







在商业数据分析中,企业需要一套完善的数据技术与工具,来推动数据资产的持续沉淀,以助力决策者快速有效地从大量数据中分析出有价值的信息。当前市场正在经历快速转型,区别于传统的 ETL 和其他的技术,本文用 ELT(extract, load, transform)实现数据集成。
ELT 非常适合为数据湖仓提供数据管道,并且可以用更低的成本,根据需求,随时对大量数据进行分析。为此,文章将为大家介绍如何利用 Amazon Redshift+DBT(data build tool)+ Amazon MWAA(Amazon Managed Workflows for Apache Airflow)的方案来搭建现代数据栈,以概念介绍和 demo 形式,用以给客户展示此套方案的优势。
需求背景介绍
客户目前使用一站式集成数据开发平台,反馈当前平台在运维,工作流管理上有所缺失。
数据引擎没有存算分离,扩展不灵活。
数据引擎运行小任务时效率不高,运行时间长。
技术栈选择
本解决方案 Amazon Cosmos,用到的服务包含 Amazon Redshift、Amazon MWAA、以及开源工具 DBT 和 Amazon Cosmos。
企业级数据仓库 Amazon Redshift:
Amazon Redshift 数仓是列式存储,存算分离,有大规模并行处理能力,自动工作负载管理,无需手动调优,与亚马逊云科技分析服务无缝集成。Amazon Redshift 分为集群版和 Serverless 版,可以根据工作负载灵活选择。Serverless 按实际运行时间计费,不用则不计费,可随时灵活调整计算资源大小以满足 SLA 计算需求的特性,非常适合 DBT 进行 ELT 的工作负载场景。且数据存在 S3 可以显著降低存储成本。Redshift 共享数据,可以基于不同场景的工作负载,匹配不同规模的集群,从而达到最佳性价比。因此可以解决当前数据引擎没有存算分离,扩展不灵活以及数据引擎运行小任务时效率不高,运行时间长的问题。
数据建模和转换 DBT:
当数据科学被越来越多运用在各类场景之后,不同的数据模型、不同的版本、不同的维度指标等如何维护,如何更好地让整个数据团队协作,就成了非常棘手的问题。而 DBT 的出现可谓一剂良药,通过将软件工程的工作流引入数据科学,建立了完整、统一、开放且自动的数据科学研发流程,涵盖建模、版本、测试、文档、部署等环节。
本方案引入开源工具 DBT(data build tool),是用户专注于数据转换和建模,它在数据仓库中执行转换和汇总,使用 SQL 和软件工程最佳实践构建数据模型。以便为分析提供更具可读性和易用性的数据结构。DBT 允许分析师定义业务逻辑、创建衍生字段、执行聚合等操作,将源头裸数据转化为更容易理解和使用的形式。DBT 的强项在于支持分析人员更好地理解和使用数据,而不仅仅是数据的传输和存储。另外,DBT 将 DevOps 思想引入到数据分析领域中,将数据转换流程自动化为可重复运行的 pipeline,并支持与 CI/CD 工具集成,实现持续集成和交付。
工作流设计与编排 Amazon MWAA:
MWAA 是完全托管的 Apache Airflow 环境,可以降低运维成本;Airflow 是一个开源的数据管道编排和调度工具,用于数据工程和数据流处理。它提供了一个可编程的、可扩展的平台,用于定义、调度和监控数据处理工作流。
在数据工程中,Airflow 被用于构建和管理复杂的数据流水线。它允许数据工程师定义工作流程中的任务和依赖关系,以及任务之间的调度和触发条件。通过 Airflow 的用户界面,用户可以可视化和监控工作流的状态、运行情况和任务执行结果。
Cosmos:
