







在当今竞争激烈的游戏行业,玩家的需求和反馈是无价之宝。通过深入分析玩家在游戏内及社交平台上的聊天内容,运营团队可以洞悉玩家的真实体验,发现潜在的需求和痛点,从而制定更有针对性的策略,提升游戏体验和运营效率。作为一种新兴的人工智能技术,生成式 AI 在自然语言处理领域展现出了巨大的潜力。通过对海量文本数据进行智能分析和建模,生成式 AI 可以自动总结出主题、情感和潜在需求等关键信息,为游戏运营提供前所未有的洞见。
本文将详细介绍如何利用生成式 AI 分析玩家聊天内容,为游戏运营提供强大的舆情分析支持。无论是发现热点话题、分析情感趋势,还是挖掘新的游戏需求,生成式 AI 都将助您一臂之力。让我们一同探索这项前沿技术如何为游戏运营注入新的动力,与玩家建立更紧密的联系。在本文中我们会一起构建一套端到端的解决方案,通过该解决方案,我们会针对某些游戏内关键词(比如游戏道具),获取玩家在聊天过程中的反馈。
方案介绍
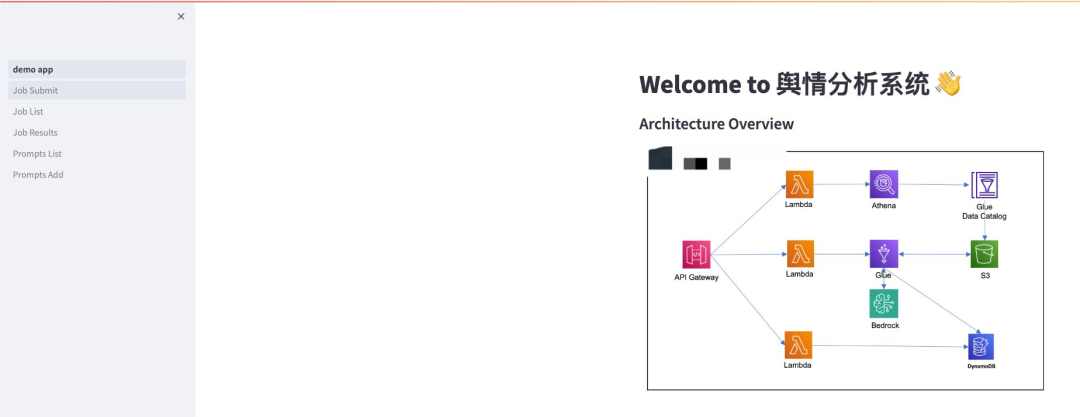
方案架构图如下所示:
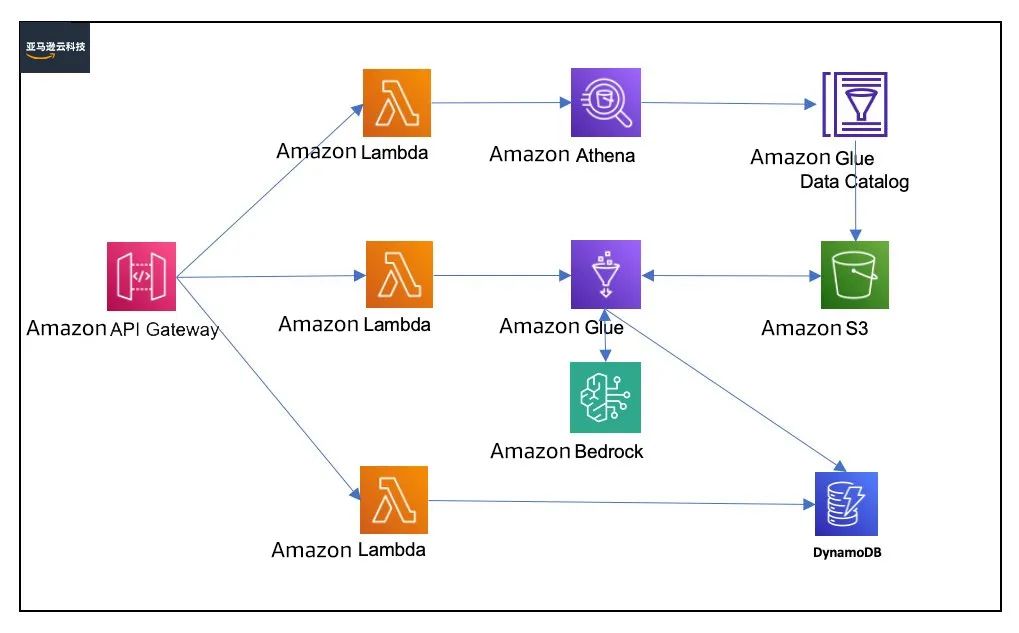
该方案中通过 Serverless 的架构结合 Amazon Bedrock 来实现端到端的 API 调用实现,其中 Amazon Bedrock 提供了方便快捷的 API call 的方式将大语言模型的调用进行封装,大大降低客户对于生成式 AI 的入门门槛。几个比较关键的服务介绍如下——
Amazon Athena:一项基于开源框架的无服务器交互式分析服务,支持开源表和文件格式。Athena 提供了一种简化、灵活的方法来分析包含它的 PB 级数据。从 Amazon Simple Storage Service(S3)数据湖和超过 30 个数据来源(包括本地数据来源,或使用 SQL 或 Python 的其他云系统)分析数据或构建应用程序。Athena 基于开源 Trino 和 Presto 引擎以及 Apache Spark 框架构建,无需进行预配或配置。
Amazon Glue:一项无服务器数据集成服务,它简化了发现、准备、移动和集成来自多个来源的数据以进行分析、机器学习(ML)和应用程序开发的工作。在本方案中,我们主要使用 Glue 来从 S3 中提取聊天记录后,通过调用 Bedrock 的 API 来实现对聊天记录针对游戏内部关键字的抽取和语义分析。
Amazon Bedrock:一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 生成式 AI 构建生成式 AI 应用程序所需的一系列广泛功能,在本示例中我们会使用 Amazon Bedrock 及其提供的大语言模型对聊天记录进行语义解析。
Amazon DynamoDB:无服务器、NoSQL、完全托管的数据库,在任何规模下均具有个位数毫秒级的性能,在本案例中我们使用 DynamoDB 来存储提示词相关的信息。
