







在当今快节奏世界,时间至关重要,就连采购食品这类基本任务也会让人感觉匆忙且充满挑战。尽管一心想要规划好膳食并据此采购,但最终往往还是会选择点外卖,导致未使用的易腐食品留在冰箱里白白浪费。这种看似不起眼的食物浪费问题,再加上杂货店丢弃的过期食品,对全球粮食浪费问题造成了重大影响。而亚马逊云科技生成式AI的力量,将有助于解决这一问题。
利用Amazon Rekognition的计算机视觉能力以及Amazon Bedrock提供的基础模型(FMs)的内容生成能力,亚马逊云科技开发了一项解决方案,该方案会根据您冰箱中的现有食材以及当地超市即将过期商品的库存,为您推荐食谱,确保家中和超市的食物都能得到充分利用,从而节省开支并减少浪费。
本文将介绍如何使用Amazon Rekognition Custom Labels,构建FoodSavr解决方案(本文中使用的是虚构名称)来检测食材,并利用Amazon Bedrock上的Anthropic Claude 3.0生成个性化食谱。这一解决方案为一个端到端的架构,用户只需上传一张冰箱的照片,系统就会基于Amazon Rekognition检测到的食材,通过Amazon Bedrock为用户生成一份食谱列表。此外,该架构还能识别缺少的食材,并为用户提供附近超市的列表。
Amazon Rekognition Custom Labels:
https://aws.amazon.com/rekognition/custom-labels-features/
解决方案概述
以下参考架构展示了如何使用Amazon Bedrock、Amazon Rekognition以及其他亚马逊云科技服务,来实现FoodSavr解决方案。
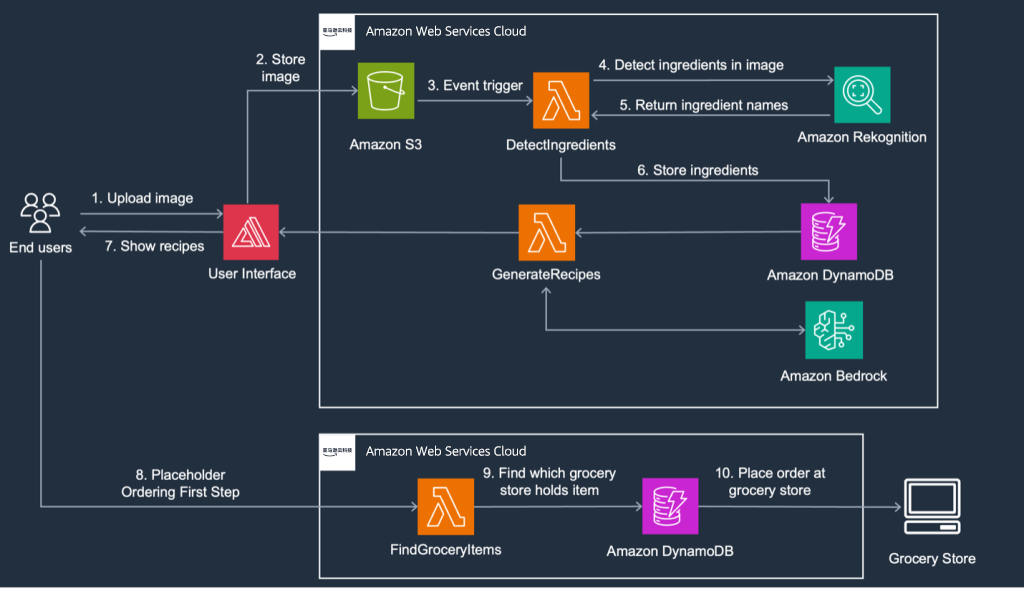
如上图所示,该解决方案架构包括以下步骤。
1.为打造端到端的解决方案,需要构建一个前端界面,以便用户可以在此上传其希望检测和标注的物品图片。有关在亚马逊云科技上部署前端的更多信息,请参阅《亚马逊云科技上的前端Web和移动应用》。
《亚马逊云科技上的前端Web和移动应用》
https://aws.amazon.com/products/frontend-web-mobile/
2.用户拍摄的图片将存储在Amazon S3中,该Amazon S3存储桶应配置生命周期策略,以便在使用后删除图片。有关Amazon S3生命周期策略的更多信息,请参阅《管理存储生命周期》。
《管理存储生命周期》
https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html
3.该架构使用了多个Amazon Lambda函数,Amazon Lambda是一种Serverless亚马逊云科技计算服务,可以运行事件驱动代码,并自动管理计算资源。第一个Lambda函数“DetectIngredients”通过使用Boto3 Python API,充分利用了Amazon Rekognition的功能,Amazon Rekognition是一项前沿计算机视觉服务,使用机器学习模型来分析上传的图像。
4.使用Amazon Rekognition Custom Labels,通过一组食材数据集来训练模型,您可以根据自己的用例采用此架构来使用Amazon Rekognition Custom Labels。借助经过训练、能够识别各种食材的自定义标签,Amazon Rekognition可以识别图像中的物品。
5.检测到的食材名称随后会安全存储在完全托管的NoSQL数据库服务Amazon DynamoDB表中,以便进行检索和修改。用户会看到一份已检测到的食材列表,并可选择添加其他食材或删除不需要或识别错误的食材。
6.用户在Web界面确认食材列表后,只需点击按钮,即可启动食谱生成过程。这一操作会调用另一个名为GenerateRecipes的Lambda函数,该函数利用了Amazon Bedrock API(本文为Anthropic的Claude v3)的高级语言功能。这一先进FM会分析从Amazon DynamoDB中检索到的已确认食材列表,并根据这些特定食材生成相关食谱。此外,该模型还会为每份食谱提供配图,从视觉上打造既吸引人眼球又富有启发性的烹饪体验。
7.Amazon Bedrock包含本例中使用到的两个关键FM:一是Anthropic的Claude v3(现已发布更新版本),用于生成食谱;二是Stable Diffusion,用于生成图像。在本解决方案中,您可以根据实际需求,使用任意组合FM。食谱文本和食谱图片等生成内容随后可以在前端展示给用户。
8.对于这一用例,您还可以设置一个可选的订购流程,允许用户订购FM所描述的食材。该流程由一个名为FindGroceryItems的Lambda函数作为前端,该函数可以在由当地超市提供的数据库中查找推荐食物商品,其中数据库包含即将过期的食材及其价格。
下文将深入探讨如何在自有账户中设置此解决方案架构。由于第8步是非必须的可选步骤,因此下文未予说明。
使用Amazon Rekognition检测图像