Cosmos 用于 Airflow 和 DBT 的集成对接,通过该框架可自动识别 DBT 模型的血缘信息,无需再手工配置 Airflow 调度任务依赖。提高了数据工程师的工作效率,降低了管理复杂性。它使得在 Airflow 中使用 DBT 变得更加简单和标准化。
在本方案中,MWAA 和 DBT 可以协同工作,达到以下效果。并解决客户反馈当前平台在运维,工作流管理功能上有所缺失的问题。
Airflow 负责编排整体数据处理流程,将 DBT 作为一个任务集成进工作流
DBT 负责具体的数据转换和建模工作,生成数据模型供分析使用
Airflow 可以调度 DBT 任务的执行,并监控其运行状态
Cosmos 简化了在 Airflow 中使用 DBT
方案环境准备

创建 Redshift Serverless
创建过程不再赘述,建好的工作组如下,后面的步骤中需要通过‘查询数据’进入 Redshift query editor v2 client。
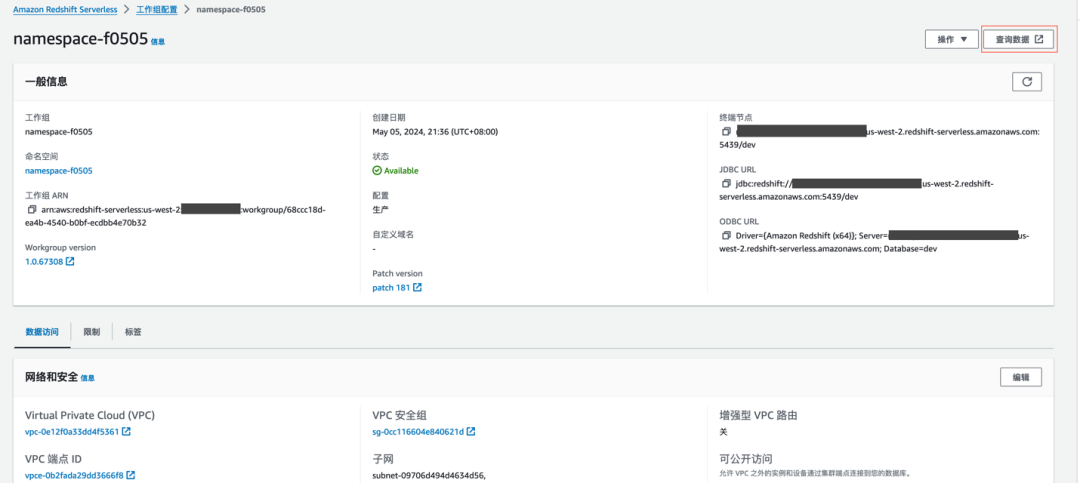
安装 DBT
DBT 分为 DBT core 和 DBT Cloud。DBT core 是 DBT 的开源部分,它提供了数据建模、转换和管理的核心功能。使用 DBT core,您可以定义和运行数据转换模型,自动编译为 Redshift 可执行的 SQL,并发送给 Redshift 执行,将数仓中的源头祼数据进行转换并物化成视图、表或者物化视图。DBT Cloud 是 DBT 的云服务,构建在 DBT core 的基础之上,提供了托管服务。本方案从 DBT core 的视角出发。
DBT 另一个重要的概念是 DBT adapters,即 DBT 适配器。我们要做数据处理一定是安装 DBT core +Redshift 所对应的适配器。
我们知道不同的数据库在 SQL 查询上都会有些许差异,要记住所有类型的特定语法成本高但收益低,但适配器正好帮我们做了这件事,适配器的作用之一是提供一种标准化的接口,让您可以使用相同的 SQL 语法来与不同的底层数据平台交互,而不需要关注 SQL 语句本身。
启动 Cloud9 环境,在 Cloud9 环境中安装 DBT core 与 DBT adapters。具体命令如下:
安装 DBT core 与 DBT adapters。
pip3 install dbt-core
pip3 install dbt-redshiftDBT 默认全局安装,所以即便你在某个项目路径下,它还是会基于全局安装,在安装完成之后,我们可以执行如下命令检查安装是否完成。可以看到安装的版本,路径等相关信息。
pip show dbt-core
初始化项目
接下来,需要初始化一个项目,而且我们还需要在项目中编写数据模型语句,以及一些基本的配置代码。
这里我们直接通过命令创建 DBT project。
运行以下命令开始创建您的 DBT 项目,命令会在~/.DBT 路径创建一个 profiles.yml 配置,而项目本身就是依赖这个配置来与数据库建立联系。
mkdir ~/.dbt
cd ~/environment
dbt init —profiles-dir ~/.dbt创建 DBT 项目需要您提供一些输入。需要参考已经创建的 Redshift 信息。
请相应地更改以下这些值以反映您的环境:
name for project:<demo_project> #定义项目名称
database to use: 2 #选择redshift
host: <host name of redshift> #填入redshift host name,参考已经创建的redshift serverless
port: 5439 #指定port
user: <awsuser> #redshift 的username
authentication method: 1 #鉴权方法选password
password: xxxxx #密码