Langchain:一个开源框架,用于构建基于大型语言模型(LLM)的应用程序。LLM 是基于大量数据预先训练的大型深度学习模型,可以生成对用户查询的响应,在本案例中我们使用 Langchain 来实现对于在不同条件下 chain 的封装以及对于输入输出内容的格式化调整。
Streamlit: 一个开源的 Python 库,它可以轻松创建和共享漂亮、定制的网络应用程序,用于机器学习和数据科学领域。仅需几分钟,您就可以构建和部署功能强大的数据应用程序。本案例中,为了方便我们更好地演示方案的端到端的能力,我们会使用 Streamlit 来做一个简化的前端页面配合方案。
方案部署
整套解决方案使用 Amazon CDK 进行部署,所以需要在本地具备以下环境:
安装依赖
1.安装 nodejs 18。
sudo yum install https://rpm.nodesource.com/pub_18.x/nodistro/repo/nodesource-release-nodistro-1.noarch.rpm -y
sudo yum install nodejs -y --setopt=nodesource-nodejs.module_hotfixes=1 --nogpgcheck左右滑动查看更多
2.安装 & 启动 docker。
sudo yum install docker -y
sudo service docker start
sudo chmod 666 /var/run/docker.sock3.安装 git 和 jq。
sudo yum install git -y
sudo yum install jq左右滑动查看更多
4.安装 aws-cdk。
sudo npm install -g aws-cdk
sudo npm install --global yarn左右滑动查看更多
5.安装 Python3.11(Amazon Linux 2023 自带 python3.11 环境),其他系统可以参考以下安装方式。
wget https://www.python.org/ftp/python/3.11.8/Python-3.11.8.tgz
tar xzf Python-3.11.8.tgz
cd Python-3.11.8
sudo ./configure --enable-optimizations左右滑动查看更多
6.安装依赖后,依赖信息如下。
CDK 2.122.0+
nodejs 18+
npm 10+
python 3.11+
git左右滑动查看更多
开始部署
首先我们需要将示例代码下载到本地。
git clone https://github.com/myawsdemo/llm-text-keyword-summary.git
cd llm-text-keyword-summary/deploy左右滑动查看更多
