




1. 前言
大型语言模型(LLM)的预训练效果在很大程度上取决于训练数据的质量和预处理方法。OpenWebText数据集作为一个广泛使用的公开语料库,为LLM的预训练提供了宝贵的资源。然而,原始的OpenWebText数据集来源于网络抓取,不可避免地包含噪声、冗余信息以及格式不一致等问题。为了训练出高性能的LLM,并为了后续采用字节对编码(BPE)方式构建高效的词表,对OpenWebText数据集进行恰当的清洗至关重要。
2. OpenWebText数据集概述
OpenWebText是一个开源的、旨在复现OpenAI的WebText语料库的数据集。其数据主要来源于Reddit上分享的、至少获得3个“upvotes”(点赞)的URL链接内容。这个数据集的原始大小约为38GB。由于其来源的多样性和内容的广泛性,OpenWebText被广泛应用于语言建模、文本生成和文本分类等任务。例如,RoBERTa模型的预训练就使用了OpenWebText数据集。
尽管OpenWebText致力于提供高质量的网络文本数据,但作为网络抓取数据的固有特性,它仍然面临一些质量问题。这些问题包括但不限于:
-
HTML标签和脚本残留:网页原始内容可能包含大量HTML、JavaScript和CSS代码,这些非文本内容对于语言模型训练是有害的。
-
样板内容 (Boilerplate Content):例如网站的导航栏、页眉、页脚、版权声明等重复性内容。
-
格式问题与编码错误:文本可能包含不一致的编码、特殊字符、过多的空白符或不规范的标点符号。
-
低质量文本:例如自动生成的文本、意义不连贯的片段、过短或过长的无效文档。
-
重复内容:完全相同或高度相似的文档或段落。
-
个人身份信息(PII)和敏感内容:可能包含个人隐私信息或不适宜模型学习的有害内容。
这些问题的存在会直接影响BPE词表的质量和LLM的训练效果。例如,HTML标签会污染词表,增加不必要的词条;重复内容会使模型对特定模式过拟合,降低泛化能力。因此,细致的数据清洗是预训练准备工作中不可或缺的一环。学术界和开源社区已经针对大规模网络语料的清洗提出了多种方法和流程,例如C4、The Pile、OSCAR等数据集的清洗流程中都包含了针对上述问题的处理步骤。
3. 数据清洗方案
为OpenWebText数据集设计一个最佳的清洗方案,需要综合考虑数据质量、计算效率以及对后续BPE分词和LLM训练的影响。以下是一个推荐的多阶段清洗流程,会附带一些片段式的处理代码,如果需要完整的代码可以通过访问文末的github链接进行获取。
3.1 初始准备和格式转换
-
数据获取:OpenWebText数据集可以通过Hugging Face Datasets库方便地获取。例如,使用load_dataset("openwebtext")。
-
格式统一:虽然OpenWebText在Hugging Face上通常是以文本形式提供,但如果从其他来源获取或处理中间结果,建议统一为逐行JSON (JSONL) 格式。每行一个JSON对象,包含至少一个"text"字段存储文档内容,以及可选的元数据字段(如"url", "timestamp"等)。这种格式便于流式处理和分布式计算。
3.2 HTML清洗
由于OpenWebText来源于网页,首要任务是移除HTML标签、JavaScript脚本、CSS样式以及其他非文本内容。
HTML解析与内容提取:
-
BeautifulSoup: 一个广泛使用的Python库,能够有效解析HTML和XML,并提取文本内容 。可以使用其.get_text()方法提取纯文本,并通过decompose()移除特定标签(如<script>, <style>)。
-
Trafilatura: 这是一个更专注于从网页中提取主要内容和元数据的工具,通常能更好地处理广告、导航栏等样板内容 。
-
BoilerPy3: Python实现的Boilerpipe库,专门用于去除HTML中的样板内容并提取正文 。ArticleExtractor适用于新闻类文章,而OpenWebText内容多样,可能需要评估其普适性或结合其他方法。
-
