







目录
拆包粘包
粘包产生的原因:两个包小于缓存区的大小,传送数据会将两个包都放在缓冲区中一起发送,就会产生粘包的问题。 半包产生的原因:当某一个包的大于缓冲区的大小,会被发送多次,每次就收到的就是一个不完整的数据包。
处理的方式
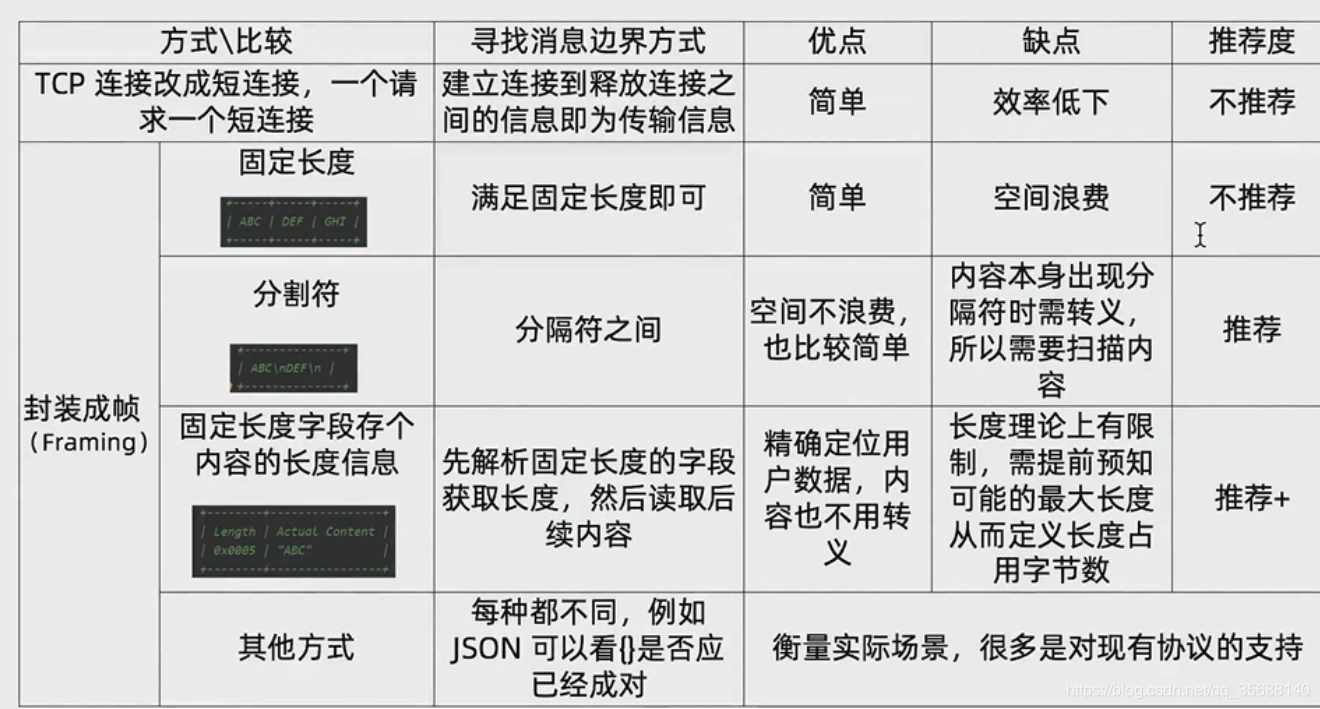
netty的处理方式

netty实现编码解码
查看ByteToMessageDecoder,该类是解码器的实现类,查看其中的channelRead方法 1.