图像识别功能由Amazon Rekognition提供支持,该服务提供预训练和可定制的计算机视觉功能,让用户能够从图像中获取信息和洞察。为了实现可定制性,您可以使用Amazon Rekognition Custom Labels来识别图像中符合您业务需求的特定场景和对象。如果您的图像已经做好标注,则可以直接在Amazon Rekognition控制台开始训练模型,否则,您需要在Amazon Rekognition标注界面进行标注,或者使用Amazon SageMaker Ground Truth等其他服务。
Amazon SageMaker Ground Truth:
https://aws.amazon.com/sagemaker/groundtruth/
下图展示了在Amazon Rekognition标注界面上进行边框标注的过程示例。
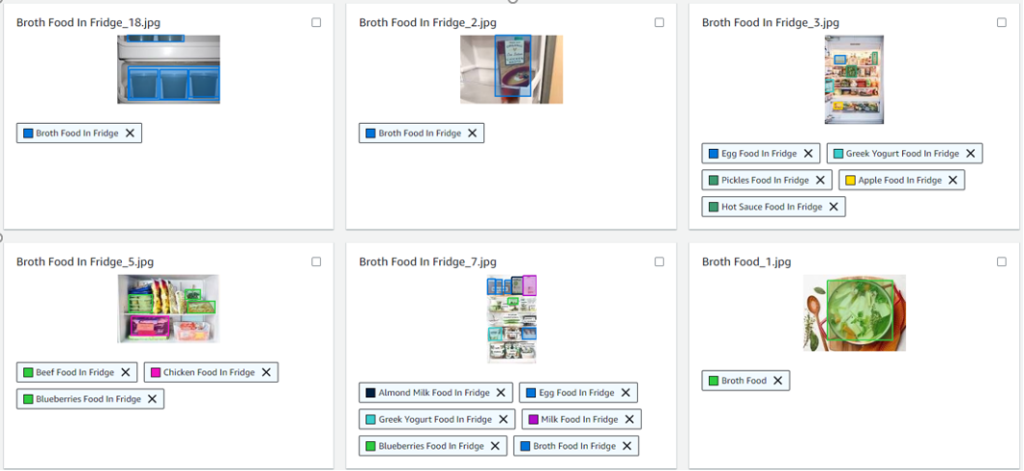
要开始标注,请参阅《使用Amazon Rekognition Custom Labels和Amazon A2I检测披萨片并增强预测》。在此架构中,本例收集了一个包含多达70张冰箱中常存放食品的图片数据集,建议您自己收集相关图片,并将其存储在Amazon S3存储桶中,以便用于训练Amazon Rekognition。
然后,您可以使用Amazon Rekognition Custom Labels创建带有食品名称的标签,并在图片上指定边界框,以便模型明确查看的位置。要开始训练自定义模型,请参阅《训练Amazon Rekognition Custom Labels模型》。
《使用Amazon Rekognition Custom Labels和Amazon A2I检测披萨片并增强预测》
https://aws.amazon.com/blogs/machine-learning/using-amazon-rekognition-custom-labels-and-amazon-a2i-for-detecting-pizza-slices-and-augmenting-predictions/
《训练Amazon Rekognition Custom Labels模型》
https://docs.aws.amazon.com/rekognition/latest/customlabels-dg/training-model.html
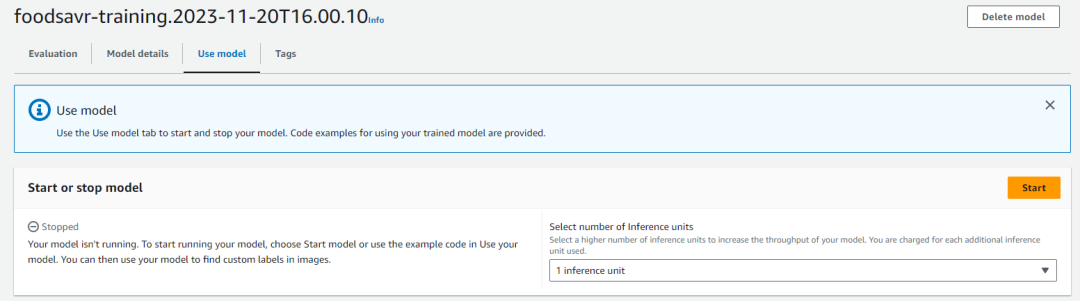
模型训练完成后,您可在亚马逊云科技管理控制台的Amazon Rekognition项目下看到所有已训练的模型,您还可以查看以F1分数衡量的模型性能,如下图所示。

您还可以对现有模型进行迭代和修改,以创建更新版本。使用模型之前,请确保其处于“已启动”状态。要使用模型,请选择想要使用的模型,然后在“使用模型”选项卡中选择“开始”。
您还可以选择以编程方式启动和停止模型,您可以从Amazon Rekognition控制台复制确切的API调用,以下内容仅作示例。
使用以下API调用(该API存在于Lambda函数中),来使用您的自定义标签和自定义模型检测图像中的食物。
aws rekognition detect-custom-labels \
--project-version-arn "MODEL_ARN" \
--image '{"S3Object": {"Bucket": "MY_BUCKET","Name": "PATH_TO_MY_IMAGE"}}' \
--region us-east-1左右滑动查看完整示意
为避免持续产生费用,您还可以在不使用模型时停止模型。
aws rekognition stop-project-version \
--project-version-arn "MODEL ARN \
--region us-east-1左右滑动查看完整示意
由于本例使用的是Python,所以本文中提到的所有API调用都是通过boto3 Python软件包来实现的。有关boto3的更多信息,请参阅Boto3文档。
启动模型可能需要几分钟时间。要查看模型的当前准备状态,请查看项目详细信息页面或使用DescribeProjectVersions命令,等待模型状态变为RUNNING。
Boto3文档:
https://pypi.org/project/boto3/
DescribeProjectVersions命令:
https://docs.aws.amazon.com/rekognition/latest/APIReference/API_DescribeProjectVersions
同时,您可以查看Amazon Rekognition提供的有关模型的各种统计数据,其中重要数据包括模型性能(F1分数)、精确度和召回率。这些统计数据由Amazon Rekognition在模型级别(如前文图片所示)和单个自定义标签级别(如下图所示)收集。
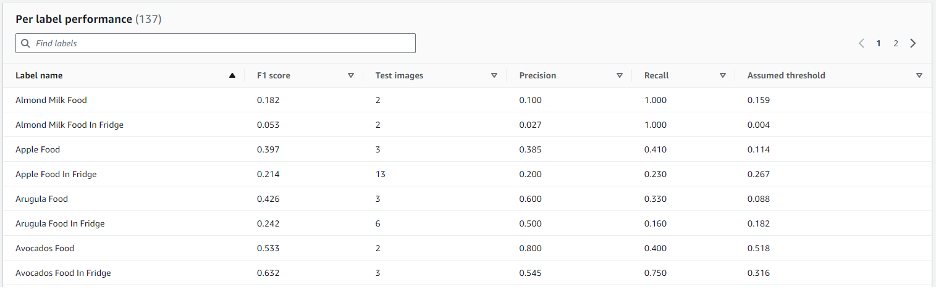
有关统计数据的更多信息,请参阅模型评估指标。
模型评估指标:
https://docs.aws.amazon.com/rekognition/latest/customlabels-dg/im-metrics-use.html
需要注意的是,尽管Anthropic的Claude模型在理解和生成基于文本和图像的内容方面,展现出了强大的多模态能力,但在此解决方案中,本例还是选择了使用Amazon Rekognition Custom Labels来进行成分检测。