方法选择:对于OpenWebText,可以优先考虑Trafilatura或BoilerPy3进行主要内容提取,然后使用BeautifulSoup进行补充清理,实际实践中发现使用Trafilatura提取有时候出现无法提取的情况,因此使用BeautifulSoup作为补充清理很有必要。一个实际的考量是,虽然完全剥离HTML结构对于某些下游任务(如问答)可能影响不大 ,但对于预训练LLM,保留段落结构(例如通过换行符)通常是有益的。因此,提取文本时应注意保留适当的换行。
参考的代码实现如下:
def remove_html(text):
# 尝试使用 trafilatura,如果失败或结果为空,则用BeautifulSoup
extracted_text = trafilatura.extract(text, include_comments=False, include_tables=False, output_format='txt')
if extracted_text and extracted_text.strip():
return extracted_text
# 回退到BeautifulSoup
soup = BeautifulSoup(text, "lxml")
return soup.get_text()
3.3 文本规范化
文本规范化旨在消除文本中的不一致性,减少词表大小,并提高BPE分词的效率和一致性。
3.3.1 Unicode规范化
-
使用ftfy库修复常见的Unicode错误,例如Mojibake(乱码)。ftfy.fix_text()是一个常用的函数。
-
应用NFKC(Normalization Form Compatibility Composition)规范化 。NFKC会进行兼容性分解,然后进行规范组合,有助于将视觉上相似但编码不同的字符统一起来(例如,将全角数字转换为半角数字)。这可以通过Python的unicodedata.normalize('NFKC', text)实现。
参考的代码实现如下:
# Unicode标准化
text = ftfy.fix_text(text=text)
text = unicodedata.normalize('NFKC', text)
3.3.2 大小写处理 (Case Handling)
-
对于通用英文LLM预训练,如果计算资源和词表大小允许,保留原始大小写或采用更智能的Truecasing(将文本转换为最可能的大小写形式,通常用于恢复非规范文本的大小写)通常是更优的选择,因为它能让模型学习到大小写的细微差别 。然而,如果目标是更小的词表和更快的训练,并且下游任务对大小写不敏感,那么将字所有内容转换成小写是个不错的选择。因为训练资源的原因,所以这里我们还是先统一转换成小写处理。
参考的代码实现如下:
# 大小写转换 (转为小写)
text = text.lower()
3.3.3 移除多余空白符
-
移除行首行尾空白、连续多个空格或换行符替换为单个等
参考的代码实现如下:
# 移除开头连续出现的点号和空白字符
text = re.sub(r'^[\s.]+', '', text)
3.3.4 标点、字词处理
-
通常建议保留标点符号,因为它们承载重要的句法和语义信息。
-
可以考虑规范化标点,例如将不同类型的引号统一,或在标点和单词之间添加/确保空格(这通常由分词器处理)。过度移除标点会损害文本的自然度,并可能影响BPE的合并效果。
-
严格的处理方式,还可以选在只保留需要的字符,例如我们当前只希望使用英文预料进行训练,因此可以只保留英文相关的内容。
参考的代码实现如下:
def normalize_char(text):
# a. 字符白名单:移除不在预定义集合中的字符。
# 将不希望的字符替换为空格
text = re.sub(r'[^a-z0-9\s\.,!?;:\'\"\(\)&\+\#\@\_\%\/-]', ' ', text)
# b. 处理重复标点:将连续的多个相同标点符号规范化。
# 例如:"!!!!" -> "!", "..." -> " ... "
# 移除开头连续出现的点号和空白字符
text = re.sub(r'^[\s.]+', '', text)
# 例如: hello,,,world -> hello, world
text = re.sub(r'\s*([,.!? জানে;:"])\1{2,}\s*', r'\1 ', text)