调用了cumulator.cumulate()方法来实现数据包的拼接的操作 2.callDecode()方法解析数据包
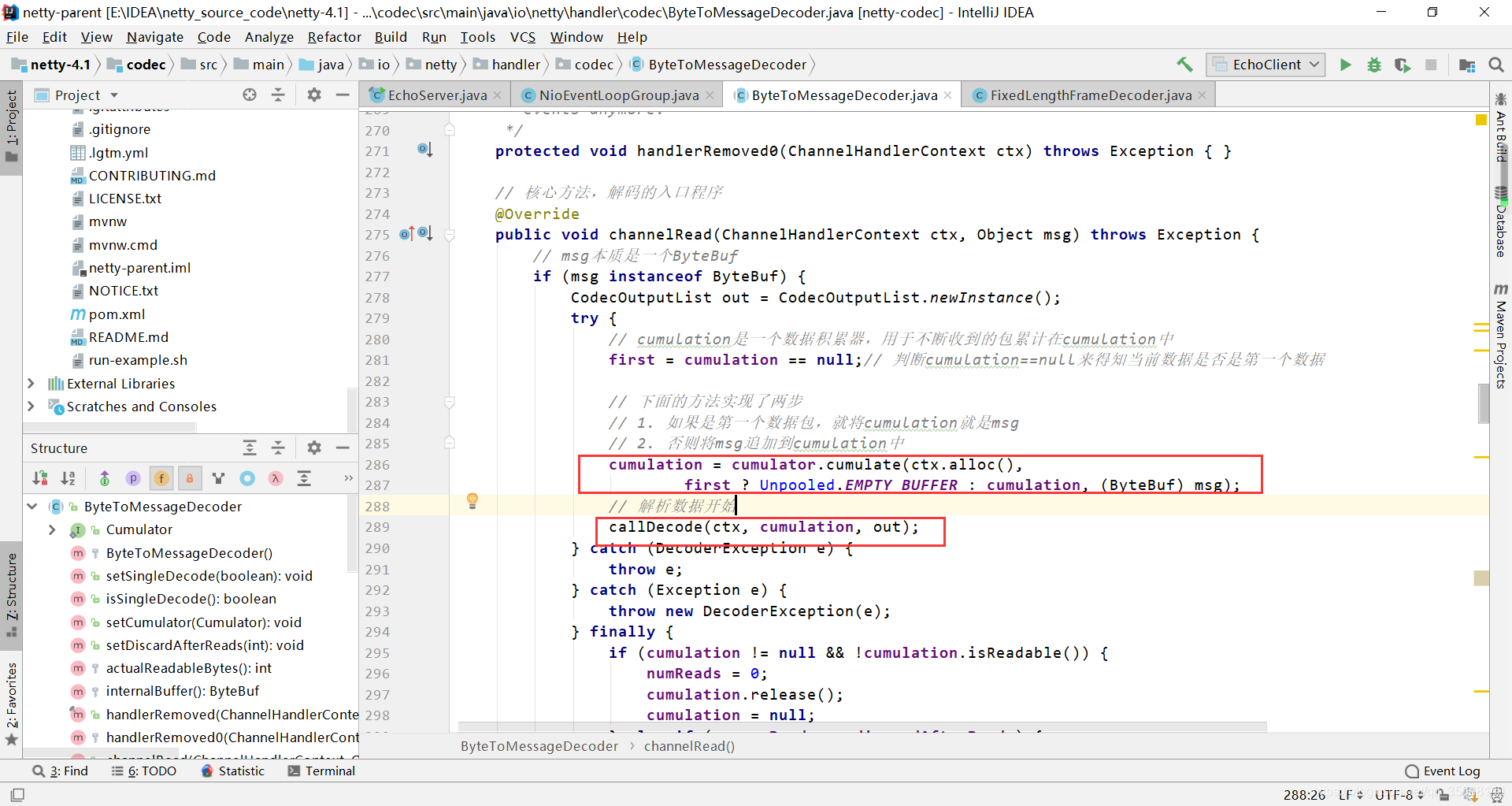
1、cumulator.cumulate() 拼接数据包
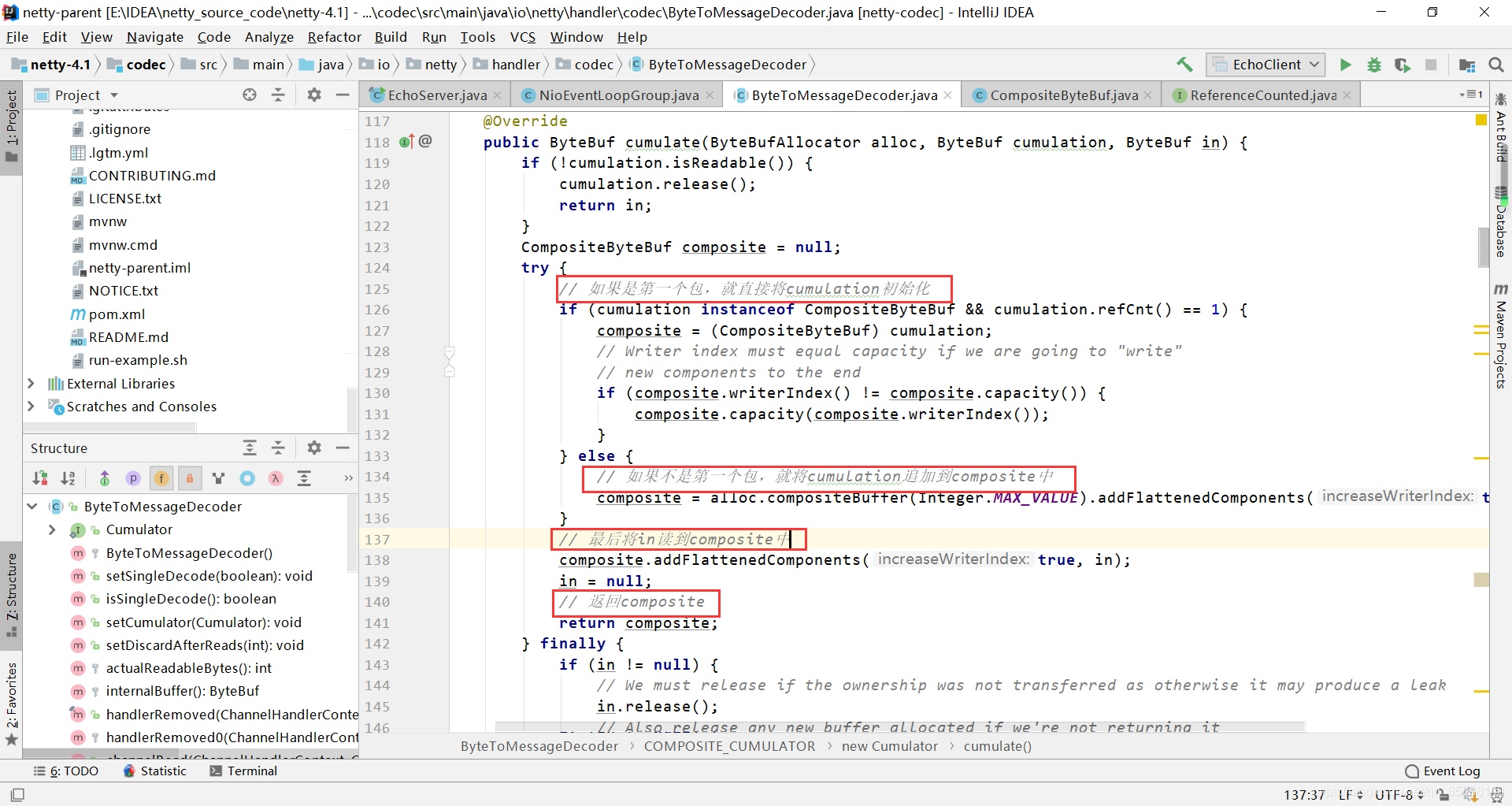
