







一、为什么要提出DPO
在之前,我们已经了解到基于人类反馈的强化学习RLHF分为三个阶段:全监督微调(SFT)、奖励模型(RM)、强化学习(PPO)。但是RLHF面临缺陷:RLHF 是一个复杂且经常不稳定的过程,首先拟合反映人类偏好的奖励模型,然后使用强化学习微调大型无监督 LM,以最大化这种估计奖励,而不会偏离原始模型太远。为解决这一问题,提出一个直接偏好优化 (DPO) 的新算法:通过利用奖励函数与最优策略之间的映射关系,证明这个受限的奖励最大化问题可以通过单阶段的策略训练来精确优化,本质上是在人类偏好数据上解决一个分类问题。DPO是稳定的、性能和计算成本轻量级的,无需拟合奖励模型,在微调期间从 LM 中采样,或执行显着的超参数调整。通过实验表明:DPO 进行微调超过了 RLHF 效果,并提高了摘要和单轮对话的响应质量。
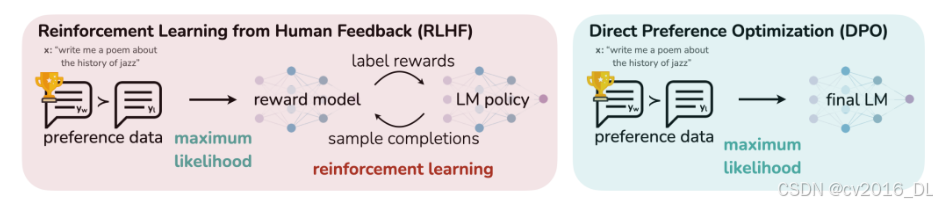
二、什么是DPO
DPO,一种基于人类偏好优化语言模型的新方法。与RLHF不同,DPO不依赖于明确的奖励建模或强化学习。它针对与RLHF相同的目标,但提供了一种更简单、更直接的培训方法。
DPO的工作原理:增加偏好样本的对数概率与减小非偏好样本响应的对数概率。它结合了动态加权机制,以避免仅使用概率比目标时遇到的模型退化问题。
DPO依赖于理论上的偏好模型,如Bradley-Terry模型,来测量奖励函数与经验偏好数据的对齐程度。与传统方法不同,传统方法使用偏好模型来训练奖励模型,然后基于该奖励模型训练策略,DPO直接根据策略定义偏好损失。给定一个关于模型响应的人类偏好数据集,DPO可以使用简单的二元交叉熵目标来优化策略,无需在训练过程中明确学习奖励函数或从策略中采样。具体推导见链接1
(1)原RLHF的优化目标:最大化奖励和最小化参考策略的KL散度
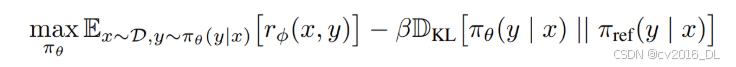
(2)DPO优化目标:利用了从奖励函数到最优策略的解析映射,允许直接使用人类偏好数据进行简化的优化过程
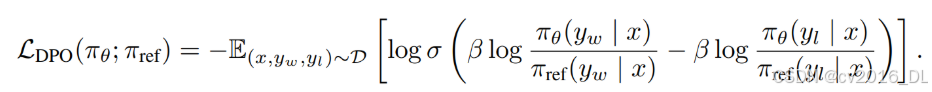
该目标增加了对偏好数据yw的可能性,并减少了非偏好数据yl的可能性。这些示例按照隐式奖励模型的评级加权,由β缩放.
DPO重参数化等效于具有隐式奖励函数:

参数模型πθ的优化等效于在此变量更改下的奖励模型优化。
(3)DPO在干什么?
为了从原理上理解 DPO,分析损失函数的梯度。 相对于参数 θ 的梯度可以写为:

 (4)DPO outline
(4)DPO outline

步骤1)是在构造数据集&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