dbname: dev #数据库名称
schema: dbt #schema名称
threads: 1 #threads 设为1左右滑动查看更多
运行命令行的截图参考如下:
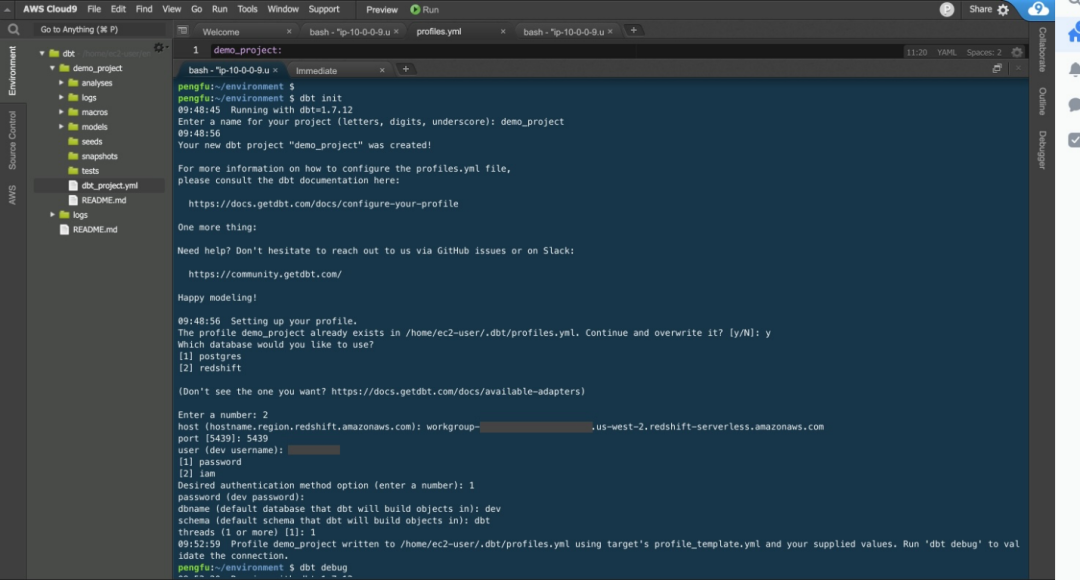
另外,除了命令,还可以使用官网的模版项目,因为 DBT 命令除了数据做转化,还包含数据写入数据库的命令,而 init 创建的模版只是最基础的模版,不包含模拟数据,也不包含模拟的数据模型,一切从零开始还是会存在部分难度。这里我们不对模版项目进行展开。
连接 Redshift
现在我们需要 DBT 连接 Redshift 数据库,接下来才能做数据转换的工作。
通过 profiles 定义相关信息用来连接 Redshift 参数。通过上一步的 DBT init 命令存储在 profiles.yml 文件中,隐藏在目录 ~/.DBT 中。
执行以下命令,借助 Cloud9 文本编辑器,查看并确保您的输入已经如实归档。
npm install —location=global c9
c9 ~/.dbt/profiles.yml现在,您可以通过运行以下命令来检查 DBT 项目的设置并测试与 Redshift Serverless 端点的连接性。DBT debug 将尝试连接到 profiles.yml 中定义的 Redshift 端点。
cd ~/environment/demo_project
dbt debug下图展示了 DBT demo_project yml 文件内容:

运行 DBT debug 用来检测连接结果。
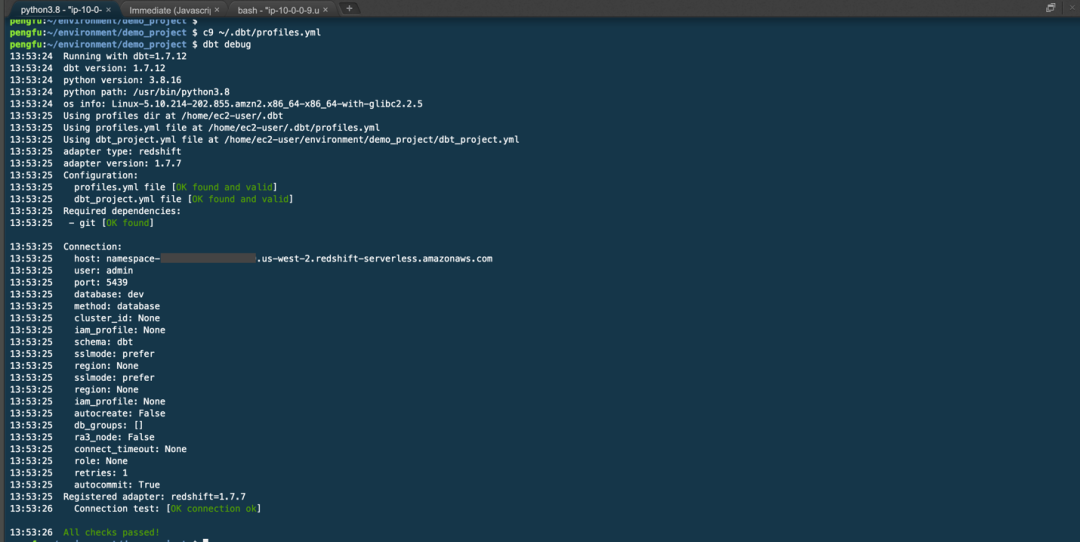
应当能看到与上述截图类似的信息。如果在运行 DBT debug 时遇到错误,请检查 profiles.yml 文件是否存在、是否完整,以及其中的信息是否正确无误。另外需要注意安全组设置是否影响连通。
创建 MWAA 环境
在此之前,需要先创建 S3 桶和 dags 文件夹,并填入到 MWAA 环境信息中。
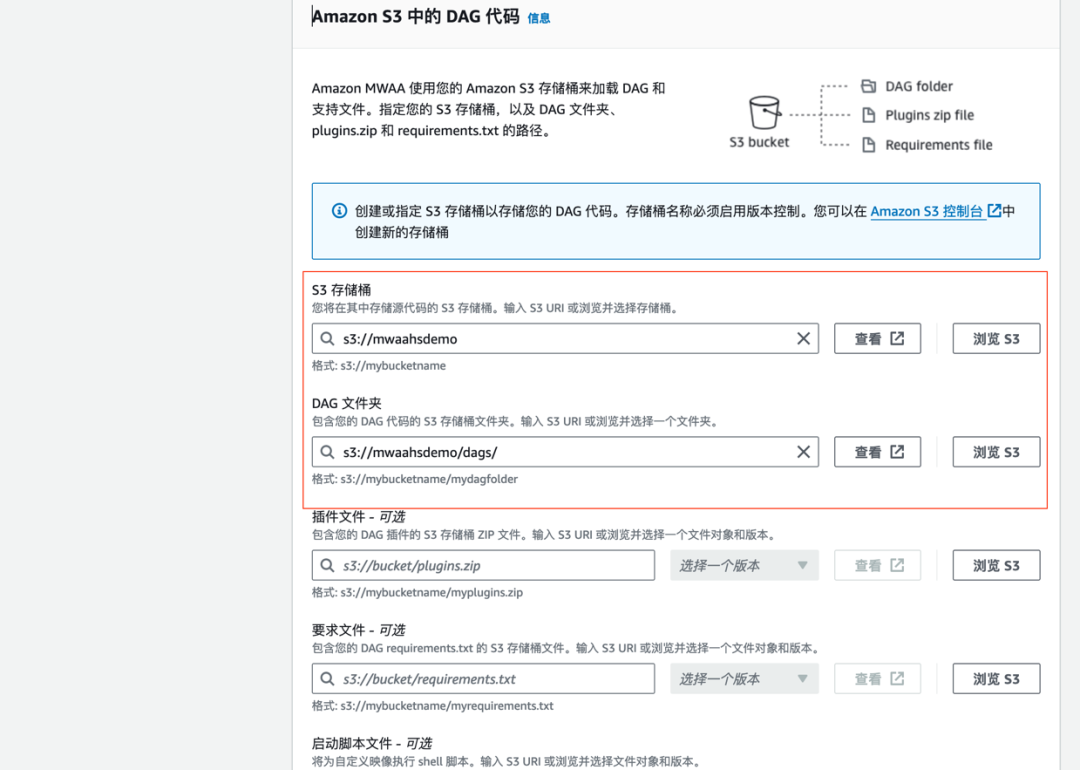
此过程需要 20-30 分钟,待创建完毕后,进入 Airflow UI。此时因为 S3 桶中 dags 目录下为空,所以没有任何 DAG。

此处针对不同网络环境做相应调整:
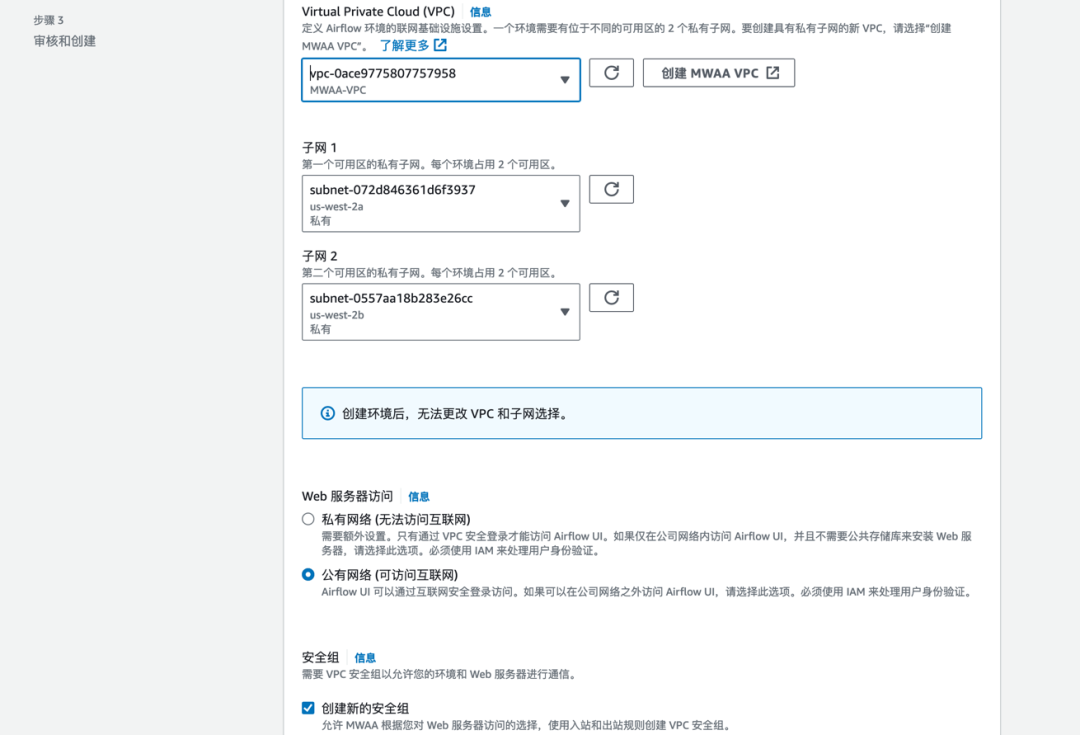
本环境 MWAA 和 Redshift 在不同 VPC 中,需要在 Redshift 中创建 VPC 端点;如果 MWAA 和 Redshift 在相同 VPC 中,则省略这一步。

端点设置需要保持和创建 MWAA 环境时 VPC、子网、安全组保持一致。完成创建端点。注意安全组设置确保相关流量放通。
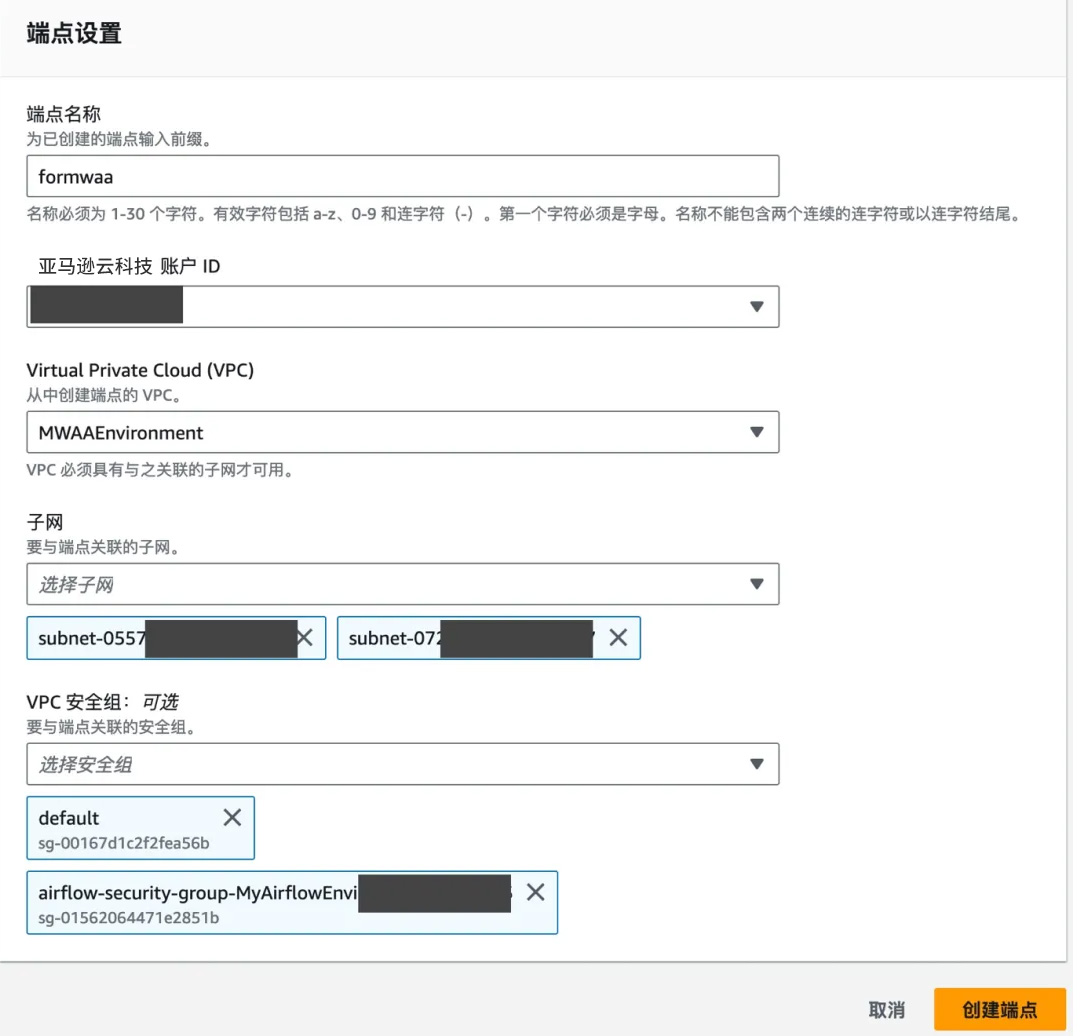
这里可以做连通性测试,在 MWAA 的 VPC 中起一台 EC2,测试端点连通性,确保可以连接,然后删除 EC2。

创建 CI/CD 管道
创建 codecommit 存储仓库,以 mwaa-repo 为例。
创建 codepipeline,构建管道,首先添加源。以 codecommit 为源,选择存储库与分支。
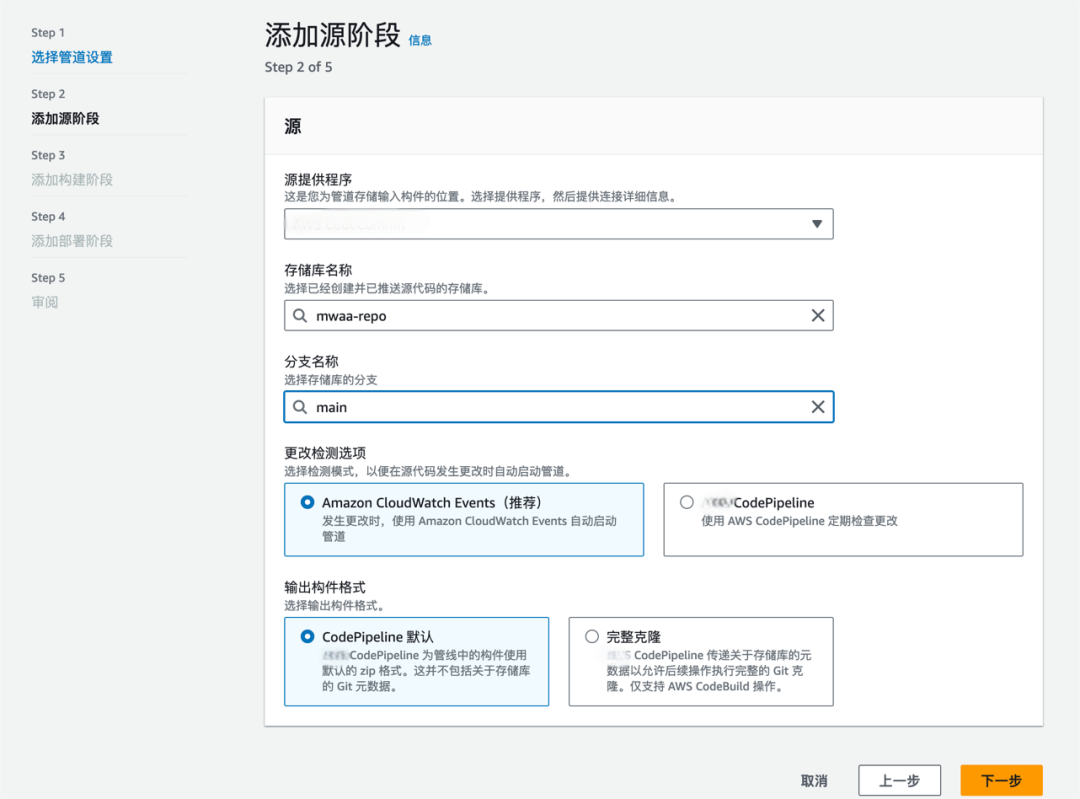
跳过构建阶段,在部署阶段选择部署到 S3 桶中。存储桶为 MWAA 环境中定义的桶,MWAA 会从桶中 dags 文件夹自动读取 DAG 文件。跳过构建阶段,在部署阶段选择部署到 S3 桶中。存储桶为 MWAA 环境中定义的桶,MWAA 会从桶中 dags 文件夹自动读取 DAG 文件。
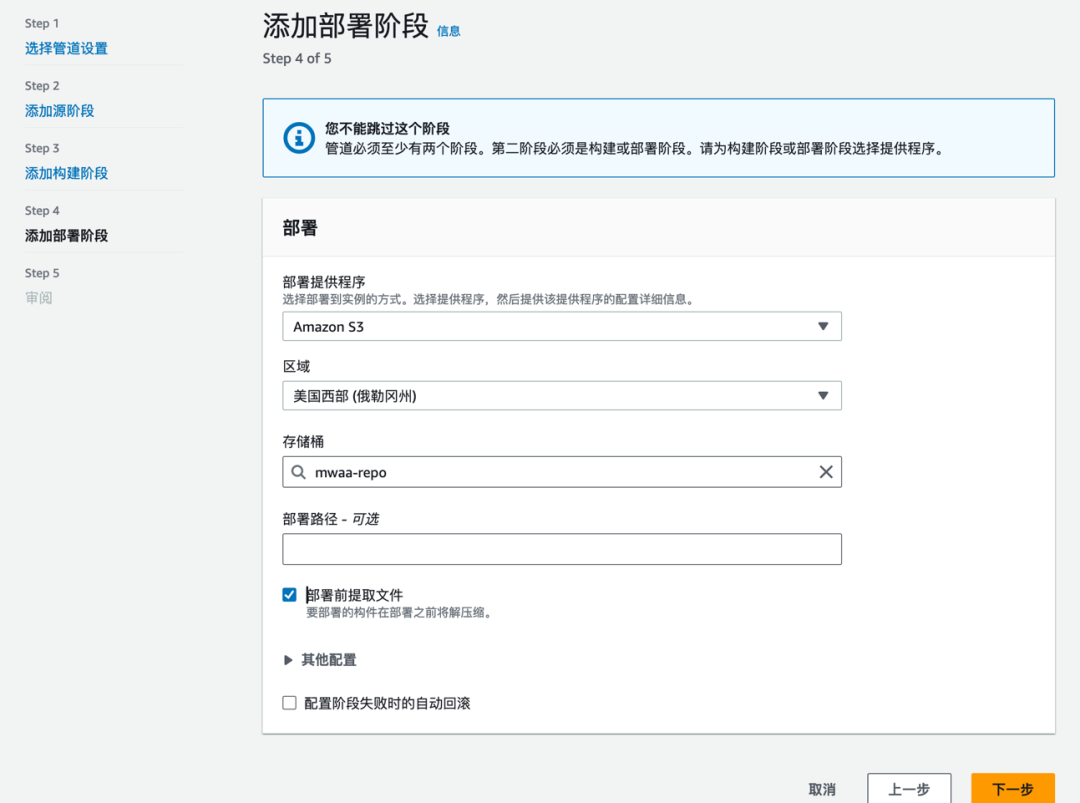
