




在当前,使用强化学习(RL)对一个预训练的大模型进行后训练受到了越来越多的关注。
在本文中,笔者简单总结了一下较为有代表性的相关工作,将 RL + LLM 的算法分成大致以下三种工作,分别做简要的介绍,供大家分享交流。
-
Reject Sampling 类
-
Policy Gradient 类
-
RL + LLM 的工程实现(Infra)
1.基础记号
首先,为了方便后续介绍各类算法,我们先来约定一些通用的记号:
-
π_ref(x_i|x_1,...,x_i-1):在给定输入 tokens x_1,...x_i-1 下,输出 x_i 这一 token 的概率。这里的 ref 表示参考模型,通常指在进行 RL 之前的预训练 LLM。一般起到约束更新、正则化的作用。
-
π_θ(·):指使用 RL 训练的 LLM,θ 是可训练参数。
-
r(x):指奖励函数,用于评价 token 序列 x 有多好。
2.Reject Sampling 类
(1)标准 Reject Sampling
核心思想:通过奖励函数挑选出模型生成的回复中好的部分,并监督模型自己学习
具体步骤:
-
针对训练集,使用 π_ref 多次随机采样,生成大量的数据
-
对于每个训练样本,使用奖励函数 r(x)挑选出最好的一个或几个回复,并加入新的训练数据集
-
全部生成完毕之后,在新的训练数据集上 SFT
(2)Iterative Reject Sampling
核心思想:在标准版的基础上,迭代式地生产数据、学习数据
具体步骤:
-
针对训练集,使用 π_ref 多次随机采样,生成大量的数据
-
对于每个训练样本,使用奖励函数 r(x)挑选出最好的一个或几个回复,并加入新的训练数据集
-
生成完毕之后,在新的训练数据集上 SFT
-
将 π_ref 设置为 π_θ,转 1
(3)RAFT++
核心思想:
-
利用强化学习中的重要性采样(IS)思想;
-
利用了 PPO 中 clip 的思想,不让更新的后的模型偏离原始模型太远。
具体步骤:修改了学习高分数据的损失函数 SFT 损失函数:
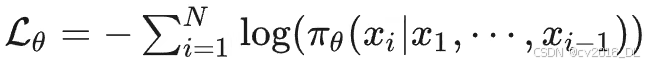
由此求导可得:
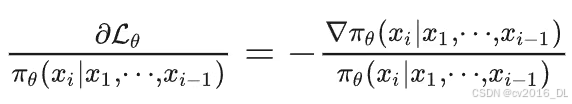
RAFT ++ 损失函数:
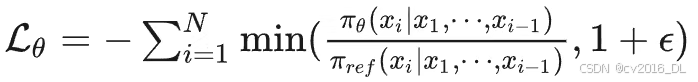
看着复杂,由此求导可得:
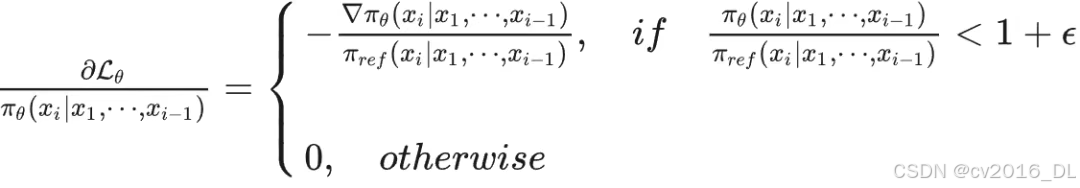
对比 SFT 的求导结果,发现两点:
-
如果新旧模型输出概率比值太大,就不更新(用于约束不要更新偏离太远)
-
梯度下方的系数不一样
重要性采样,在 TRPO 中首次引入,具体理论可以参考:
https://zhuanlan.zhihu.com/p/606954674
3.Policy Gradient 类
(1)REINFORCE