跟进源码,发现他分为两步: 1.如果是第一个数据包,就直接返回该数据包 2.如果不是第一个数据包,就将最新的数据追加导员来已经接收的数据包内
2、callDecode() 解析数据包
核心实现方法,decodeRemovalReentryProtection就是callDecode中的核心步骤
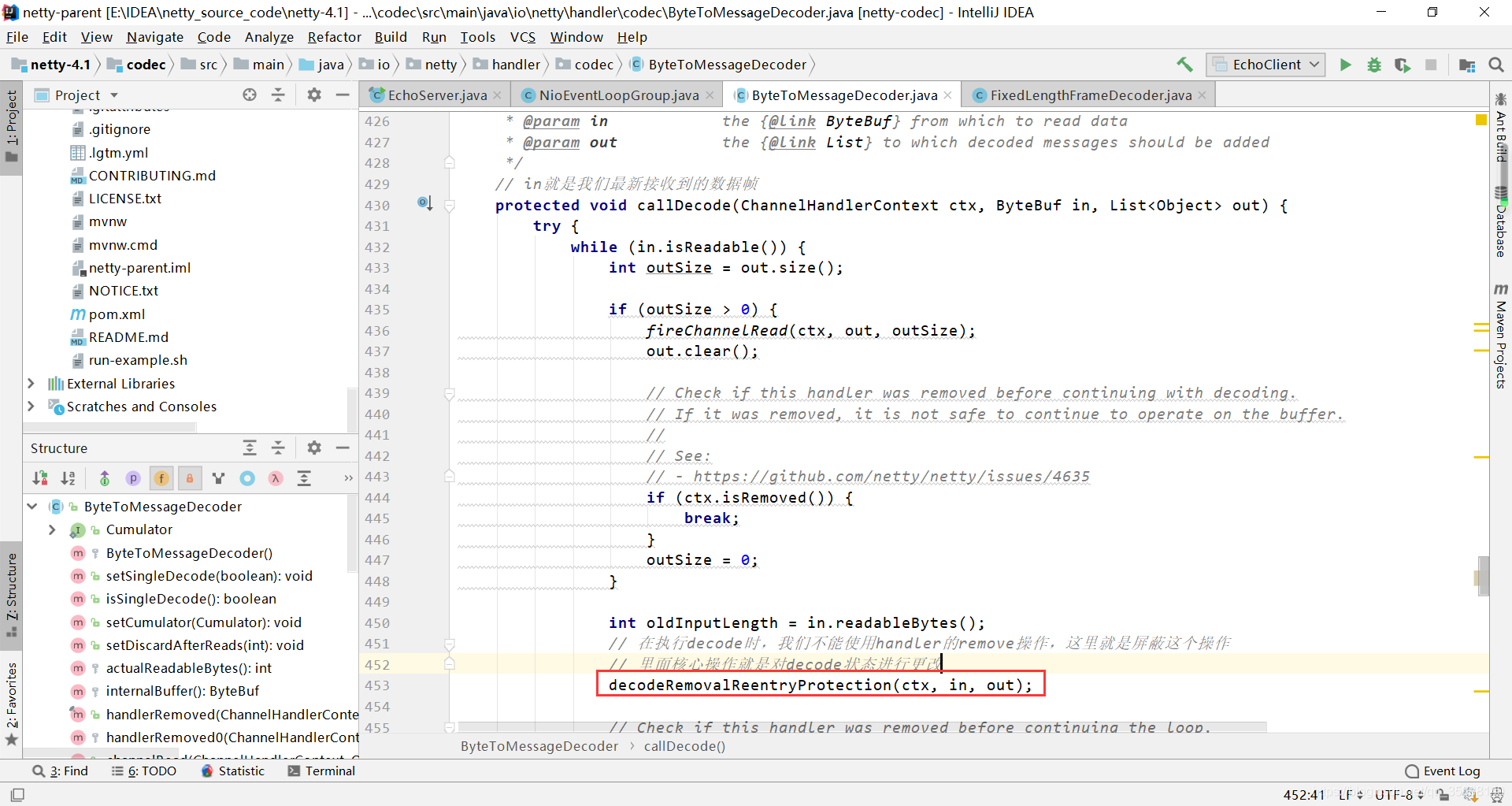
跟进源码decodeRemovalReentryProtection的源码,其中核心方法是514行的decode方法,但是此方法是