# 标准化省略号,例如 "..." 或 ". . ." 替换为 "..."
text = re.sub(r'\s*(\.\s*){3,}\s*', '...', text)
# c. 处理特定重复的特殊字符序列,例如过长的破折号或下划线
text = re.sub(r'(-)\1{2,}', r'\1\1', text)
text = re.sub(r'(_)\1{2,}', r'\1\1', text)
return text
3.5 去重
去重是减少数据冗余、提升模型泛化能力和训练效率的关键步骤
3.5.1 精确去重 (Exact Deduplication)
移除完全相同的文档。可以通过计算文档的哈希值(如SHA256)并存储已见哈希集合来实现。
3.5.2 近似去重 (Near-Deduplication)
移除内容高度相似的文档。
-
MinHashLSH: MinHash (最小哈希) 结合LSH (Locality Sensitive Hashing, 局部敏感哈希) 是一种常用的近似去重方法。基本流程:
-
1. 将文档分割成shingles (例如,连续的5个词或字符)。
-
2. 对每个文档的shingle集合计算MinHash签名。
-
3. 使用LSH将具有相似MinHash签名的文档分到同一个桶中。
-
4. 在同一个桶内的文档对之间计算Jaccard相似度或其他相似度度量。
-
5. 移除相似度超过预设阈值(例如0.8, 0.85或0.9)的文档中的一个。
-
-
Python的datasketch库提供了MinHash和MinHashLSH的实现 。
-
去重粒度:可以在文档级别、段落级别甚至句子级别进行去重。C4数据集在三句话的窗口上应用去重 。OpenGPT-X对Web数据使用MinHashLSH进行文档级去重 。对于OpenWebText,文档级近似去重是必要的。
参数选择:MinHashLSH的参数(如shingle大小、哈希函数数量、LSH的bands和rows数量、相似度阈值)需要根据数据集特性和计算资源进行调整 。阈值设置得过高可能漏掉一些近似重复,设置得过低可能错误地移除内容相似但实际不同的文档。
性能要求:需要多数据集中所有的文件计算hash,因此数据集越大需要计算的hash就越多,而且在hash匹配的时候,是逐个和数据集中所有的hash进行匹配,因此会需要较大的内存。32G RAM + 32G Swap 实测可以完成OpenWebText数据集的去重(别问我为什么会知道这个.......)。
代码较多,因为篇幅原因。这里就不贴出来了,具体可以参考文末的GitHub链接。
3.6 其他清洗步骤
个人身份信息 (PII) 和敏感内容移除
-
虽然OpenWebText声称移除了PII,但作为额外的安全措施,可以运行PII检测工具(如基于正则表达式的、或更高级的基于模型的工具如Presidio或NVIDIA NeMo Curator中的PII模块 )来进一步识别和移除或脱敏PII(如姓名、电话号码、邮箱地址、IP地址等)。
-
对于有害或毒性内容,可以使用基于关键词列表的过滤或训练专门的毒性分类器进行移除。RefinedWeb使用了包含460万URL的黑名单和不安全词列表进行过滤。
这里我的处理就只移除了URL以及邮箱地址。参考代码如下

# 移除URLs和Email地址
text = re.sub(r'https?://\S+|www\.\S+', '', text) # 移除URL
text = re.sub(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b', '', text) # 移除Email
3.7 清洗总结
数据清洗的每一个步骤都会直接或间接地影响后续的BPE词表训练和最终的LLM性能:
-
HTML和样板内容移除:显著减小原始文本大小,防止词表中出现大量无意义的HTML标签或重复的导航词汇,使词表更专注于有意义的语言单元。
-
Unicode规范化和大小写处理:确保字符表示的一致性。小写化会合并大小写形式相同的词,减小词表,但可能丢失信息。保留大小写则相反。NFKC规范化有助于统一视觉上相似的字符,减少词表冗余。这些选择直接影响BPE算法在合并字符对时的频率统计和合并决策。
-
去重:防止高频重复内容主导BPE的合并过程,确保词表的多样性,避免模型对特定重复模式的过度敏感。
-
PII:移除PII确保了数据安全和隐私。
一个精心清洗的数据集将产生一个更小、更有效、更能代表目标语言的BPE词表。这反过来又能提高LLM的训练效率(因为输入序列通常更短,词嵌入更精确)和性能(因为模型学习的是更干净、更相关的语言模式)。研究表明,即使是token级别的清洗,过滤掉与任务无关的、冗余的token,也能提升下游任务表现。
4. 数据存储
清洗后的数据集需要以适合LLM预训练和BPE词表构建的格式进行保存。
4.1 原始文本文件(.txt)
-
优点:简单,易于处理,许多BPE训练工具直接支持纯文本文件输入。
-
缺点:对于大规模数据集,单个大文本文件不便于管理和并行处理。元数据(如文档来源)不易保存。
-