Amazon Rekognition是一项专门优化的计算机视觉服务,使用的是在海量数据集上训练的先进模型,适用于物体检测和图像分类等任务。此外,Amazon Rekognition Custom Labels支持训练定制模型,以识别特定的食品和成分,提供了通用语言模型可能无法实现的定制化水平。而且,作为一项全托管服务,Amazon Rekognition可以无缝扩展,以处理海量图像。
虽然可以探索将Amazon Rekognition和Claude多模态功能相结合的混合方法,但本例之所以选择Amazon Rekognition Custom Labels,是因为其具备专门的计算机视觉功能、可定制性,并可针对此特定用例演示如何将Amazon Bedrock上的FM与其他亚马逊云科技服务相结合。
利用Amazon Bedrock基础模型生成食谱
本例使用Amazon Bedrock来生成食谱,这是一项提供高性能FM的全托管服务。通过Amazon Bedrock API查询Anthropic的Claude v3 Sonnet模型,使用以下提示为FM提供上下文。
You are an expert chef, with expertise in diverse cuisines and recipes.
I am currently a novice and I require you to write me recipes based on the ingredients provided below.
The requirements for the recipes are as follows:
- I need 3 recipes from you
- These recipes can only use ingredients listed below, and nothing else
- For each of the recipes, provide detailed step by step methods for cooking. Format it like this:
1. Step 1: <instructions>
2. Step 2: <instructions>
...
n. Step n: <instructions>
Remember, you HAVE to use ONLY the ingredients that are provided to you. DO NOT use any other ingredient.
This is crucial. For example, if you are given ingredients "Bread" and "Butter", you can ONLY use Bread and Butter,
and no other ingredient can be added on.
An example recipe with these two can be:
Recipe 1: Fried Bread
Ingredients:
- Bread
- Butter
1. Step 1: Heat up the pan until it reaches 40 degrees
2. Step 2: Drop in a knob of butter and melt it
3. Step 3: Once butter is melted, add a piece of bread onto pan
4. Step 4: Cook until the bread is browned and crispy
5. Step 5: Repeat on the other side
6. Step 6: You can repeat this for other breads, too左右滑动查看完整示意
以下代码是Amazon Bedrock API调用的主体部分。
# master_ingredients_str: Labels retrieved from DynamoDB table
# prompt: Prompt shown above
content = "Here is a list of ingredients that a person currently has." + user_ingredients_str + "\n\n And here are a list of ingredients at a local grocery store " + master_ingredients_str + prompt
body = json.dumps({
"max_tokens": 2047,
"messages": [{"role": "user", "content": content}],
"anthropic_version": "bedrock-2023-05-31"
})
j_body = json.dumps(body)
modelId = "anthropic.claude-3-sonnet-20240229-v1:0"
response = bedrock.invoke_model(body=body, modelId=modelId)左右滑动查看完整示意