执行生成环境变量脚本,生成相应环境变量,脚本内容如下。
#!/bin/bash
account_id=`aws sts get-caller-identity --query "Account" --output text`
ts=`date +%y-%m-%d-%H-%M-%S`
unique_tag="$account_id-$ts"
# Glue 作业名称
GLUE_JOB_NAME="llm-analysis-text-job"
# DynamoDB中存储prompt的表名
LLM_ANALYSIS_TEXT_TABLE_NAME="prompt-template"
# 存储原始数据以及分析结果的S3名称
S3_BUCKET_NAME="llm-analysis-text-${unique_tag}"
# S3中原始数据Prefix的名称
RAW_DATA_PREFIX="raw-data/"
# Glue Catalog中DB名称
GLUE_DATABASE="llm_text_db"
# Glue Catalog中查询S3中分析数据使用表名
GLUE_TABLE="sentiment_result"
echo "GLUE_JOB_NAME=${GLUE_JOB_NAME}" > .env
echo "LLM_ANALYSIS_TEXT_TABLE_NAME=${LLM_ANALYSIS_TEXT_TABLE_NAME}" >> .env
echo "S3_BUCKET_NAME=${S3_BUCKET_NAME}" >> .env
echo "RAW_DATA_PREFIX=${RAW_DATA_PREFIX}" >> .env
echo "GLUE_DATABASE=${GLUE_DATABASE}" >> .env
echo "GLUE_TABLE=${GLUE_TABLE}" >> .env左右滑动查看更多
执行脚本。
bash ./gen_env.sh使用 CDK 安装环境。
npm install
cdk bootstrap
cdk synth
cdk deploy等待几分钟后,方案部署完毕,会有以下输出内容,当然我们也可以在 Amazon console 中 CloudFormation 中查看。

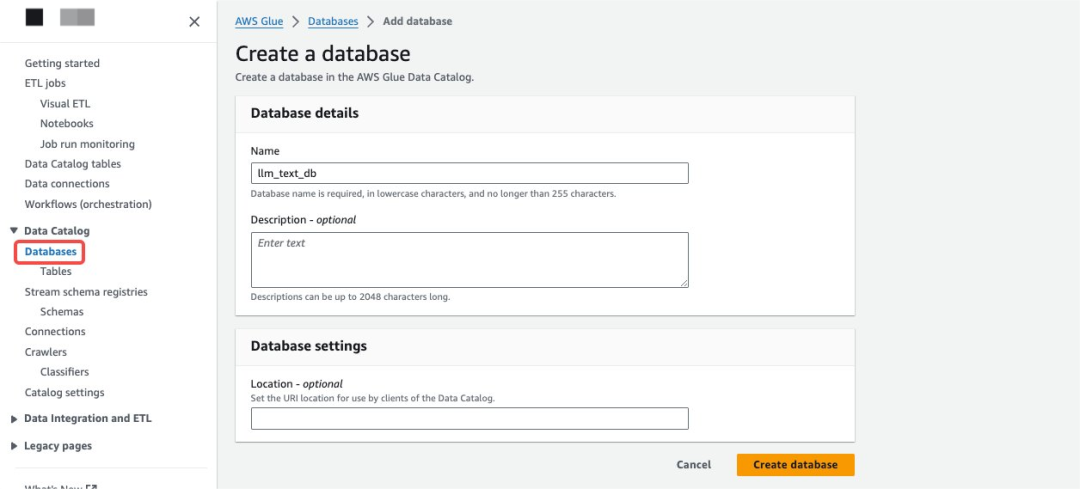
创建 Glue Catalog DataBase。
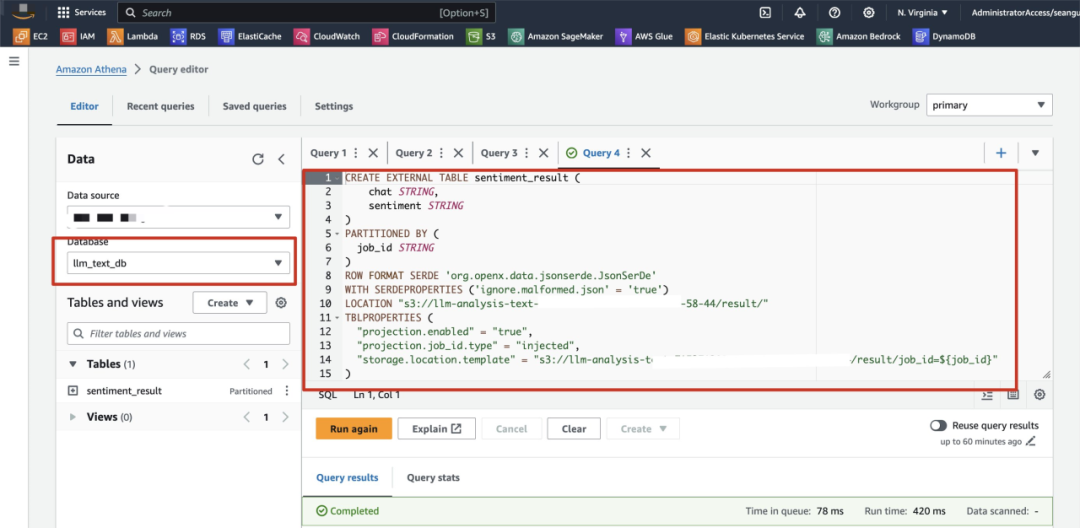
创建 Athena Table,打开 Athena Console Query Editor 执行下面的语句,本案例中我们会在 Glue Job 中输出玩家对于游戏内关键字的 positive neural negative 的类型,所以会有两列,同时我们也会针对每次运行的 Glue Job 结果进行分片处理,创建 Table 内容如下所示。