适用场景:可以直接将所有清洗后的文档内容连接成一个或多个大型.txt文件,每个文档之间用特殊分隔符(如\n\n或自定义的文档结束标记)隔开。这是训练SentencePiece BPE词表时常用的输入格式。
4.2 逐行JSON (JSONL)
-
优点:每行一个独立的JSON对象,非常适合流式处理和分布式计算框架(如Apache Spark)。可以方便地存储文本内容和相关元数据 。Hugging Face datasets库能很好地处理JSONL文件。
-
缺点:相比纯文本,JSON结构会增加一些存储开销。
-
适用场景:推荐作为中间存储格式,尤其是在多步骤清洗流程中,或者当需要保留文档级元数据时。最终用于BPE训练时,可以轻易地从JSONL中提取文本内容到.txt文件。
4.3 Apache Parquet / Apache Arrow
-
优点:
-
1. 列式存储:Parquet是列式存储格式,对于只选择特定字段(如"text"字段)进行操作时非常高效。
-
2. 压缩效率高:支持多种压缩算法(如Snappy, Gzip),能显著减小存储空间。
-
3. I/O性能好:尤其对于大规模数据集,Parquet的读取性能通常优于文本格式。
-
4. Schema支持与演化:Parquet支持Schema定义,有利于数据一致性和后续的扩展 。
-
5. 与大数据生态集成良好:广泛被Spark, Pandas, Dask等框架支持。Hugging Face datasets库也原生支持Parquet。
-
6. Apache Arrow是一种内存列式数据格式,常与Parquet结合使用,用于实现高效的数据读写和跨系统数据交换 。Hugging Face datasets在底层可能使用Arrow来加速数据处理。
-
-
缺点:直接作为BPE训练工具的输入可能不如纯文本方便,通常需要一个额外的步骤将文本数据从Parquet中提取出来。
-
适用场景:强烈推荐用于存储最终清洗完成的大规模数据集,特别是当数据集需要长期存储、共享或在分布式环境中进行进一步处理时。对于LLM预训练,可以直接从Parquet文件高效加载数据。
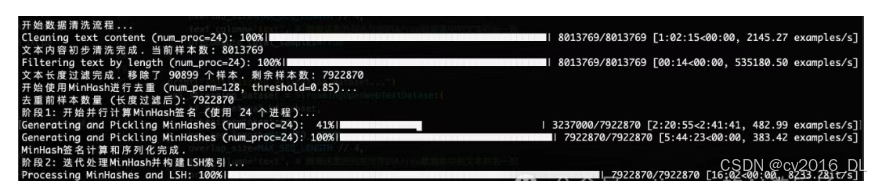
清洗过程的日志信息:
5. 总结
为大型语言模型(如基于OpenWebText训练并使用BPE词表的模型)准备高质量的预训练数据是一项复杂但至关重要的任务。涵盖了从初始数据准备到具体清洗步骤(包括HTML和代码处理、文本规范化、多维度质量过滤、精确及近似去重、PII处理等)。对数据的处理逻辑是通用的,总结出一套逻辑清晰的清洗方案之后,就可以直接将清洗方案迁移到其他数据集上了。
最后PS:然后情况就是,如大家所见,清洗完之后的数据集仍然有30+ GB大小。但是在训练我们这个小参数量的大模型的时候是不可能使用这么多的,后续会进行抽样,然后使用抽样后的数据集进行训练。既然要抽样,为什么不在一开始就先抽样,然后清洗。大概还是需要体验下大型数据集清洗的流程和时间,还有后续在训练BPE的时候,还是会使用整个数据集进行训练的。
一个数据集抽样脚本如下:
import os
from datasets import load_from_disk, Dataset, Features # Dataset 和 Features 用于处理空数据集情况
# --- 配置参数 ---
# 输入:原始完整数据集的路径
FULL_DATASET_PATH = "openwebtext_arrow_dataset/train"# 修改为你的完整数据集路径
# 输出:分割后数据集的保存位置
OUTPUT_BASE_DIR = "split_openwebtext_custom_sample"# 输出目录的名称
TRAIN_DATASET_OUTPUT_PATH = os.path.join(OUTPUT_BASE_DIR, "train")
VALIDATION_DATASET_OUTPUT_PATH = os.path.join(OUTPUT_BASE_DIR, "validation")
TRAIN_SAMPLE_PERCENTAGE = 0.03# 例如:3% 的总数据用于训练,可自行调整
VALIDATION_SAMPLE_PERCENTAGE = 0.005# 例如:0.5% 的总数据用于验证,可自行调整
# 剩余的 (1.0 - TRAIN_SAMPLE_PERCENTAGE - VALIDATION_SAMPLE_PERCENTAGE) 的数据将不会被使用
# 用于打乱的随机种子,确保结果可复现
RANDOM_SEED = 77
# 日志文件
LOG_FILE = 'logs/dataset_custom_splitting_log.txt'
# 设置 TOKENIZERS_PARALLELISM 以避免 huggingface tokenizers 的一些并行处理警告
os.environ["TOKENIZERS_PARALLELISM"] = "false"
deflog_message(message):
"""将消息记录到控制台和日志文件"""
print(message)
withopen(LOG_FILE, "a", encoding="utf-8") as f:
f.write(message + "\n")