通过结合提示词和API调用,本例使用从Amazon DynamoDB表中检索到的食材生成了三份食谱。您可以在请求主体中添加温度、top_p和top_k等其他参数,以进一步设置提示词阈值。有关使用Amazon Bedrock API从Anthropic的Claude 3模型获取响应的更多信息,请参阅Anthropic Claude Messages API。
Anthropic Claude Messages API:
https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-anthropic-claude-messages.html
建议将温度设置为较低的值(如0.1或0.2),以帮助确保食谱的生成具有确定性和结构性,以及将top_p值(核采样)设置为较高的值(如0.9),以便将FM的预测限制在最可能的tokens上(在这种情况下,模型将考虑其下一次预测中最可能占总概率质量90%的tokens)。top_k是另一种采样技术,它将模型的预测限制在top_k最可能的tokens上。例如,如果top_k=10,则模型在下一次预测中只会考虑10个最可能的tokens。
使用Amazon Bedrock的一大关键优势是,能够在同一解决方案针对不同任务使用多个FM。除了使用Anthropic的Claude 3生成文本食谱外,还可以动态生成吸引人的图像来搭配食谱。对于此项任务,选择Amazon Bedrock上的Stable Diffusion模型。Amazon Bedrock还提供了诸如Amazon Titan等其他强大的图像生成模型,同时也为您提供了相应的API调用示例。与使用Amazon Bedrock API从Anthropic的Claude 3生成响应类似,使用以下代码。
modelId = "stability.stable-diffusion-xl-v0"
accept = "application/json"
contentType = "application/json"
body = json.dumps({
"text_prompts": [
{
"text": recipe_name
}
],
"cfg_scale": 10,
"seed": 20,
"steps": 50
})
response = brt.invoke_model(
body = body,
modelId = modelId,
accept = accept,
contentType = contentType
)左右滑动查看完整示意
对于Amazon Titan模型,您可能会使用类似如下代码。
modelId="amazon.titan-image-generator-v1",
accept="application/json",
contentType="application/json"
body = json.dumps({
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text":prompt, # Required
},
"imageGenerationConfig": {
"numberOfImages": 1, # Range: 1 to 5
"quality": "premium", # Options: standard or premium
"height": 768, # Supported height list in the docs
"width": 1280, # Supported width list in the docs
"cfgScale": 7.5, # Range: 1.0 (exclusive) to 10.0
"seed": 42 # Range: 0 to 214783647
}
})
response = brt.invoke_model(
body = body,
modelId = modelId,
accept = accept,
contentType = contentType
)左右滑动查看完整示意
这会返回一个base64编码的字符串,您需要在前端对其进行解码以便显示。有关API调用中可包含的其他参数的更多信息,请参阅Stability.ai Diffusion 1.0文本转图像,以及使用Amazon Bedrock通过Titan图像生成器模型生成图像。下文将介绍如何在亚马逊云科技账户中部署此解决方案。
Stability.ai Diffusion 1.0文本转图像:https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-diffusion-1-0-text-image.html
使用Amazon Bedrock通过Titan图像生成器模型生成图像:https://community.aws/content/2b0jegE8XxfiueSGVYJFf6P50RX/using-amazon-bedrock-to-generate-images-with-titan-image-generator-models-and-aws-lambda?lang=en
准备条件
您需要拥有一个亚马逊云科技账户,来部署此解决方案,没有账户注册即可。本文中的说明使用的是us-east-1亚马逊云科技区域,请确保您在提供亚马逊云科技机器学习服务的区域中部署资源。