CREATE EXTERNAL TABLE sentiment_result (
chat STRING,
sentiment STRING
)
PARTITIONED BY (
job_id STRING
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES ('ignore.malformed.json' = 'true')
LOCATION "s3://<替换上面配置的S3 Bucket名称>/result/"
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.job_id.type" = "injected",
"storage.location.template" = "s3://<替换上面配置的S3 Bucket名称>/result/job_id=${job_id}"
)左右滑动查看更多
如下图所示。
S3 Prefix 设计
本案例中我们会使用一个 Bucket 来存储原始聊天记录、分析后的结果以及 Athena 的查询结果,所以整体的 S3 Prefix 设计如下:
root ———————— raw-data/ # 该目录下存放聊天记录原始数据,建议通过文件夹的方式来放置,如:raw-data/test1/,raw-data/test1/
|——————— result/ # 用来存储解析后数据
|——————— athena-query-results/ # 用来存储Athena查询的结果左右滑动查看更多
Glue Job 设计,参考
llm-analysis-text.py
Glue Job 使用 Python Shell 的方式来进行数据处理,其中需要注意的点是从 S3 中获取的数据文件,需要按照自己的数据格式来进行解析,在本案例中我们使用的数据格式如下:
'10592539446264|64|2025-09-01 18:00:33,683|{"uid":"","c":6,"custom":"{\\"mod\\":\\"\\",\\"modPic\\":0,\\"officialTitle\\":-1,\\"clientTime\\":\\"170929053310592539446264\\",\\"responseData\\":null,\\"atData\\":null,\\"modid\\":0}","llm":"","m":"他扫别人我不管,级别好,我一个小级别的惹谁了","group":""}左右滑动查看更多
所以在处理格式的时候,我们使用了如下的代码进行解析,如果咱们聊天记录导出时不是类似格式,请修改代码进行适配。
# 提取有价值聊天记录
def extract_value_data(lines):
extracted_data = []
# 提取聊天的正则表达式模式
pattern = r'"m":"(.*?)"'