配置连接参数
在 codecommit 中新建 mwaa-repo 存储库。并预先上传以下文件,我们需要理解其中的设置。代码请扫描下方二维码了解详情。
requirement.txt
startup-script.sh
DBT_dags.py

代码
扫码了解更多
start-script.sh:
脚本用于在 MWAA 环境中设置 DBT 的虚拟 Python 环境,并在其中安装了 DBT 及其相关依赖项。这样做的目的是为了隔离 DBT 的运行环境,避免与系统或其他应用程序的依赖项发生冲突。
requirement.txt:
--constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.8.1/constraints-3.11.txt"
astronomer-cosmos左右滑动查看更多
其中 url 地址指向了 Apache Airflow 官方提供的一个约束文件,用于确保安装的 Python 包版本与 Airflow 2.8.1 版本兼容。这个约束文件列出了一系列 Python 包及其允许的版本范围,以避免版本不兼容导致的问题。
使用这个约束选项可以确保安装的包与 Airflow 2.8.1 版本兼容,从而提高稳定性和可靠性。
astronomer-cosmos 可以确保在安装依赖项时也会安装这个包,以便在 Airflow 中使用 Cosmos 提供的功能。
DBT_dag.py:
代码是一个 Airflow DAG(Directed Acyclic Graph)定义,用于在 Airflow 中集成和执行 DBT 任务。而 Cosmos 提供了一种简单、标准化的方式来管理和运行 DBT 任务,如果不使用 Cosmos 的话,您需要自己编写更多的代码来实现类似的功能。
其关键信息解释,下图仅截取部分代码加以解释。
执行配置(ExecutionConfig)
EXECUTION_CONFIG 定义了 DBT 的执行模式和可执行文件路径。这里使用了 ExecutionMode.VIRTUALENV,表示 DBT 将在一个 Python 虚拟环境中执行。DBT_executable_path 指定了 DBT 可执行文件的路径。
配置文件配置(ProfileConfig)
PROFILE_CONFIG = ProfileConfig(
profile_name="demo_project", //dbt中定义的profile
target_name="dev",
profile_mapping=RedshiftUserPasswordProfileMapping(
conn_id="redshift",
profile_args={"schema": "dbt"},
),
)左右滑动查看更多
RedshiftUserPasswordProfileMapping 是 Cosmos 中的一个配置文件映射类,用于将 Airflow 连接 ID 映射到 DBT 配置文件中的数据库连接细节。
这里,conn_id 指定了 Airflow 中定义的 Redshift 连接 ID,profile_args 则设置了额外的连接属性 schema。
项目配置(ProjectConfig)是 Astronomer Cosmos 库中的一个类,用于配置 DBT 项目的相关设置。
DAG 定义
dag_id 设置了 DAG 的 ID,start_date 指定了 DAG 的开始日期,schedule_interval 设置了 DAG 的调度间隔(每天运行一次)。
定义了三个任务:
start:一个空操作符,用于标记 DAG 的开始。
DBT_task:一个 DBTTaskGroup 操作符,用于执行 DBT 任务。它使用了前面定义的执行配置、配置文件配置和项目配置。