一个抽象方法,也就是说ByteToMessageDecoder只是一个模板类,具体的decode方法实现在子类中
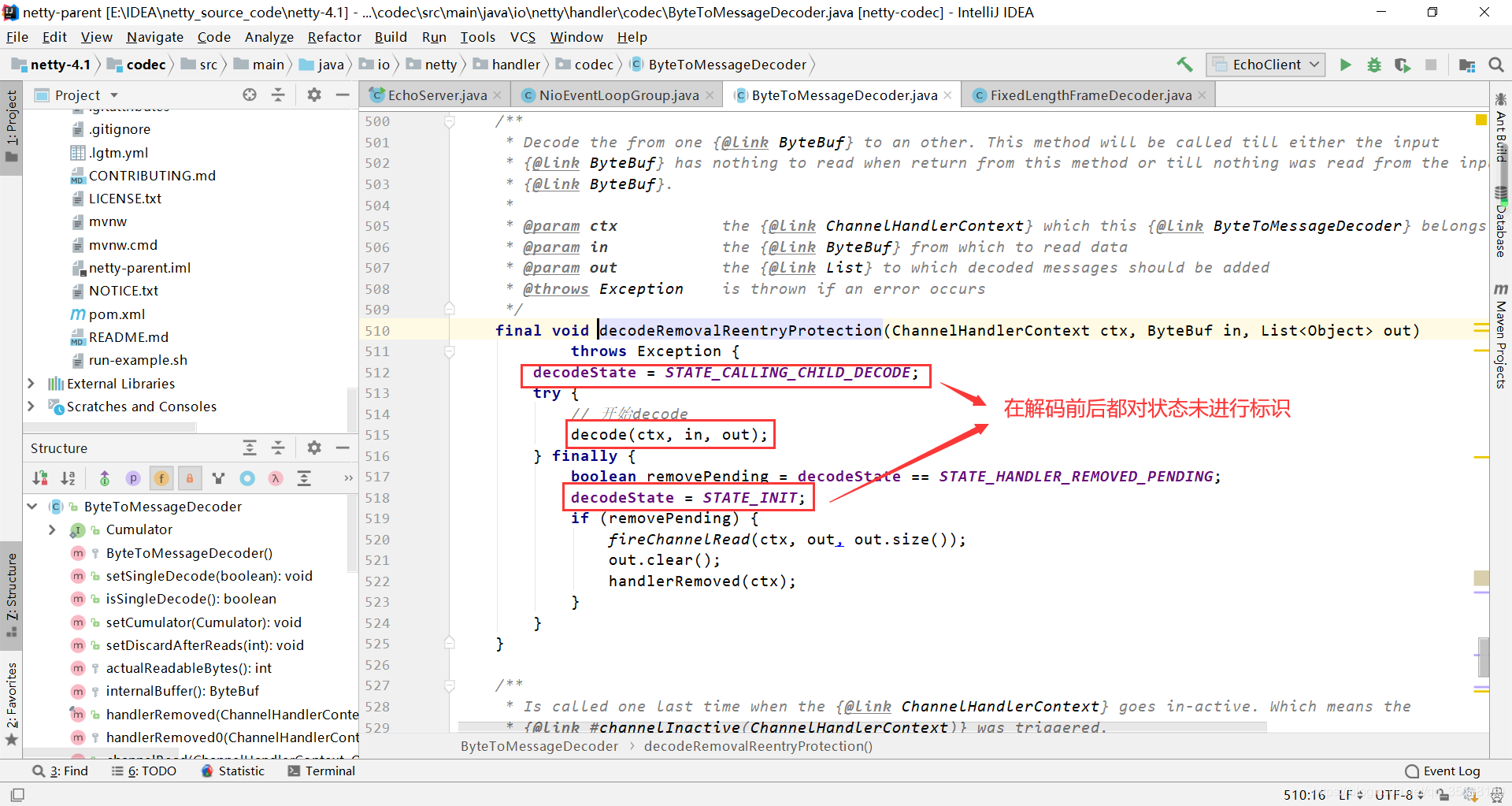
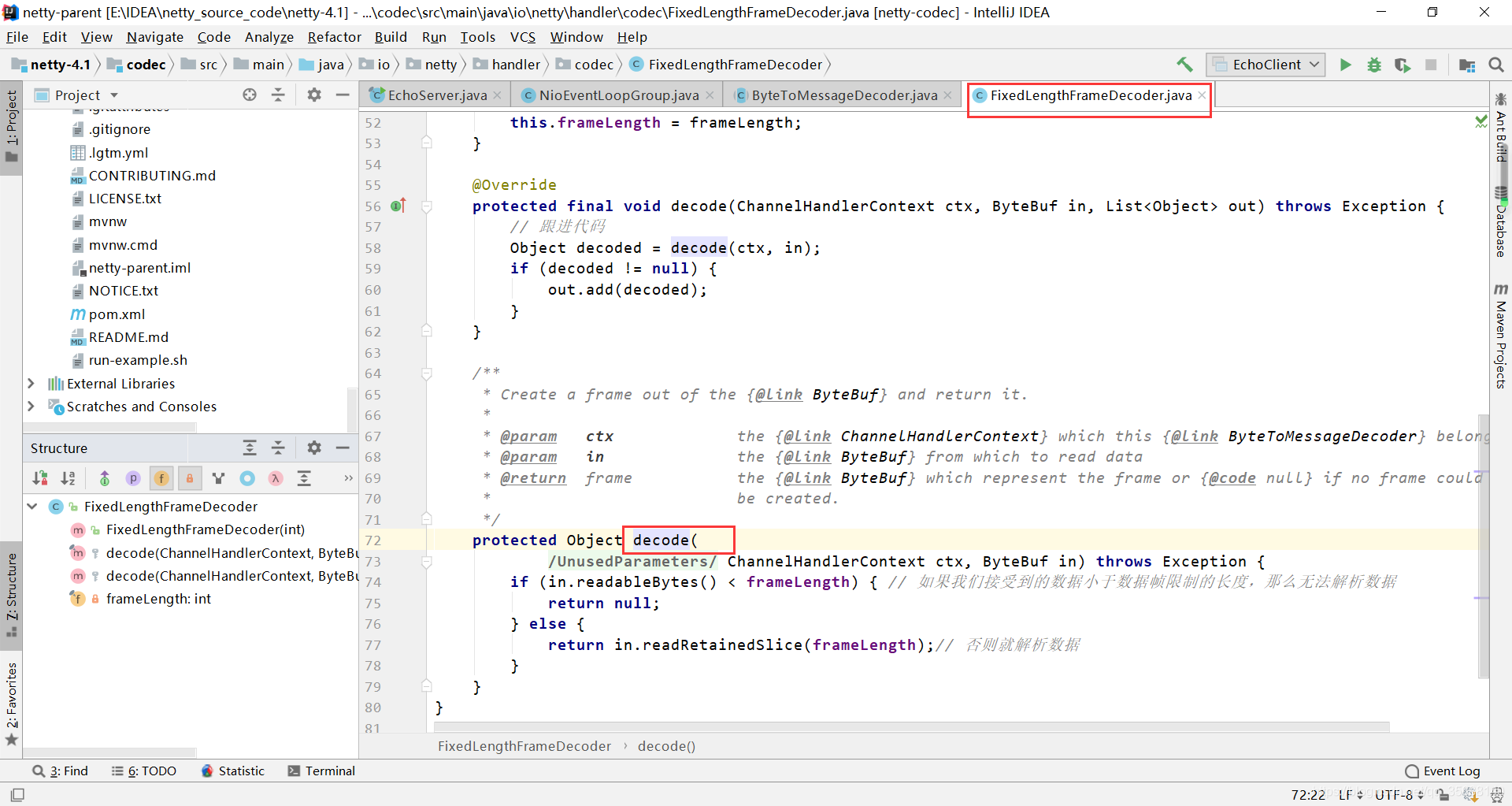
于是我们查看ByteToMessageDecoder的一个子类FixedLengthFrameDecoder,FixedLengthFrameDecoder是固定长度的