defcreate_empty_dataset_with_schema(schema: Features):
"""根据给定的 schema 创建一个空的 Hugging Face Dataset"""
empty_data = {name: [] for name in schema.keys()}
return Dataset.from_dict(empty_data, features=schema)
defmain():
# --- 1. 初始化设置 ---
if os.path.exists(LOG_FILE):
os.remove(LOG_FILE) # 清除旧日志
os.makedirs(TRAIN_DATASET_OUTPUT_PATH, exist_ok=True)
log_message(f"训练数据集将保存到: {TRAIN_DATASET_OUTPUT_PATH}")
os.makedirs(VALIDATION_DATASET_OUTPUT_PATH, exist_ok=True)
log_message(f"验证数据集将保存到: {VALIDATION_DATASET_OUTPUT_PATH}")
log_message(f"配置信息:")
log_message(f" 完整数据集路径: {FULL_DATASET_PATH}")
log_message(f" 输出主目录: {OUTPUT_BASE_DIR}")
log_message(f" 训练集抽样百分比: {TRAIN_SAMPLE_PERCENTAGE*100:.2f}%")
log_message(f" 验证集抽样百分比: {VALIDATION_SAMPLE_PERCENTAGE*100:.2f}%")
log_message(f" 随机种子: {RANDOM_SEED}")
# --- 2. 验证百分比设置 ---
ifnot (0.0 <= TRAIN_SAMPLE_PERCENTAGE <= 1.0):
log_message(f"错误: TRAIN_SAMPLE_PERCENTAGE ({TRAIN_SAMPLE_PERCENTAGE}) 必须在 0.0 和 1.0 之间。")
return
ifnot (0.0 <= VALIDATION_SAMPLE_PERCENTAGE <= 1.0):
log_message(f"错误: VALIDATION_SAMPLE_PERCENTAGE ({VALIDATION_SAMPLE_PERCENTAGE}) 必须在 0.0 和 1.0 之间。")
return
total_requested_percentage = TRAIN_SAMPLE_PERCENTAGE + VALIDATION_SAMPLE_PERCENTAGE
if total_requested_percentage > 1.0:
log_message(f"错误: 训练集和验证集的总百分比 ({total_requested_percentage*100:.2f}%) 不能超过 100%。")
return
unused_percentage = 1.0 - total_requested_percentage
# 使用一个小的 epsilon 来比较浮点数
if unused_percentage > 1e-6: # 1e-6 是一个小的容差值
log_message(f"提示: 数据集中将有 {unused_percentage*100:.2f}% 的数据未被用于训练或验证。")
# --- 3. 加载完整数据集 ---
log_message(f"开始从以下路径加载完整数据集: {FULL_DATASET_PATH}")
try:
full_hf_dataset = load_from_disk(FULL_DATASET_PATH)
except Exception as e:
log_message(f"错误: 从 '{FULL_DATASET_PATH}' 加载数据集失败。异常: {e}")
log_message("请确保路径正确且包含有效的 Hugging Face Arrow 数据集。")
return
dataset_len = len(full_hf_dataset)
log_message(f"完整数据集加载成功。文档总数: {dataset_len}")
log_message(f"数据集特征: {full_hf_dataset.features}")
if dataset_len == 0:
log_message("加载的数据集为空。将创建空的训练集和验证集。")
# 获取原始数据集的 schema 以创建空的、结构相同的 Dataset 对象
schema = full_hf_dataset.features
train_subset = create_empty_dataset_with_schema(schema)
validation_subset = create_empty_dataset_with_schema(schema)
else:
# --- 4. 打乱并分割数据集 ---
log_message(f"使用随机种子 {RANDOM_SEED} 打乱数据集...")