也称 policy gradient 算法,是强化学习最经典的方法。
具体损失函数:
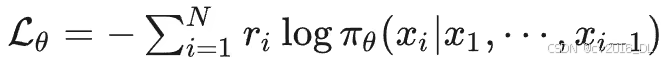
直观意义:最大化奖励函数值,以及对应输出的 token x_1
具有非常完善的数学理论支持。理论上讲,只要 batch size 足够大 + 优化算法足够好,就一定能找到最优解。
存在的问题:梯度的方差太大。采样获得的奖励函数可能非常不稳定,需要太大的 batch size 才能稳定得到梯度期望。可以考虑让奖励函数 r_i,在优化时,减去一个基线函数 b_i。
可以证明:当基线函数取“从当前 token i 开始采样,得到的平均奖励函数”时,可以证明可以最大幅度地减小方差,并且保证对梯度的估计仍然是无偏的。
A2C 中提出,中文版简要证明参考:
https://github.com/opendilab/PPOxFamily/blob/main/chapter1_overview/chapter1_supp_a2c.pdf
对数据的利用程度不高。采样得到的样本不能多次利用、更新模型。
现在 LLM 的视角:
-
LLM 的奖励函数往往方差没有那么大
-
只要对 REINFORCE 做一些改进,仍然有很大的使用价值(具体改进方法见后文)
(2)ReMax
基于 Policy Gradient 的改进,利用了减均值(使用贪心解码的奖励函数估计)的方式来减小梯度的方差
具体损失函数: REINFORCE(假设对同一个问题采样了 G 个回答)
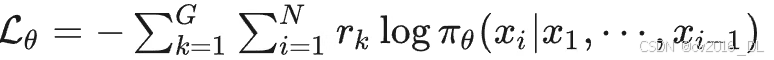
ReMax 对应的改进:
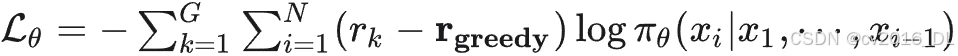
其中 r_greedy 指的是使用贪心解码得到的回复,所得到的奖励函数值。
这样一来可以顺利减小梯度的方差:
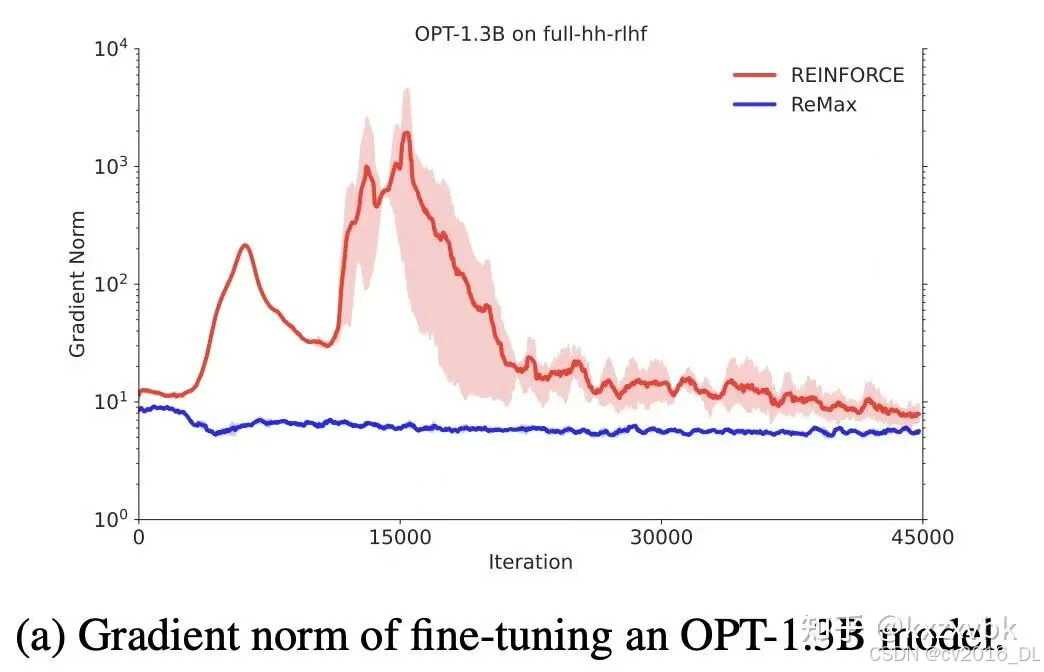
仍然需要注意的是,这样会让梯度的估计具有偏差(有偏估计)。
(3)RLOO
仍然是对 Policy Gradient 对改进,利用了减均值(使用 leave-one-out 估计)的方式来减小梯度的方差。
具体损失函数:
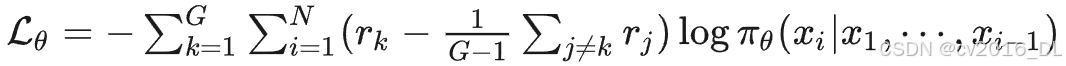
本质是拿同组的其他奖励的均值来作为均值的估计(leave one out),这个操作和 GRPO 里面减均值的操作已经非常接近了,仍然是减小方差,但可能引入偏差的方法。
(4)GPG
仍然是对 Policy Gradient 对改进,类似于熟知的 GRPO 算法,利用了减均值 + 除以标准差的方式,对奖励进行标准化
具体损失函数:
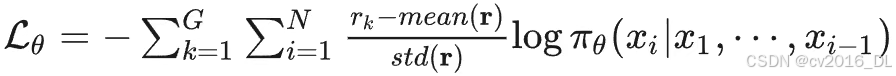
仍然是减小方差,但可能引入偏差的方法。
(5)PPO
是最经典的 RL 算法之一,是对 REINFORCE 的终极改进。
具体损失函数:
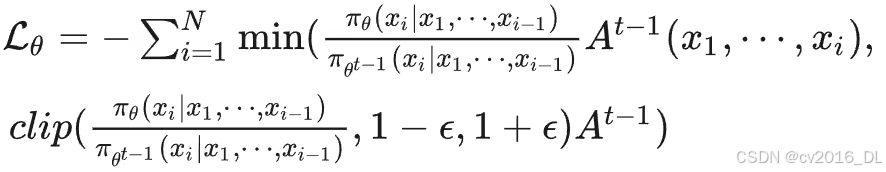
其中训练数据是由:
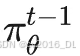
采样得到的,A 称做“优势函数”,直观而言是对当前序列好坏的判断。数学而言是:当采用策略
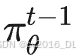
时,当前序列继续生成所能产生的奖励的数学期望(减均值 —— 基线函数)。
优势函数需要用到神经网络 critic + GAE(广义优势估计算法) 进行计算。
(6)VAPO
基于 PPO 的框架提出了一系列 tricks:
-
Clip higher:在训练时,clip 的上界可以更高一些 —— 鼓励前期探索
-
Positive Example LM Loss:如果一个样本的 reward 较高,就对他进行 SFT —— 加大对好样本的学习力度
-
Token-Level Policy Gradient Loss:对于每个 token(而非每个回答),提供相同的损失权重 —— 提高在长序列样本上的表现
-
Decoupled-GAE:对于 actor 和 critic 模型使用不同的 GAE λ 参数。对于 critic 模型,使用 1,用于确保对价值评价的准确性、无偏性;对于 policy 模型,使用较小的值(如 0.95),用于加速 policy 收敛 —— 平衡 GAE 的偏差和方差
-
Length-Adaptive GAE:对于较长的序列,使用更大的 GAE λ—— 防止长序列下 GAE 估计的问题
(7)GRPO
Deepseek-R1 使用的 RL 算法,核心思想:节省训练 critic 的计算开销。既然优势函数是数学期望,就自然可以用采样的方法来估计。
具体优势函数计算公式:对于同样的问题,给出 G 个不同的回复,对于每一个回复,分别给出奖励函数:

将第 i 个回复的优势函数设置为:
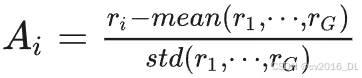
减均值、除标准差的目的在于归一化,使得优化相对稳定。但是需要注意的是,这样做会让估计变成有偏估计。
最近有工作指出,GRPO 成功的原因或许在于隐式地排除了过于困难 or 简单的样本(每个样本的奖励都等于均值)。
参考:
https://arxiv.org/abs/2504.11343
(8)DAPO
基于 GRPO 的框架提出了一系列 tricks:
-
Clip higher:GRPO 在训练时,clip 的上界可以更高一些 —— 鼓励前期探索
-
Dynamic Sampling:如果对于一个问题,答得全部正确或者全部错误,都不要在这个 batch 上训练 —— 提高训练效率
-
Rebalancing Act:对于每个 token(而非每个回答),提供相同的损失权重 —— 提高在长序列样本上的表现
-
Overlong Reward Shaping:对过长的回复,给出一个 soft 的惩罚奖励 —— 避免模型输出过长