end:另一个空操作符,用于标记 DAG 的结束。
任务依赖关系
最后,使用>>操作符定义了任务之间的依赖关系。start >> DBT_task >> end 表示 DBT_task 任务依赖于 start 任务,而 end 任务依赖于 DBT_task 任务。
clone 到 Cloud9 环境的~/environment 目录下。并在 mwaa-repo 目录下新建 dag 子目录,作为 DBT 模型存放目录,并且把 DBT_dags.py 移动到 dags 下。这里操作比较灵活,直接把上述文件传到 Cloud9 环境也可以。
在 secrets manager 中
创建托管密钥,防止泄漏
密钥名称:airflow/connctions/redshift (此处应该 map 前文 ProfileConfig 中conn_id=redshift)密钥值,明文内容可通过以下命令查看。直接复制即可,但因为本环境 MWAA 和 Redshift 在不同 VPC,host 需要更新为 Redshift 托管的 VPC 端点 url。其他不变。
cat ~/.dbt/profiles.yml
{
"schema": "dev",
"type": "redshift",
"host": "airflow-endpoint-xxxxxxx.97xxxxx19.us-west-2.redshift-serverless.amazonaws.com",
"port": "5439",
"threads": 1,
"user": "xxx",
"password": "xxxx"
}左右滑动查看更多
至此环境创建完毕。我们用 DBT 转换 Redshift 中的数据,用 Airflow 调度 DBT 任务,并结合 cosmos,其提供了一种简单、标准化的方式来管理和运行 DBT 任务。
数据处理
依靠此方案,我们展示数据如何被处理。接下来会用到的 DBT 中的 SQL,以及 MWAA 中的代码前文已经下载。
数据源为 S3
在 ELT 的过程,S3 中的源数据先‘L’加载到 Redshift,在 Redshift 中进行‘T’ 转化。
关于原始数据,我们使用示例数据,使用 COPY 命令从 Amazon S3 中加载示例数据。具体扫描下方二维码了解详情。
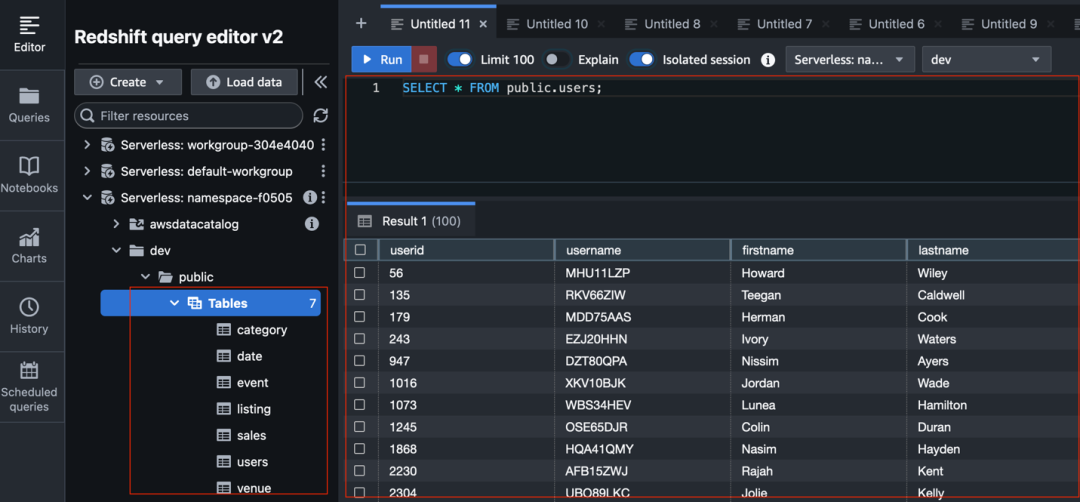
加载完后,检查数据:SELECT * FROM public.users; 数据已经成功加载到 Redshift 中。

示例数据
扫码了解更多
接下来是数据转换的过程,DBT 主要在这里发挥作用。数据基本处理思路是:
1)源数据加载到 Redshift 后作为原始表。
2)以原始表为基准处理后存入逻辑上的下一层表中,这里我们定义为 staging 层。
3)在 staging 层中表的基础上进一步处理为可以展示的结果。
我们需要在 model 目录下创建新的模型文件夹表示逻辑上的数据层,在其中写 SQL 文件实现数据转换。
构建数据模型
DBT 使数据转化可以借助模型,我们先为模型设置一个逻辑上的 staging 层供引用。模型是 SQL Select 语句,表示了您的数据转换逻辑,包括使用 case 语句和 join。staging 层属于模型的范畴,代表您的 Amazon Redshift 集群中现有的对象(表和视图)。
另外,根据您的 DBT 项目的性质,staging 层可以由不同的对象组成。例如,数据工程师的 staging 层可能与包含原始数据的表有关,而数据分析师的 staging 层可能与包含清理后数据的表有关。可以看到这里自主灵活性比较高。