# 遍历每一行
for line in lines:
match = re.search(pattern, line)
if match:
text = match.group(1)
if not text.startswith('link'):
extracted_data.append(text)
return extracted_data抽取完有价值内容后,因为整体的内容比较多,不能一次性全部作为 LLM 的输入,所以我们也需要对内容进行 chunk 的处理,在这里我们不建议每个 chunk 的内容过长,在这里我们的参考代码如下:
# 切分文件
def split_into_chunks(arr, n):
chunks = []
for i in range(0, len(arr), n):
chunks.append(arr[i:i+n])
return chunks
# 切分文件
chunks = split_into_chunks(value_lines,2000)
print(f'Number of chunks: {len(chunks)}')
llm_analysis(obj.key,chunks)左右滑动查看更多
处理文件后,我们就可以来调用 Bedrock 来进行语义分析了,在我们测试过程中发现,如果我们在提示词中让 LLM 同时做针对关键字内容的抽取,然后再去做抽取内容的语义分析时,LLM 会出现迷失的情况,表现为:在不同的 chunk 返回值中,有的 chunk 返回的内容存在不相关性,所以我们这里使用了 Langchain 的 route 来做两个步骤的处理,也就是下面的代码中处理逻辑:
构建两个 chain,分别处理基于关键字主题内容的抽取和针对输入内容进行语义分析;
route 的设计中,只有在 chain1 返回有价值的结果时才会通过 chain2 来进行语义分析。
chain_1 = prompt_extract | llm_sonnet | output_parser
chain_2 = prompt_sentiment | llm_sonnet| output2_parser
def route(info):
if not 'no relevant quotes' in info['relevant_info'].lower():
return chain_2
full_chain = ({'relevant_info':chain_1,'topic':itemgetter('topic')})| RunnableLambda(route)左右滑动查看更多
所以语义分析后的结果,我们会通过 parser 处理成 json 格式的数据存储到 S3 中,主体处理流程结束。
端到端流程演示
使用以下命令,启动 Streamlit 服务。
安装依赖
cd llm-text-keyword-summary/demo
pip3 install -r ./requirements.txt配置环境变量
打开 gen_demo_env.sh。
#!/bin/bash
# Api Gateway 暴露的domain URL,需要在CDK 部署完毕后进行配置
domain_url="https://xxxx.execute-api.us-east-1.amazonaws.com/prod/"