(9)REINFORCE++
核心思想:相比于PPO,同样抛弃了 critic model 减少计算开销;逐 token 地加入了 KL 惩罚奖励;对优势函数进行了标准化。
具体优势函数计算公式,将第 i 个回复、第 t 个 token 的优势函数设置为:
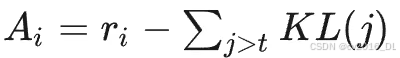
即:最终奖励函数 - 未来生成 tokens 的所有 KL 散度之和。
将优势函数进行归一化:
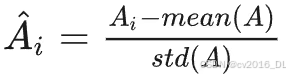
用 batch 中的所有优势函数计算均值标准差,进行归一化。
(10)SRPO
核心观察:数学题数据对训练会导致模型思考时间变长;代码题数据,不会导致模型思考时间变长。这意味着二者的优化目标之间存在差异。
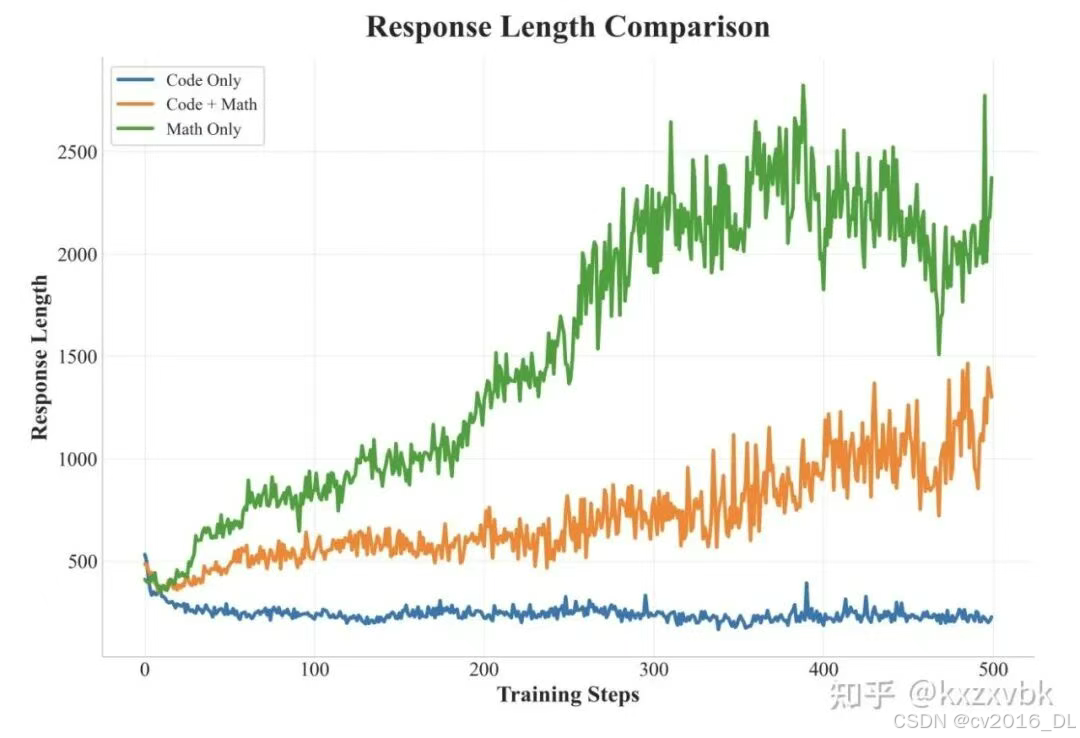
核心思路:使用课程学习的方法,逐个领域进行学习
-
阶段一:只在数学数据上训练,建立起模型基础的逻辑推理能力
-
阶段二:加入代码数据,提升模型的其他能力
同时引入了 History Sampling 方案,具体实现如下:
-
如果模型遇到了过于简单的样本(每次采样都正确),直接彻底丢弃该样本
-
如果模型遇到了过于困难的样本(每次采样都错误),不训练该样本,但是放回数据集(留待后续模型能力提升后再尝试训练)
-
如果模型遇到了难度合适的样本(采样有对有错),训练该样本
(11)GSPO
核心思想:把之前逐 token 的重要性采样权重,变成了每一个 sequence 共用一个权重。这样保证了训练的稳定性。
具体实现也非常简单,优化目标:
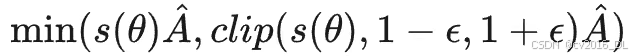
其中,A 是类似 GRPO 归一化后的 reward 函数,s(θ)是整个序列重要性采样的权重。定义为:
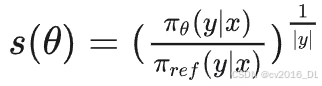
4.RL + LLM 的工程实现(Infra)
在大语言模型的训练中,基础设施(Infra)的构建是当前一个重要的问题。
Infra 的好坏,非常大程度上关系到训练代码的执行效率。 而在 RL 中(尤其是 RLHF),Infra 的问题更加复杂。
这相当程度上是由于 RL 的执行逻辑导致的,其中的优化方案也相对应地非常复杂,尤其是涉及到多机通信时。
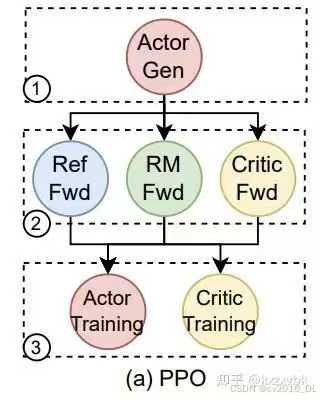
简单起见,本文将围绕 veRL 工作,主要分析和介绍一下 RL Infra 中的一些核心问题,以及一些基础的解决方案。
veRL
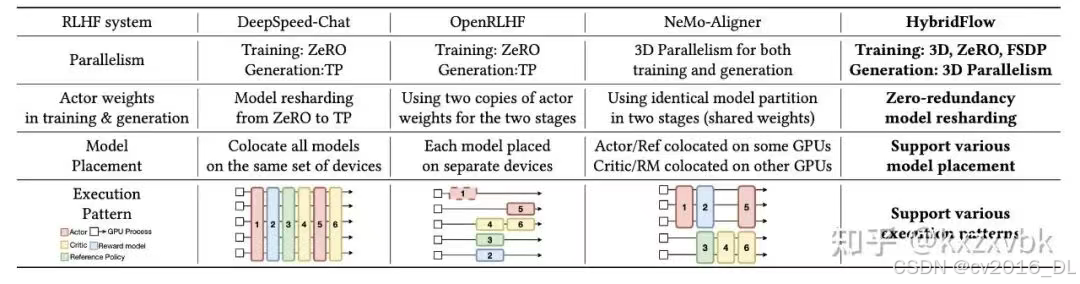
不同的 RL 框架对 PPO 的执行顺序。序号从 1-6 分别对应的流程是:
-
actor 生成;
-
RM 打分;
-
Ref policy 前向计算;
-