构建可重用的数据模型,并将其提取到后续模型和分析中。更改一次模型,该更改将传播到其所有依赖项。这里创建 staging 层,保存由原始表做为源处理后的模型。以 staging_category.sql 为例,用 DBT 对原始表进行了简单加工。您可以根据不同的业务需求进行加工。
创建 staging 模型文件夹,并编写 schema 文件。
mkdir ~/environment/demo_project/models/staging
touch ~/environment/demo_project/models/staging/schema.yml
c9 ~/environment/demo_project/models/staging/schema.yml左右滑动查看更多
schema 文件如下:
version: 2
sources:
- name: public
tables:
- name: category
- name: date
- name: event
- name: listing
- name: users
- name: venue
- name: sales创建 staging_category.sql 文件,语句如下图。
with source as (
select * from {{ source('public', 'category') }}
)
select
catid::smallint AS catid,
catgroup::varchar(10) AS catgroup,
catname::varchar(10) AS catname,
catdesc::varchar(50) AS catdesc,
current_timestamp as etl_load_timestamp
from source左右滑动查看更多

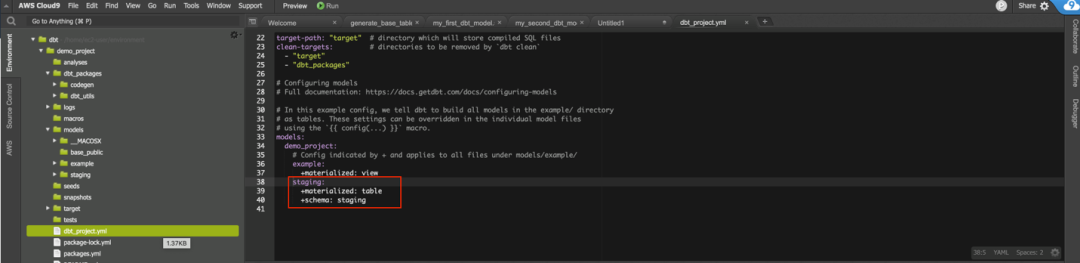
更新 DBT_project.yml 以配置 staging 这个新层。物化的概念很重要,其服务方式就是告诉 DBT,模型以何种方式保存入库。
DBT 提供了以下配置物化的选项如下,本方案中 staging 层,物化配置为 table。
view – 将 DBT 模型创建为视图
table – 将 DBT 模型创建为完全刷新的表
incremental – 将 DBT 模型创建为增量刷新的表
ephemeral – 临时模型并未直接构建到数据库中。相反,DBT 会将此模型的代码作为通用表表达式插入到依赖模型中
materialized view – 物化允许在目标数据库中创建和维护物化视图。物化视图是视图和表的结合
请注意,以测试、演示为目的,我们在 DBT 中运行 staging 模型。DBT 模型是使用 DBT run 命令运行。
可以选择使用—models staging 作为参数来运行 staging 目录中的所有模型,或者您可以通过在命令中指定模型的位置(使用—models staging.staging_category)来运行特定模型。
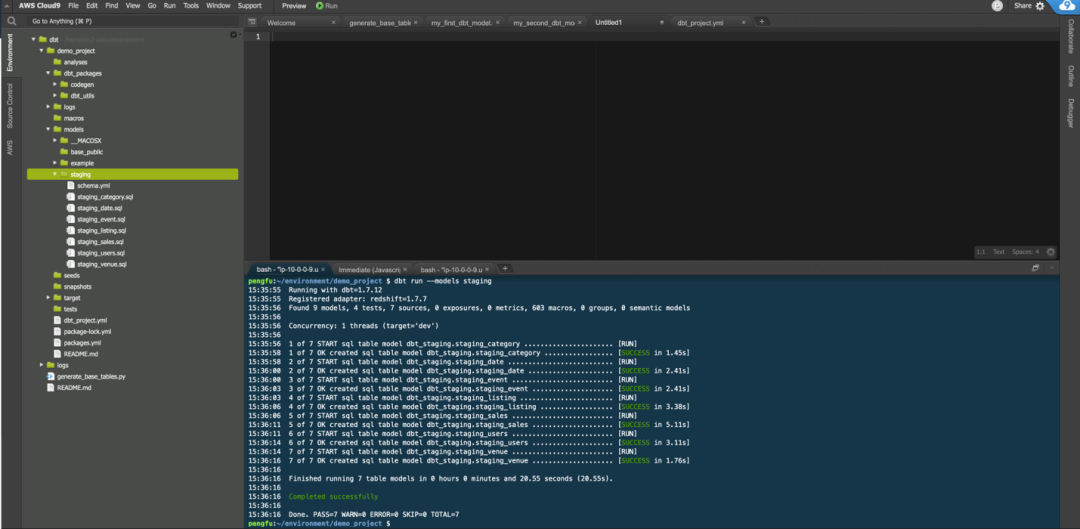
dbt run --models staging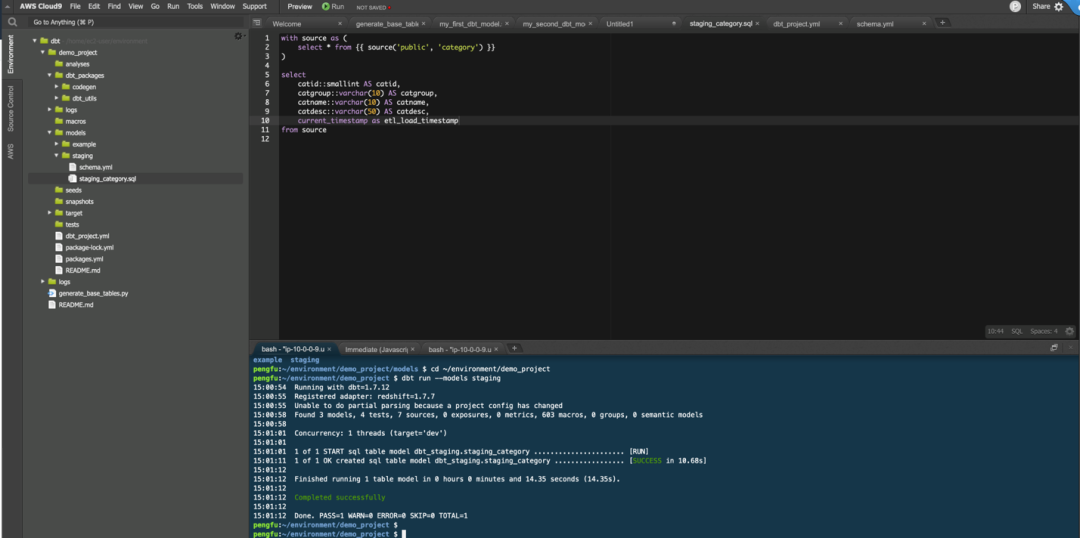
DBT run 编译并刷新 models 数据到数据库。成功运行 DBT 模型后,现在应该能够在 Amazon Redshift 中找到它。
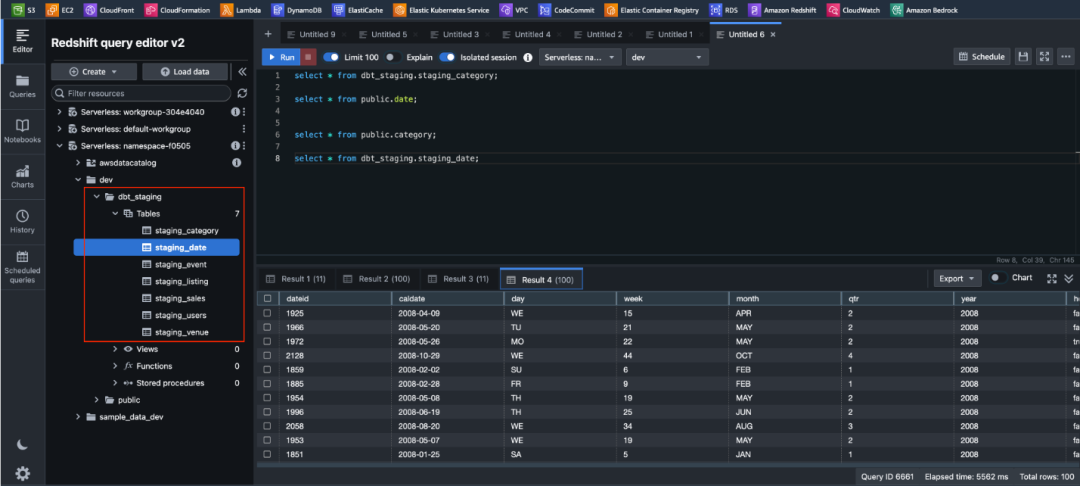
转到 Redshift Query Editor V2,刷新 dev 数据库,并验证有一个新的 DBT_staging 模式,其中包含 staging_category 表。
因为我们选择将 DBT 模型创建为完全刷新的表,可以用一条 select 语句验证数据已经存在入表中。