为了使Lambda函数成功运行,Amazon Lambda需要具有适当权限的Amazon IAM角色及策略。请按照从《使用执行角色定义Lambda函数权限》到为Lambda函数创建并附加Lambda执行角色的必要步骤操作,以便Lambda函数能够访问Amazon DynamoDB、Amazon Rekognition和Amazon Bedrock所需的所有操作。
注册亚马逊云科技账户:
https://docs.aws.amazon.com/SetUp/latest/UserGuide/setup-AWSsignup.html
《使用执行角色定义Lambda函数权限》
https://docs.aws.amazon.com/lambda/latest/dg/lambda-intro-execution-role.html
创建用于检测成分的Lambda函数
完成以下步骤,创建您的第一个Lambda函数(DetectIngredients)。
在Amazon Lambda控制台的导航窗格中选择“函数”。
选择“创建Lambda函数”。
选择“从头开始创建”。
将函数命名为“DetectIngredients”,运行时选择“Python 3.12”,然后选择“创建函数”。
在Amazon Lambda配置中,执行角色选择“lambdaDynamoRole”,将超时时间增加到8秒,确认设置后选择“保存”。
将Lambda函数代码中的文本替换为以下示例代码,然后选择“保存”。
import json
import boto3
import inference
import time
s3 = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('TestDataTable')
table_name = 'TestDataTable'
def lambda_handler(event, context):
clearTable()
test = inference.main()
labels, label_count = inference.main()
# The names array will contain a list of all the grocery ingredients detected
# in the image
names = []
for label_dic in labels:
name = label_dic['Name']
# Getting rid of unnecessary parts of label string
if "Food" in name:
# Remove "Food" from name
name = name.replace("Food", "")
if "In Fridge" in name:
# Remove "In Fridge" from name
name = name.replace("In Fridge", "")
name = name.strip()
names.append(name)
# Loop through the list of grocery ingredients to construct a dictionary called
# items
# the items dict will be used to batch write up to 25 items at a time when
# batch_write_all is called
items=[]
for name in names:
if (len(items)) < 29:
items.append({
'grocery_item': name
})
# Remove all duplicates from array
seen = set()
unique_grocery_items = []
for item in items:
val = item['grocery_item'].lower().strip()
if val not in seen:
unique_grocery_items.append(item)
seen.add(val)
batch_write_all(unique_grocery_items)
table.put_item(
Item={
'grocery_item': "DONE"
})
def batch_write_all(items):
batch_write_requests = [{
'PutRequest': {
'Item': item
}
} for item in items]
response = dynamodb.batch_write_item(
RequestItems={
table_name:batch_write_requests
}
)
def clearTable():
response = table.scan()
with table.batch_writer() as batch:
for each in response['Items']:
batch.delete_item(
Key={
'grocery_item': each['grocery_item']
}左右滑动查看完整示意
创建用于存储成分信息的DynamoDB表
完成以下步骤,创建DynamoDB表。
