










我们开始来讲一些Sulley里面的整体介绍,方便我们能系统地了解Sulley的架构,了解Fuzzing的思路,最后能生成py文件来具体运行fuzzing。这章主要是整体印象,下一章开始会讲具体的模块以及如何写代码。
1.Sulley现在的情况
先说说现在的开发者情况,在github上目前的watch数量为118,star数量为894,fork数量为270,看来用的人还挺多的,不过一看它更新频率还是挺慢的,之前读了它的官方文档,作者说还有很多东西将来会引入,不过这几年缺没怎么管,哈哈,不过这也不能改变它好用的事实。
同时值得注意的一个事项是,Sulley上面有一个分支boofuzz,它的热度也很高,它的目标是可拓展性和fuzzing everything,还有很多特性,有机会的话,我们也会介绍一下它。
2.一些名词
一些常见的术语如下:
| 名词 | 含义 |
|---|---|
| host主机 | 主动发起fuzzing请求的主机 |
| target主机 | 被测试的主机,fuzzing的目标 |
| Agents代理 | 主要作用是监控,监控target,获取流量什么的 |
| request请求 | 也就是发送的数据包,一个数据报文一个request |
| session会话 | 几个数据包组成的图,相当于有状态的协议的状态图 |
3.整体框架图和4大组件