# 调用Api Gateway 暴露的domain URL API key,需要在CDK 部署完毕后进行配置
apikeys=""
echo "domain_url=${domain_url}" >> .env
echo "apikeys=${apikeys}" >> .env左右滑动查看更多
Domain URL 在上面执行完 CDK 后会输出,我们同时查看 API Key 的值,打开 Console。

Console
扫码了解更多
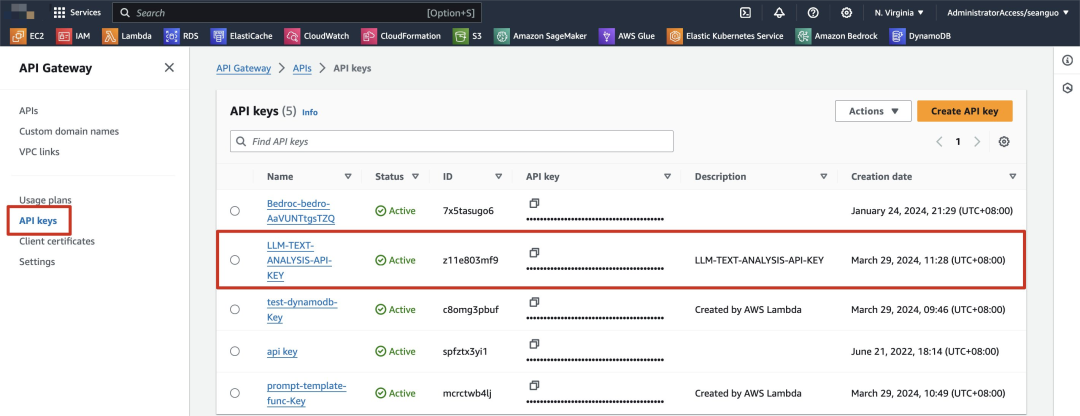
拿到 Domain URL 以及 API key 之后,执行脚本。
bash ./gen_demo_env.sh执行完毕后启动服务。
streamlit run demo_app.py --server.port 6001左右滑动查看更多
访问相应地址后,可以看到以下内容。
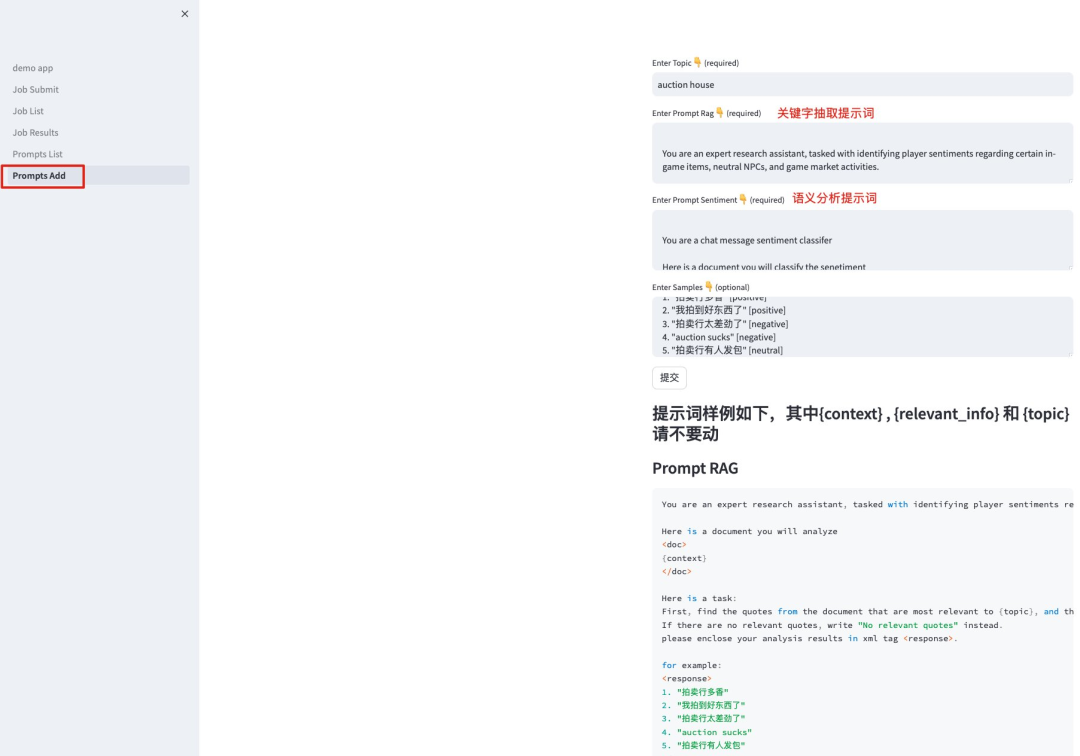
维护提示词内容。
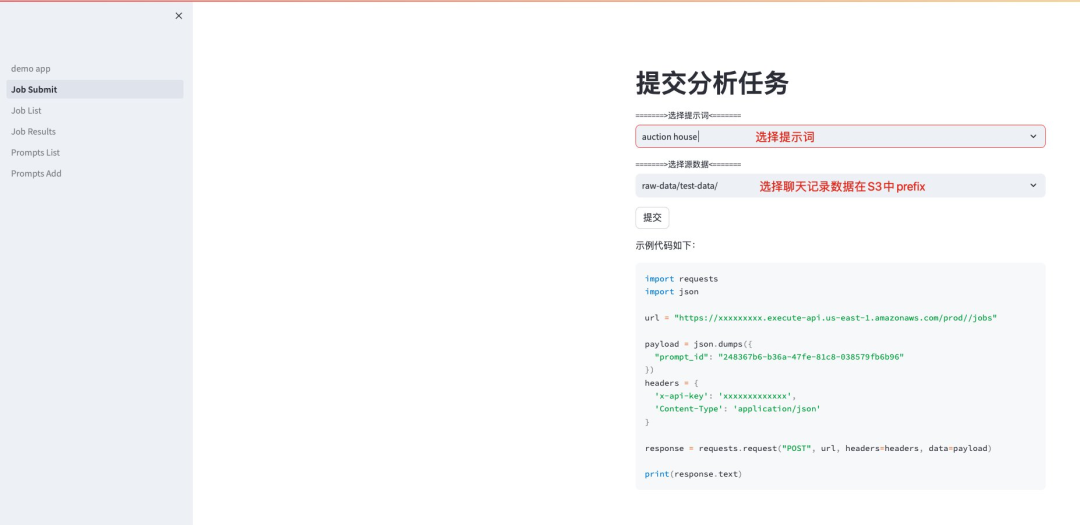
使用创建好的提示词来启动分析任务。
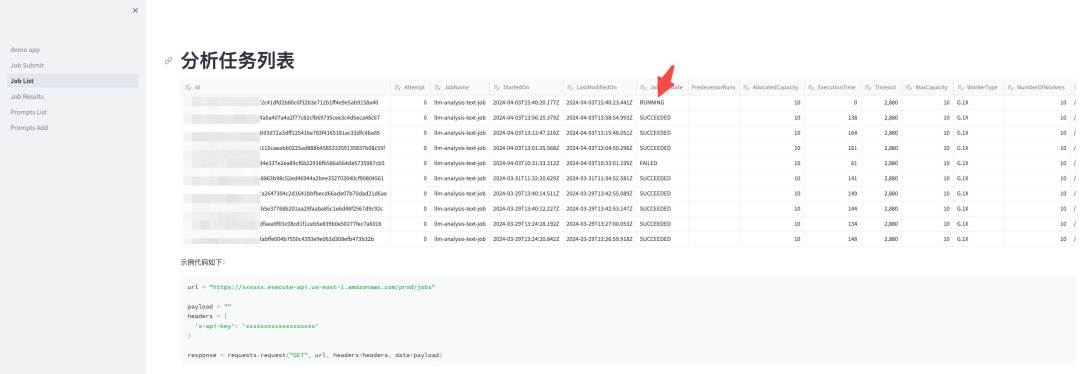
查看任务状态。
等待任务处理完毕后,我们可以通过 Job Id 来查看分析的结果。
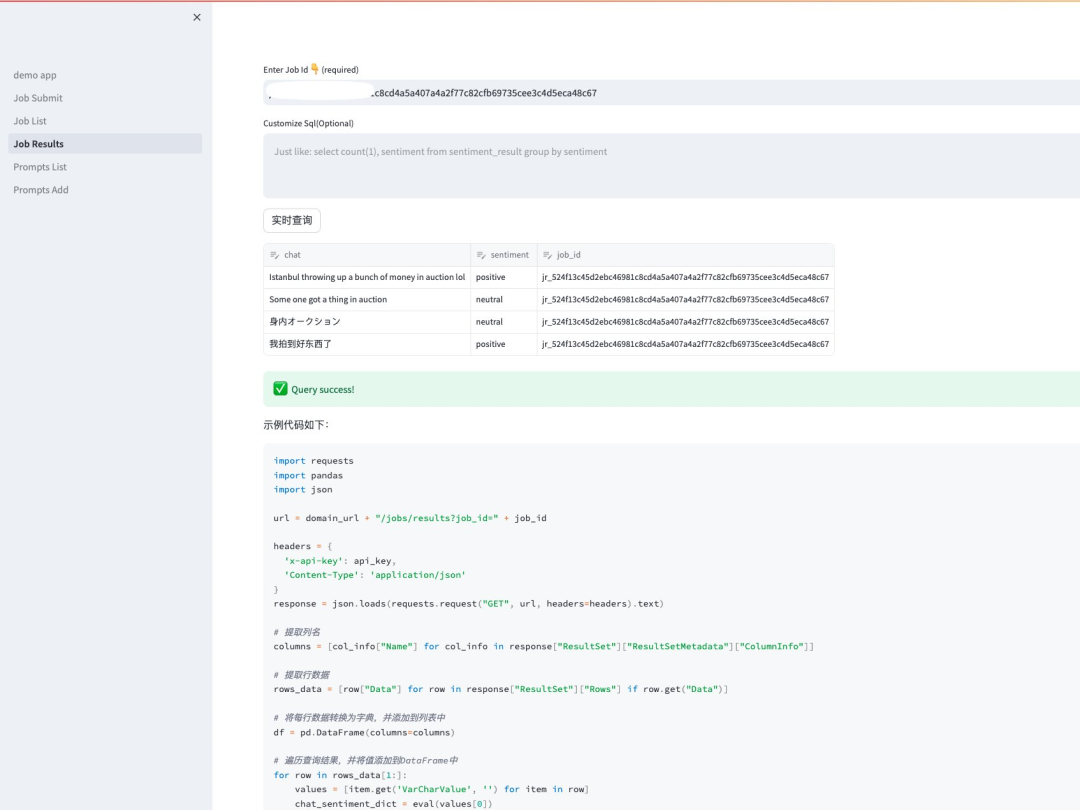