在Amazon DynamoDB控制台的导航窗格中选择“表”。
选择“创建表”。
在“表名称”中输入“MasterGroceryDB”。
在“分区键”中使用“grocery_item”(字符串)。
确认页面上的所有条目均准确无误,将其余设置保留为默认值,然后选择“创建”。
等待表创建完成且表状态变更为“活跃”后,再进行下一步操作。
创建用于调用
Amazon Bedrock的Lambda函数
完成以下步骤,创建另一个Lambda函数,该函数将调用Amazon Bedrock API来生成食谱。
在Amazon Lambda控制台的导航窗格中选择“函数”。
选择“创建函数”。
选择“从头开始创建”。
将函数命名为“GenerateRecipes”,运行时选择“Python 3.12”,然后选择“创建函数”。
在Amazon Lambda配置中,执行角色选择“lambdaDynamoRole”,将超时时间增加到8秒,确认设置后选择“保存”。
将Lambda函数代码中的文本替换为以下示例代码,然后选择“保存”。
import json
import boto3
import re
import base64
import image_gen
dynamodb = boto3.resource('dynamodb')
bedrock = boto3.client(service_name='bedrock-runtime')
def get_ingredients(tableName):
table = dynamodb.Table(tableName)
response = table.scan()
data = response['Items']
# Support for pagination
while 'LastEvaluatedKey' in response:
response = table.scan(ExclusiveStartKey=response['LastEvaluatedKey'])
data.extend(response['Items'])
data = [g_i for g_i in data if g_i['grocery_item'] != 'DONE']
return data
# Converts dynamoDB grocery items into a string
def convertItemsToString(grocery_dict):
ingredients_list = []
for each in grocery_dict:
ingredients_list.append(each['grocery_item'])
ingredients_list_str = ", ".join(ingredients_list)
return ingredients_list_str
def read_prompt():
with open ('Prompt.md', 'r') as f:
text = f.read()
return text
# Gets the names of all the recipes generated
def get_recipe_names(response_body):
recipe_names = []
for i in range(len(response_body)):
if response_body[i] == '\n' and response_body[i + 1] == '\n' and response_body[i + 2] == 'R':
recipe_str = ""
while response_body[i + 2] != '\n':
recipe_str += response_body[i + 2]
i += 1
recipe_str = recipe_str.replace("Recipe", '')
recipe_str = recipe_str.replace(": ", '')
recipe_str = re.sub(" \d+", "", recipe_str)
recipe_names.append(recipe_str)
return recipe_names
def lambda_handler(event, context):
# Write the ingredients to a .md file
user_ingredients_dict = get_ingredients('TestDataTable')
master_ingredients_dict = get_ingredients('MasterGroceryDB')
# Get string values for ingredients in both databases
user_ingredients_str = convertItemsToString(user_ingredients_dict)
master_ingredients_str = convertItemsToString(master_ingredients_dict)
# Convert dictionary into comma seperated string arg to pass into prompt
# Read the prompt + ingredients file
prompt = read_prompt()