整体框架图如下图1:
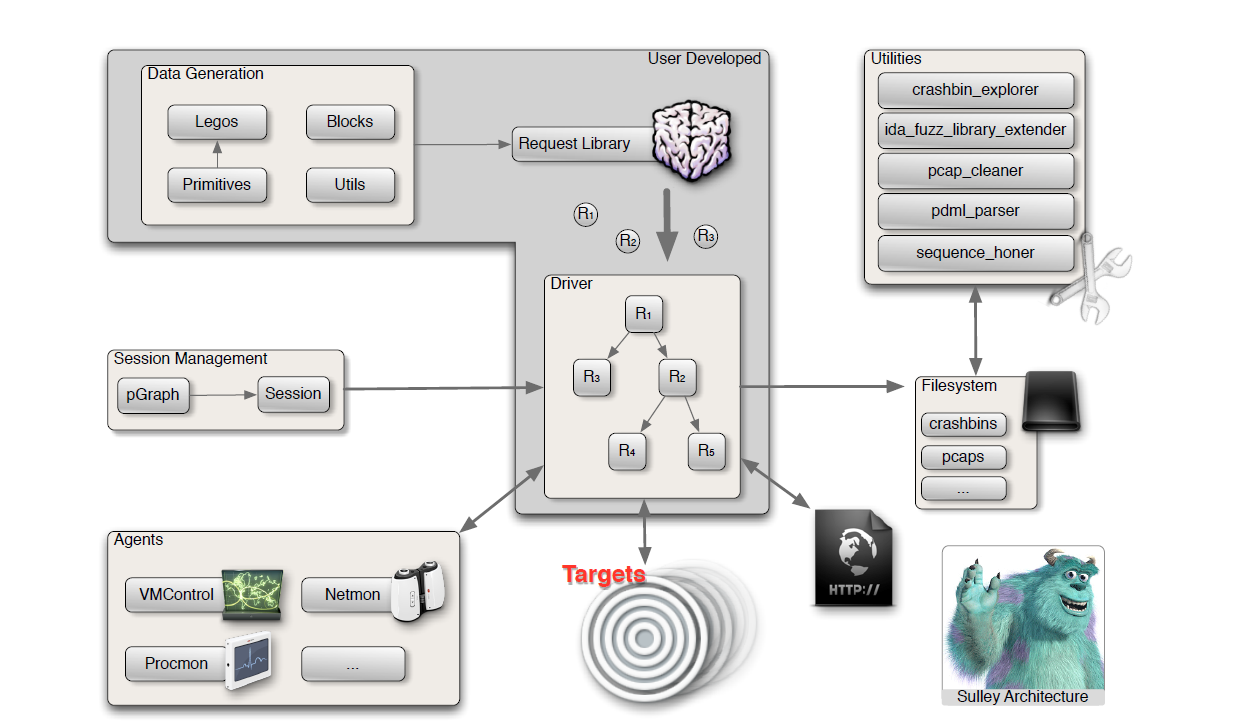
是不是被这图迷晕了头脑,没关系,我们一个一个模块来解读这个图
3.1 数据生成模块
数据生成模块的结构如下图2:

值得注意的是,sulley的数据生成方式是基于生成(generation-based)的方式,我们需要对协议或者文件进行建模
- 一个数据报文由基元(Primitives)、块(Blocks组成)
- 多个基元可以组成块,块可以相互嵌套
- 在基元的基础上我们可以创建自定义的特殊的复杂基元(Legos,数据积木,暂且这么翻译吧),例如Email的地址,IP地址等。
- 最后还有一些有用的工具,例如算length长度、校验和、加密模块等
3.2 session管理模块
session会话管理模块的结构下图3:
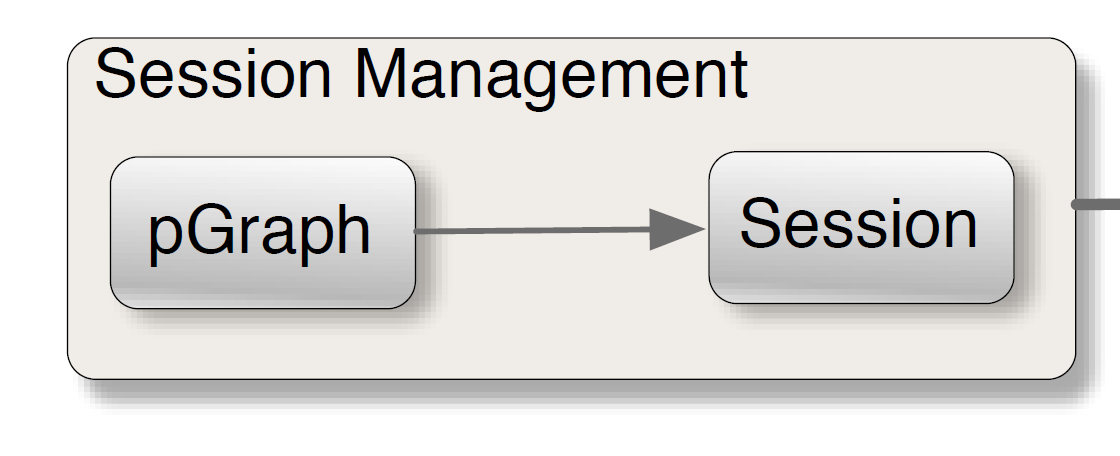
当我们构建好一个一个Resquest以后,怎么把这些Request组成在一起构成状态机呢?这就需要我们应用Pgraph这个Python graph构建库来绘制了,Pgraph可以可以创建、修改和渲染graph。让我们简单地来看一个的例子,如图4:
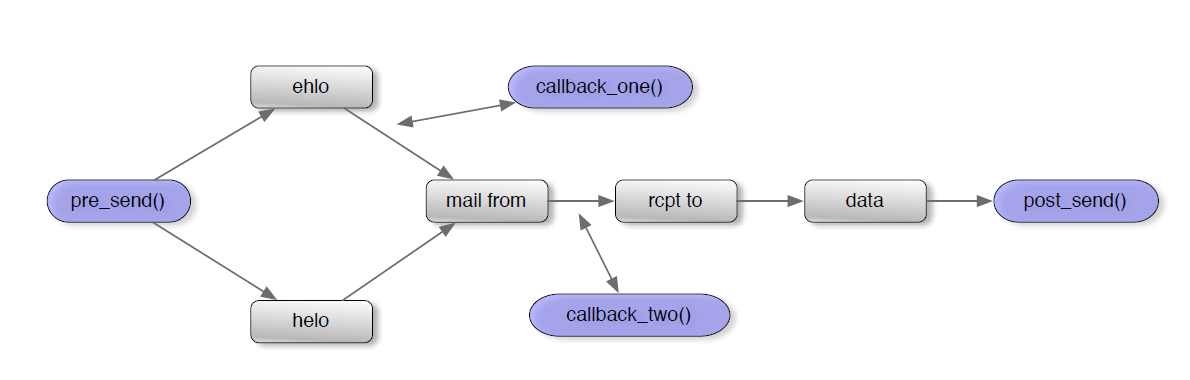