也可以通过自定义的 SQL 语句来进行统计信息。
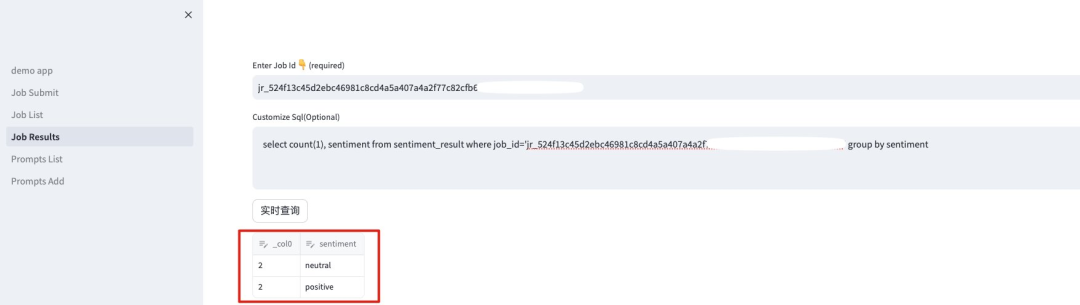
至此我们可以看到我们可以非常方便地获取玩家的反馈信息加以分析。
PostMan 文件
同时在项目文件中我们也提供了 PostMan 的方式来进行接口调用,大家只需要将 json 文件导入即可以进行测试。
总结
通过以上内容演示,我们可以看到使用 Amazon Bedrock 结合 Serverless 的架构可以帮助我们快速地根据玩家聊天内容进行语义抽取以及统计,方便游戏运营人员及时作出游戏内容或者策略调整,达到对于玩家舆情的监控,大大提升玩家的留存,提高玩家的游戏体验。
本篇作者

赵聪慧
江娱互动 Top War 项目后端主程,资深游戏服务端技术。

郭俊龙
亚马逊云科技解决方案架构师,主要负责游戏行业客户解决方案设计,比较擅长云原生微服务以及大数据方案设计和实践。

谢川
亚马逊云科技生成式 AI 高级解决方案架构师,负责基于亚马逊云的生成式人工智能解决方案的设计,实施和优化。曾在通信,电商,互联网等行业有多年的产研经验,在数据科学,推荐系统,LLM RAG 等方面有丰富的实践经验,并且拥有多个人工智能相关产品技术发明专利。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客,获得更详细内容
















 9204
9204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