# .shuffle() 返回一个新的 Dataset 对象,其中包含一个打乱的索引映射
shuffled_dataset = full_hf_dataset.shuffle(seed=RANDOM_SEED)
# 计算训练集和验证集的样本数量
# 使用 int() 进行截断取整,这与 datasets.train_test_split 计算数量的方式类似
num_train_samples = int(dataset_len * TRAIN_SAMPLE_PERCENTAGE)
num_val_samples = int(dataset_len * VALIDATION_SAMPLE_PERCENTAGE)
log_message(f"计算得到的训练样本数: {num_train_samples} "
f"(目标: {TRAIN_SAMPLE_PERCENTAGE*100:.2f}% / {dataset_len} 条)")
log_message(f"计算得到的验证样本数: {num_val_samples} "
f"(目标: {VALIDATION_SAMPLE_PERCENTAGE*100:.2f}% / {dataset_len} 条)")
# 确保选取的总样本数不超过数据集总长度
# (这一步主要用于防止极小概率的浮点数问题,理论上之前的百分比检查已覆盖)
if num_train_samples + num_val_samples > dataset_len:
log_message(f"警告: 计算的训练样本数 ({num_train_samples}) + 验证样本数 ({num_val_samples}) "
f"总和为 {num_train_samples + num_val_samples}, 超过了数据集总长度 ({dataset_len})。")
log_message(f"这可能指示百分比计算或极小数据集的问题。将尝试调整验证集数量。")
# 优先保证训练集数量,然后调整验证集数量
num_val_samples = dataset_len - num_train_samples
if num_val_samples < 0: # 如果训练集本身就超了(理论上不可能发生)
num_val_samples = 0
num_train_samples = dataset_len
log_message(f"调整后的验证样本数: {num_val_samples}")
log_message("选取训练子集...")
train_indices = range(num_train_samples)
train_subset = shuffled_dataset.select(train_indices)
log_message("选取验证子集...")
# 验证集的索引起始于训练集索引之后
validation_start_index = num_train_samples
validation_end_index = num_train_samples + num_val_samples
validation_indices = range(validation_start_index, validation_end_index)
validation_subset = shuffled_dataset.select(validation_indices)
log_message(f"实际训练子集大小: {len(train_subset)} 条文档。")
log_message(f"实际验证子集大小: {len(validation_subset)} 条文档。")
# --- 5. 保存分割后的数据集 ---
log_message(f"开始保存训练数据集到: {TRAIN_DATASET_OUTPUT_PATH}")
try:
train_subset.save_to_disk(TRAIN_DATASET_OUTPUT_PATH)
log_message("训练数据集保存成功。")
except Exception as e:
log_message(f"错误: 保存训练数据集失败。异常: {e}")
return
log_message(f"开始保存验证数据集到: {VALIDATION_DATASET_OUTPUT_PATH}")
try:
validation_subset.save_to_disk(VALIDATION_DATASET_OUTPUT_PATH)
log_message("验证数据集保存成功。")
except Exception as e:
log_message(f"错误: 保存验证数据集失败。异常: {e}")
return
log_message("\n--- 数据集自定义分割与保存流程完成 ---")
log_message(f"训练数据已保存至: {os.path.abspath(TRAIN_DATASET_OUTPUT_PATH)}")
log_message(f"验证数据已保存至: {os.path.abspath(VALIDATION_DATASET_OUTPUT_PATH)}")
num_actually_used = len(train_subset) + len(validation_subset)
num_unused = dataset_len - num_actually_used
if num_unused > 0 :
log_message(f"原始数据集中有 {num_unused} 条文档未被使用。")
elif dataset_len > 0and num_actually_used < dataset_len : # 处理因int()取整导致的小差异
log_message(f"由于取整,原始数据集中有 {num_unused} 条文档未被使用。")
if __name__ == '__main__':
main()
附录
GitHub链接:https://github.com/JimmysAIPG/MiniLLMs


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