# Query for recipes using prompt + ingredients
content = "Here is a list of ingredients that a person currently has." + user_ingredients_str + "\n\n And here are a list of ingredients at a local grocery store " + master_ingredients_str + prompt
body = json.dumps({
"max_tokens": 2047,
"messages": [{"role": "user", "content": content}],
"anthropic_version": "bedrock-2023-05-31"
})
j_body = json.dumps(body)
modelId = "anthropic.claude-3-sonnet-20240229-v1:0"
response = bedrock.invoke_model(body=body, modelId=modelId)
response_body = json.loads(response.get('body').read())
response_body_content = response_body.get("content")
response_body_completion = response_body_content[0]['text']
recipe_names_list = get_recipe_names(response_body_completion)
first_image_imgstr = image_gen.image_gen(recipe_names_list[0])
second_image_imgstr = image_gen.image_gen(recipe_names_list[1])
third_image_imgstr = image_gen.image_gen(recipe_names_list[2])
return response_body_completion, first_image_imgstr, second_image_imgstr, third_image_imgstr左右滑动查看完整示意
创建用于存储图像的
Amazon S3存储桶
最后,您需要创建Amazon S3存储桶来存储上传的图片,每次上传后该存储桶会自动调用DetectIngredients Lambda函数,请按照以下步骤创建存储桶并配置Lambda函数。
在Amazon S3控制台中,选择导航窗格中的“存储桶”。
选择“创建存储桶”。
输入一个唯一的存储桶名称,将所需区域设置为us-east-1,然后选择“创建存储桶”。
在Amazon Lambda控制台中,导航到“DetectIngredients”。
在“配置”选项卡中,选择“添加触发器”。
选择触发器类型为Amazon S3,并选择您创建的存储桶。
将事件类型设置为“所有对象创建事件”,然后选择“添加”。
在Amazon S3控制台中,导航到您创建的存储桶。
在“属性”和“事件通知”下,选择“创建事件通知”。
输入事件名称(例如,“触发DetectIngredients”),并将事件设置为“所有对象创建事件”。
对于“目标”,选择“Lambda函数”,然后选择DetectIngredients Lambda函数。
选择“保存”。
总结
本文探讨了如何在Amazon Bedrock上使用Amazon Rekognition和FM,结合Amazon Lambda和Amazon DynamoDB等亚马逊云科技服务,构建一个应对美国食品浪费问题的全面解决方案。通过利用Amazon Bedrock上的Amazon Rekognition Custom Labels和模型生成内容等前沿亚马逊云科技服务,该应用程序展示了其生成式AI能力的价值和实际应用效果。
后续将推出文章,继续介绍如何在Amazon Bedrock上使用如Anthropic的Claude v3.1等多模态功能的FM,端到端部署本文所述的解决方案,敬请关注!
尽管本文仅重点介绍了一项关于食品浪费的应用案例,但该架构具有高度的灵活性,可以让您将这些服务适配到多种不同用例,帮助您解决各种挑战。
本篇作者

Aman Shanbhag
亚马逊云科技机器学习框架团队助理专家解决方案架构师,负责帮助客户和合作伙伴大规模部署机器学习训练和推理解决方案。

Michael Lue
亚马逊云科技加拿大区高级解决方案架构师,常驻多伦多。Michael致力于与加拿大企业客户合作,通过优化、创新和现代化手段加速客户业务发展。他热衷于容器和人工智能与机器学习等颠覆性技术。

Vineet Kachhawaha
亚马逊云科技解决方案架构师,专长于机器学习领域。他负责帮助客户在亚马逊云科技上构建可扩展、安全且经济高效的工作负载。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9449
9449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









