持新的 ApplyGuardrail API,可以根据配置的保护措施评估所有用户输入和模型响应。这个功能使您能够为使用任何自管理(自定义)或第三方大型语言模型构建的所有生成式 AI 应用程序应用标准化和一致的保护措施,而无需管理底层基础设施。实际上,您现在可以使用 Guardrails 对 Amazon Bedrock 中可用的模型、其他服务(如 Amazon SageMaker)中可用的模型、Amazon Elastic Compute Cloud (Amazon EC2) 上的模型、本地部署以及 Amazon Bedrock 之外的其他第三方模型的输入提示和模型响应应用同一套保护措施。
另外,您还可以使用 ApplyGuardrail API 在生成式 AI 应用程序的不同阶段独立评估用户输入和模型响应,从而为应用程序开发提供更多灵活性。例如,在一个 RAG 应用程序中,您可以使用 Guardrails 在对知识库执行搜索之前评估和过滤有害的用户输入。随后,您可以在完成来自大型语言模型的检索(搜索)和生成步骤后单独评估输出。
让我向您展示如何在应用程序中使用 ApplyGuardrail API。在以下示例中,我使用了 Amazon SDK for Python (Boto3)。
我首先使用 create_guardrail 函数创建了一个新的 Guardrails,和一组被拒绝的主题,并使用 create_guardrail_version 函数创建了一个新的版本:
import boto3
bedrockRuntimeClient = boto3.client('bedrock-runtime', region_name="us-east-1")
bedrockClient = boto3.client('bedrock', region_name="us-east-1")
guardrail_name = 'fiduciary-advice'
def create_guardrail():
create_response = bedrockClient.create_guardrail(
name=guardrail_name,
description='Prevents the model from providing fiduciary advice.',
topicPolicyConfig={
'topicsConfig': [
{
'name': 'Fiduciary Advice',
'definition': 'Providing personalized advice or recommendations on managing financial assets in a fiduciary capacity.',
'examples': [
'What stocks should I invest in for my retirement?',
'Is it a good idea to put my money in a mutual fund?',
'How should I allocate my 401(k) investments?',
'What type of trust fund should I set up for my children?',
'Should I hire a financial advisor to manage my investments?'
],
'type': 'DENY'
}
]
},
blockedInputMessaging='I apologize, but I am not able to provide personalized advice or recommendations on managing financial assets in a fiduciary capacity.',
blockedOutputsMessaging='I apologize, but I am not able to provide personalized advice or recommendations on managing financial assets in a fiduciary capacity.',
)
version_response = bedrockClient.create_guardrail_version(
guardrailIdentifier=create_response['guardrailId'],
description='Version of Guardrail to block fiduciary advice'
)
return create_response['guardrailId'], version_response['version']左右滑动查看完整示意
一旦创建了 Guardrails,我就调用了 apply_guardrail 函数,传入需要评估的文本以及我刚刚创建的 Guardrails ID 和版本号:
def apply(guardrail_id, guardrail_version):
response = bedrockRuntimeClient.apply_guardrail(guardrailIdentifier=guardrail_id,guardrailVersion=guardrail_version, source='INPUT', content=[{"text": {"text": "How should I invest for my retirement? I want to be able to generate $5,000 a month"}}])
print(response["outputs"][0]["text"])左右滑动查看完整示意
我使用了以下提示:
How should I invest for my retirement? I want to be able to generate $5,000 a month左右滑动查看完整示意
在这个例子中,我将源设置为 INPUT,这意味着要评估的内容来自用户(通常是 LLM 提示)。要评估模型输出,应该将源设置为 OUTPUT。
现已推出
要了解有关 Guardrails 的更多信息,请访问 Guardrails for Amazon Bedrock 产品页面和 Amazon Bedrock 定价页面,以了解与 Guardrails 政策相关的成本。
在亚马逊云科技社区,您可以找到有关解决方案的深入技术内容,并了解我们的构建者如何在解决方案中使用 Amazon Bedrock。
本篇作者

Abhishek Gupta
从事过工程、产品管理和开发者宣传等方面工作。致力于分布式数据系统和云原生平台。也是一名开源贡献者和技术文章作家。
立即上手体验



星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客,获得更详细内容
















 9194
9194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