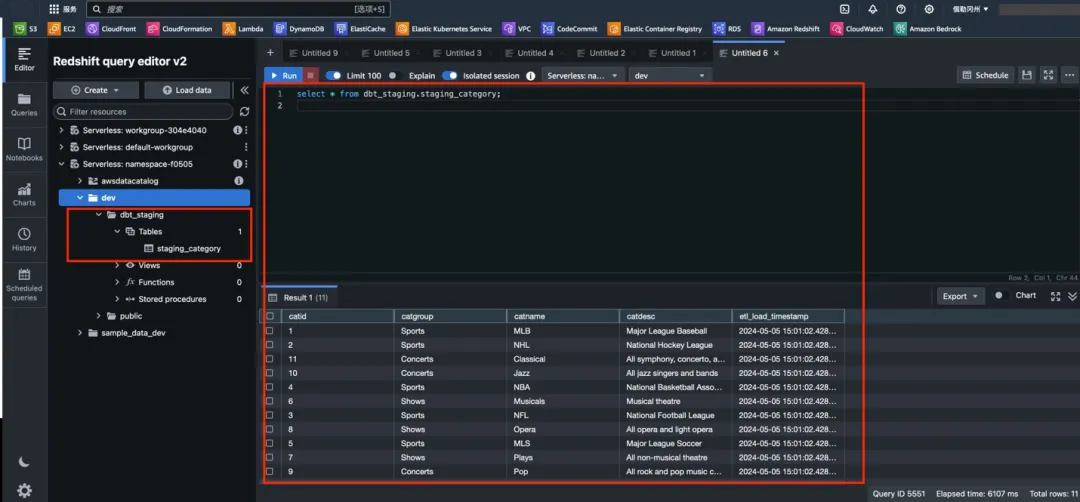
以同样的方式依据业务需求,对其余表也进行写 SQL 表达,具体 SQL 语句参考前文下载链接。
再次运行 DBT run ,运行完成后在 Redshift 中进行核查,可以看到所有 staging 层中的表已经由 DBT 创建好,并且数据已经生成。
利用模型实现数据转换
前面我们用 SQL 语句编写业务逻辑,返回所需的数据集,DBT 负责 SQL select 的物化,构建可重用或模块化的数据模型,这些数据模型可以在后续工作中引用,而不是从每次分析的原始数据开始。
这里假设某业务部门维护两个模型的情况,第二个模型引用第一个模型。引用是指重复使用,而不必重复编码。
创建新的模型文件夹,表示业务模型层。
第一个模型根据业务需求写 SQL 语句实现每季度财务数据。具体 SQL 语句参考前文链接。
mkdir ~/environment/demo_project/models/yw_dept
touch ~/environment/demo_project/models/yw_dept/yw_total_sales_by_event.sql
c9 ~/environment/demo_project/models/yw_dept/yw_total_sales_by_event.sql左右滑动查看更多
第二个模型引用了第一个模型。
touch ~/environment/demo_project/models/yw_dept/yw_top_events_by_sales.sql
c9 ~/environment/demo_project/models/yw_dept/yw_top_events_by_sales.sql左右滑动查看更多
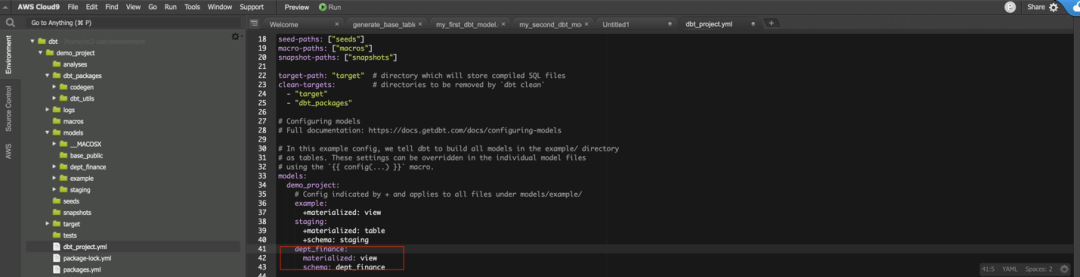
在创建某业务部文件夹和模型之后,需要更新 DBT_project.yml 文件以配置这个新的模型层,见下图。对于 yw_dept,会在 Redshift 上创建视图。
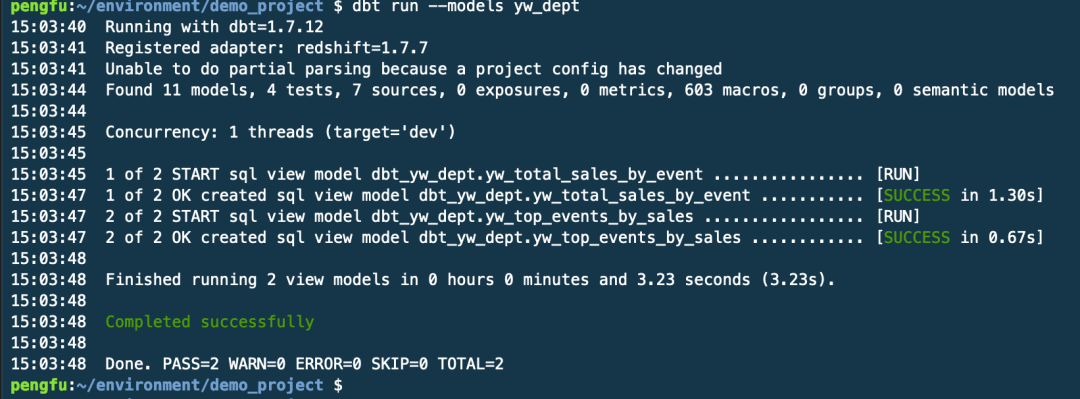
运行 DBT run –models yw_dept 实现模型的物化。
回到 Redshift 中查看,views 已经建好在 DBT 中定义视图,且数据已经生成。
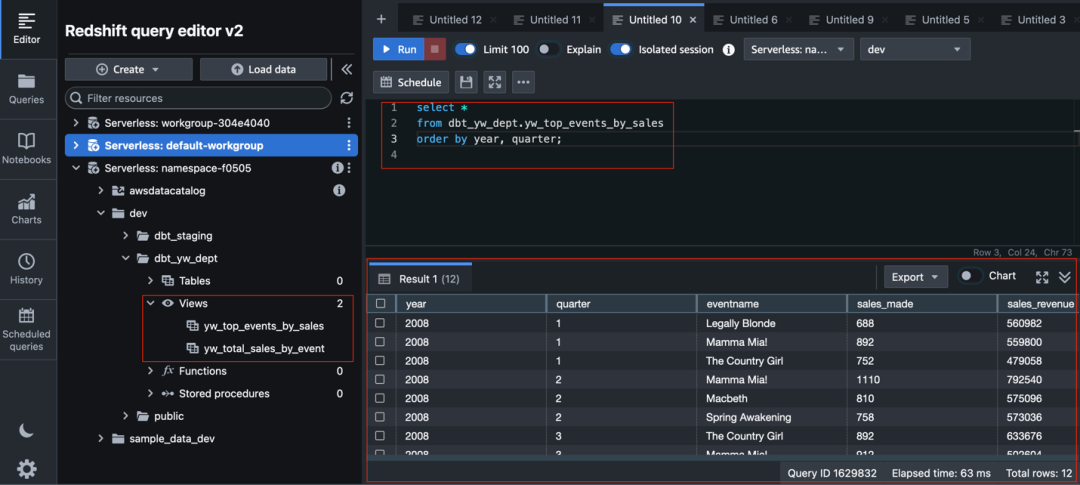
至此,我们已经看到通过 DBT 写模型,调用 Redshift,不需要在 Redshift 中编写 SQL 语句,达到数据转换的目的。
注意这里运行 DBT run 是调试目的,在后续的 Airflow 调度中,我们不需要回到 DBT 中运行 DBT run。
生成文档与数据血缘
DBT 提供了一个可视化界面,用于查看所有模型及其与其他模型之间的依赖关系。接下来创建并展示了 DBT 文档。利用这些文档,您能够看到在前面步骤中创建的模型的详细信息,包括血缘和源代码。
继续在 Cloud9 中运行以下命令,点 Preview Running Application
dbt docs generate
dbt docs serve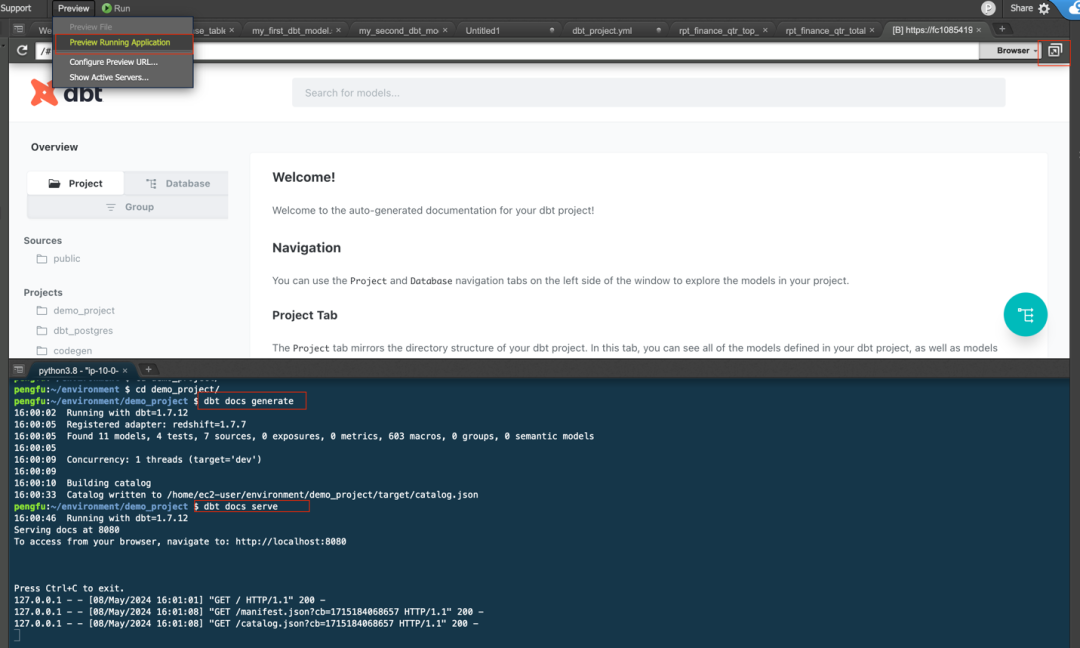
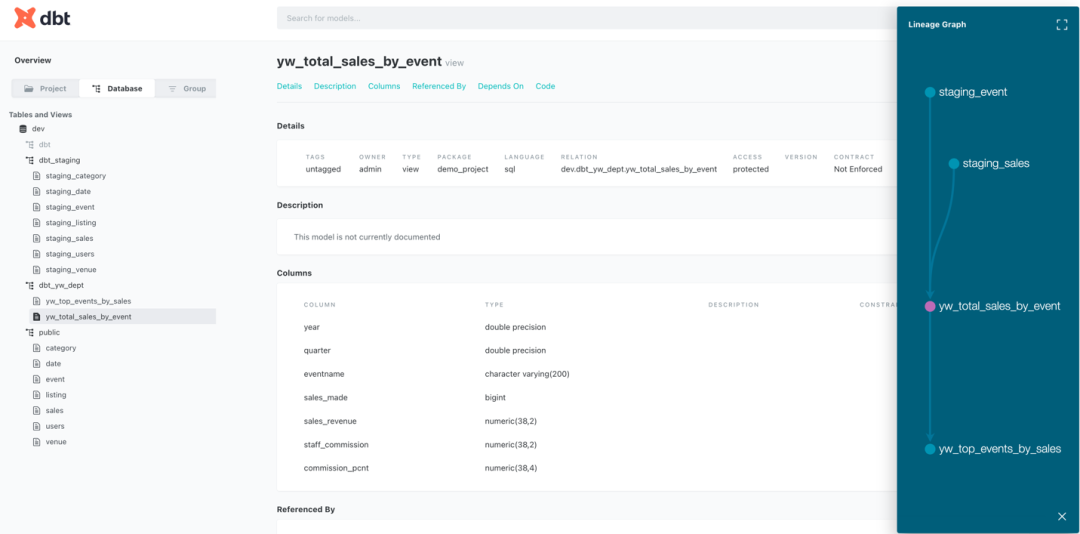
打开右上角 pop out 一个新的窗口,查看文档细节。借助 DBT document,我们可以看到文档(含字段)和血缘了。包括 project 下建立的模型,数据库详情,SQL 代码以及编译后的代码。具有非常好的可读性,助力团队内外不同人员去了解数据开发的情况。
通过 DBT 文档,可以看到表级别血缘图。满足了客户对数据分析中血缘关系的需求。