编码解码方式,如果数据不足会补充空格等数据,它的decode方法如下: 1.如果我们接受到的数据小于数据帧限制的长度,那么无法解析数据,直接返回null 2.否则调用readRetainedSlice方法进行解析,readRetainedSlice就是将ByteBuf切出frameLength长度的数据出来
总结
Netty提供了一个ByteToMessageDecoder模板类,数据包的拼接交给该类完成,但是数据包的解析decode是一个抽象方法,具体实现交给子类完成
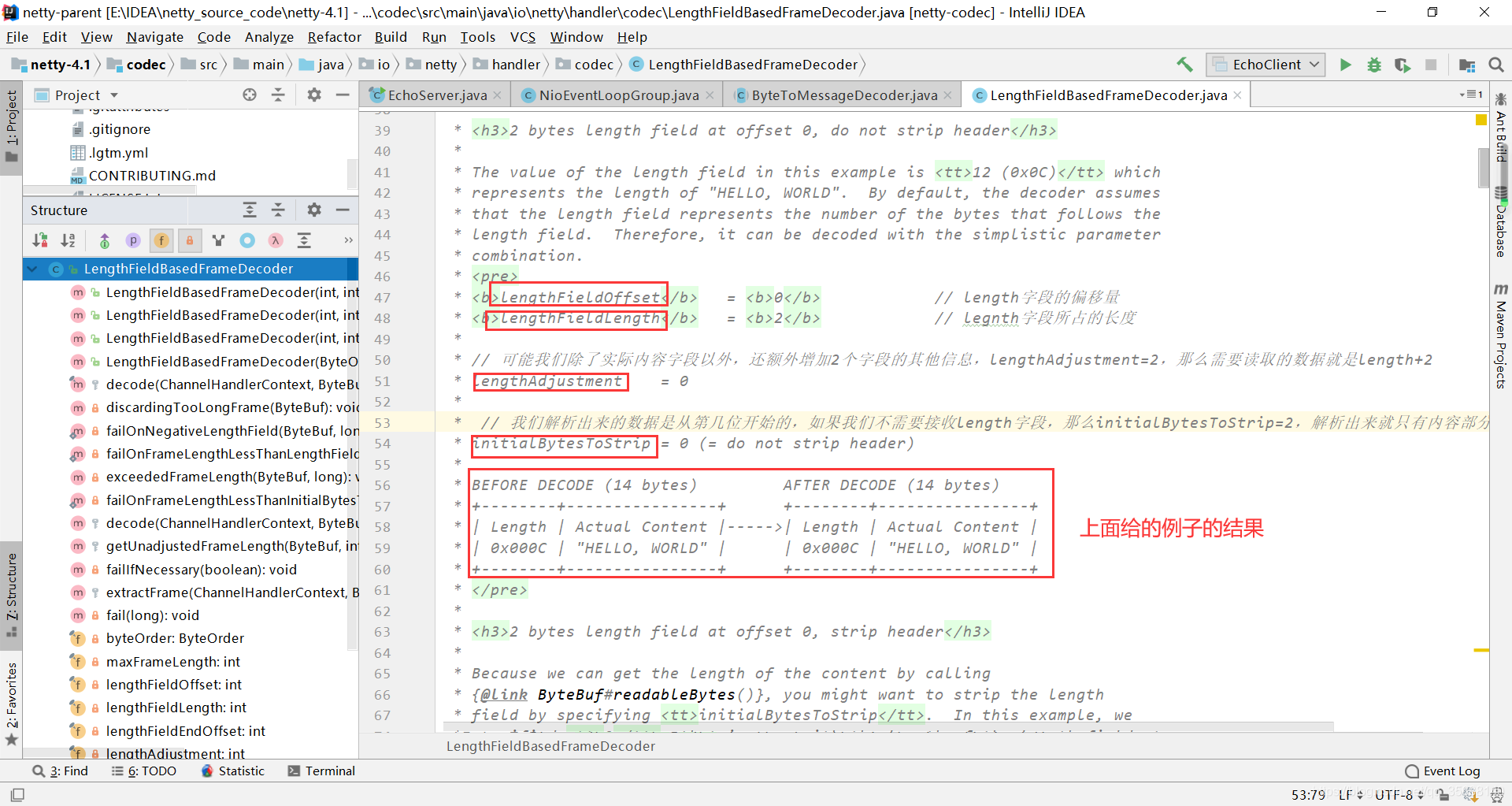
LengthFieldBasedFrameDecoder
核心就是其中的四个参数: 1.lengthFieldOffset // length字段的偏移量 2.lengthFieldLength // legnth字段所占的长度 3.lengthAdjustment // 可能我们除了实际内容字段以外,还额外增加2个字段的其他信息,lengthAdjustment=2,那么需要读取的数据就是length+2 4.initialBytesToStrip // 我们解析出来的数据是从第几位开始的,如果我们不需要接收length字段,那么initialBytesToStrip=2,解析出来就只有内容部分















 811
811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