Critic 计算 value 值和优势函数;
-
Actor 模型更新训练;
-
Critic 模型更新训练
DeepSpeed-Chat:最简单的并行化策略。在每一个时刻,在所有的机器、卡上都执行同一个操作(生成、打分、训练 …)。这样来的好处是,可以直接使用标准 LLM 领域的 Infra 技术。
缺点在于:
-
非模块化设计,代码非常难维护、迁移到其他算法;
-
内存、通信消耗大。把所有的模型分片到所有的机器上,这样的内存和通信开销其实不小;
-
资源使用不均匀。不同模型对资源的需求程度是不同的。例如在跑 actor 的时候,GPU 资源可能占用很满,但是跑 critic 的时候可能占不满。
OpenRLHF:将不同作用的模型/流程,分散到不同的机器上,每个机器只做一个事情。
优点:
-
模块化设计,容易扩展和迁移;
-
可以根据自己的场景需求,调节给不同模块分配的计算资源。
缺点:内存和通信开销仍然有冗余:actor 训练和生成在不同的机器上。这样一来,就要存两个完整的 actor 模型;同时,这两个模型之间要经常同步,通信开销也比较显著。
NeMo-Aligner:把 Actor 单独作为一块,公用机器;把 Critic + RM 单独作为一块,公用机器。
优点:模块化的设计得到保留,同时每个模型在内存里都只有一个完整的副本。缺点:生成阶段的吞吐量比较低。
veRL:主打能够混合多种方案,找到更优解。
5.一点个人思考
现在各种强化学习算法百花齐放,该如何在自己的场景选用(或改进)适合的算法是一个困难的问题。
笔者经过了阅读和实践,大致有这么几条思考。可能有闭门造车的嫌疑,供大家参考和讨论。
看看自己的场景适合怎样的方法:
-
对于 RLVR(verifiable reward) 任务,reward hacking 的概率较小,因此更重要的是让模型在训练的时候加大探索粒度,减少约束。因此正则化问题可以少考虑,甚至不考虑。
-
对于存在 reward hacking 可能的任务(例如经典的 RLHF),正则化要求就是一个重要的限制,不然可能模型会输出奇奇怪怪的东西。当然,另一个解决问题的思路是,训练更 robust 的 reward model。
到底要不要 critic ?
-
如果目标是先能跑起来,那么无 critic 的方法(如 GRPO)明显对机器的需求量更少,infra 的难度也更低
-
但如果要追求极致的性能,目前看起来带 critic 的方法(PPO 及其变体)具有更高的上限
几条大家普遍公认有效的 trick:
-
Filter 样本是很重要的。不要选择对模型过于简单 or 困难的样本,适中难度是最好的
-
Clip higher 对前期探索很有帮助
-
GSPO sequence 粒度的重要性采样具有相当效果

















 3250
3250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