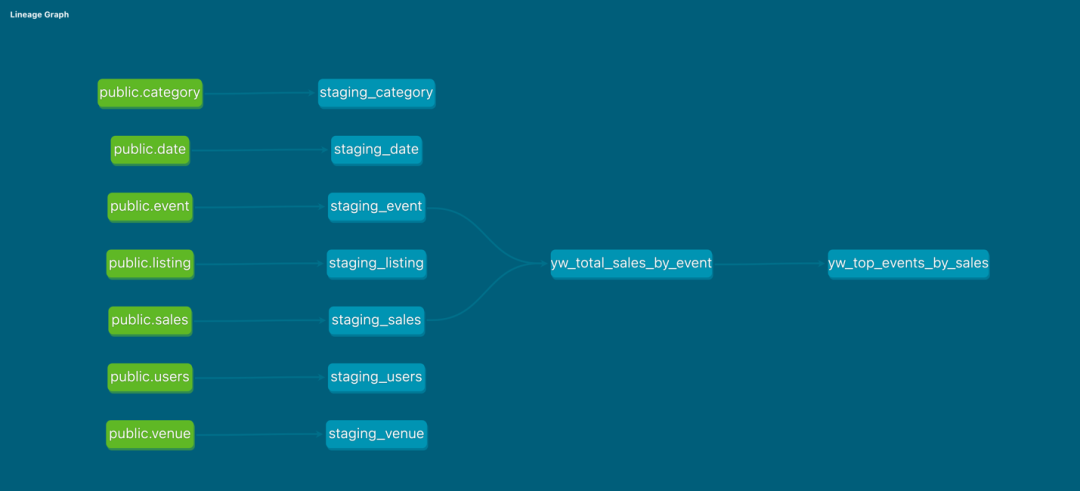
工作流编排
作为工作流编排工具,MWAA 负责协调和调度整个数据处理流程,包括数据摄取、转换、建模等各个步骤,支持 DAG(有向无环图)编程范式,灵活高效;提供监控、报警和重试等高级功能,下面开始构建 MWAA DAG。
将整个 DBT 项目复制到 MWAA 环境中。在 Cloud9 终端中运行以下命令。这将把整个 DBT 项目(demo_project)复制到您的 mwaa-repo 项目和 dags 文件夹中。
cd ~/environment/demo_project/
dbt parse
rm ~/environment/demo_project/.gitignore
cp -r ~/environment/demo_project/ ~/environment/mwaa-repo/dags/左右滑动查看更多
DAG 在前文中已经创建完毕,可以作为通用模版,这里不需要在此更新,注意 DBT_dags.py 文件需要在 dags 目录下。
自动化运行
现在,经过验证的 DBT 文件、Airflow、以及 cosmos 需要的配置已经就绪,在 Cloud9 中 push 代码到 codecommit,运行以下图中命令:
dags 中的 DBT 代码 push 到 codecommit 代码仓库后,会自动触发 pipeline,DBT 代码会被 copy 到 S3 桶中对应的 dags 目录下,此时就可以在 MWAA 中查看 DAG。
定时任务设的每日零时触发工作流,这里我们可以手动触发工作流,以检测运行结果。
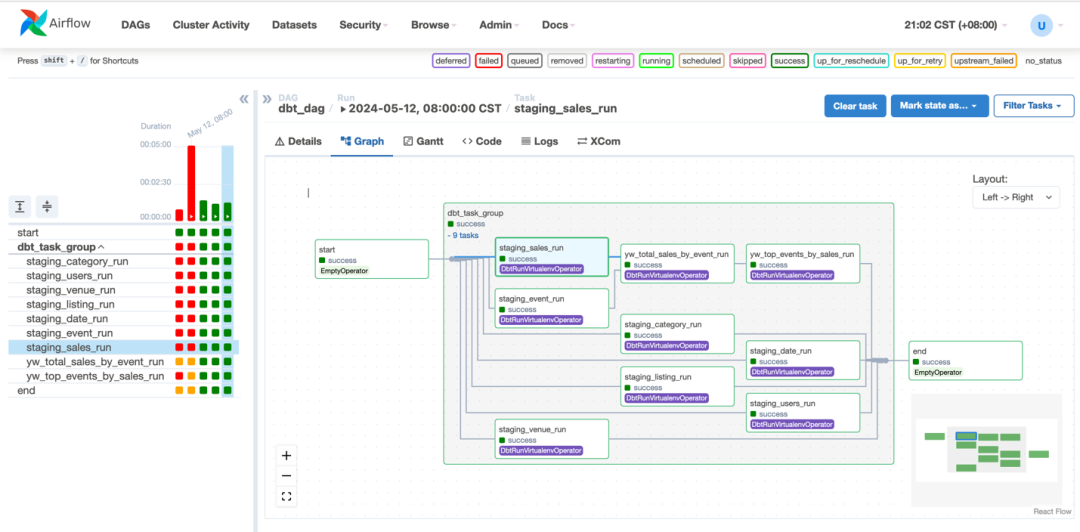
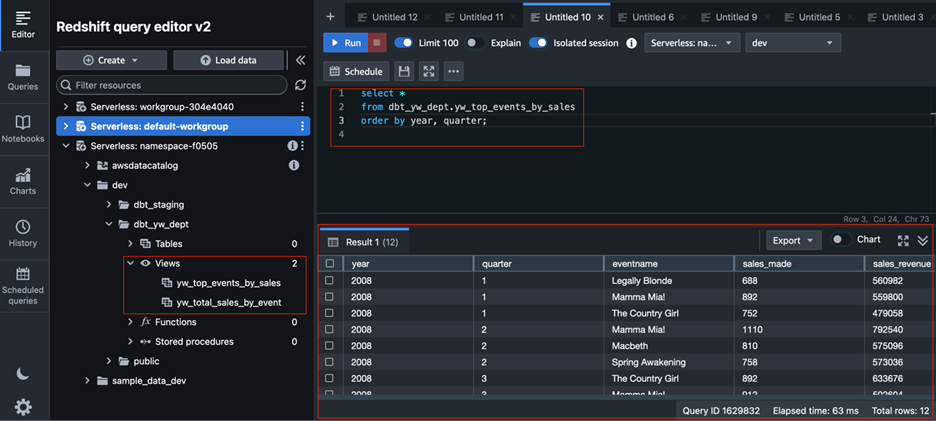
Amazon MWAA 在 Amazon Redshift 中运行 DBT 模型。要检查执行是否成功,在 Redshift QEv2 中检查结果,可以看到定义的 view 已经创建,并且可以查询到数据,表明工作流运行成功。
监控和调试
Airflow 调度器根据任务之间的依赖关系和调度规则来决定任务的执行顺序和时间,并监控任务执行情况;MWAA 提供了友好的 UI 界面让我们可以更方便地从各种维度监控以及调试,比如查看一年的运行情况。

总结
对比前文需求背景,本方案利用 Redshift Serverless,实现了存算分离、灵活扩展的需求,进一步优化的话,可以基于不同场景的工作负载,启用多个不同规模的集群分别承载不同业务,从而达到最佳性价比。
DBT 专注于数据转换和建模,让使用 SQL 的分析师能够高效处理已加载到数据仓库 Redshift 的数据。通过 DBT,开发者无需手动建表,无需手动维护文档和血缘,只是像编写前后端代码一样模块化进行数据分析,就能降低开发运维工作量。清晰的血缘关系对于确保数据质量、提高数据可信度、优化数据流程有重要意义。
通过 MWAA,可以更轻松地管理和调度数据处理工作流。其本身支持容错和重运行失败任务,提供了可靠性、可重复性和可扩展性,使数据工程团队能够高效地处理大规模的数据任务。
Astronomer Cosmos 提供了标准化的接口,简化了在 Airflow 中集成和运行 DBT 任务的过程。整个解决方案的可维护性和可扩展性得到提高,有助于提升数据质量和生产力。
本篇作者

付鹏
亚马逊云科技解决方案架构师,负责基于亚马逊云计算方案架构的咨询和设计,推广亚马逊云平台技术以及亚马逊云科技的产品服务和各种解决方案。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9312
9312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