可以看出,每个节点都连接起来,组成一幅有状态的图,我们可以在图里的每个节点进行操作,同时也可以定义一些callback回调函数,是不是很像协议里面的状态机(如果协议是有状态的话),在下一章我们会再次回顾这个例子,先在此打住。
3.3 Agents代理模块
Agents代理模块的结构如下图5:

Agents代理模块主要是用来监测的,常见有三个字模块:VMControl、Netmon和Procmon。
- VMControl子模块:用来控制虚拟机,一种常见的用法是把Target目标放在虚拟机中,使用这个子模块来控制虚拟机的启动、关闭、创建快照等,最重要的功能是能在目标出现崩溃的时候恢复主机的状态。
- Netmon子模块:监视网络流量,并把PCAP文件保存到磁盘中,捕捉的双向流量
- Procmon子模块:使用Sulley的团队的另一个项目,windows下调试器PyDbg来记录程序崩溃错误和监控程序状态,同时会把错误编录到一个"crash_bin“文件中。
3.4 Utilities一些工具
这些独立的工具主要是处理各种各样任务,结构如下图6:
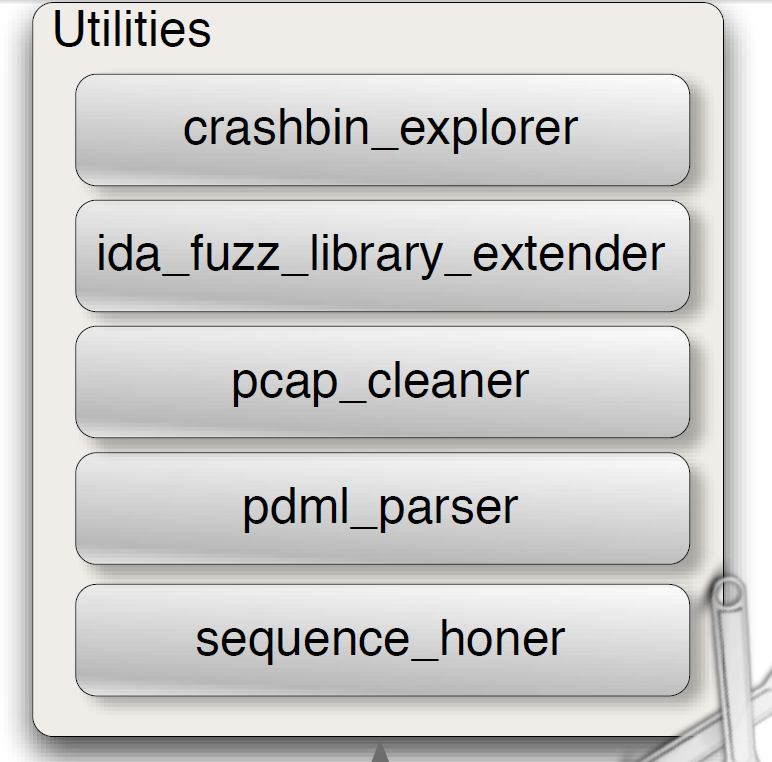
- crashbin_explorer:查看引起错误的每一个测试用例,展示每个错误发生的地址,错误的堆栈追踪并把它画在一个图上
- 其余的模块暂时不会讲,等用到的时候再讲吧
4.本章总结
Sulley最主要的就是4大模块,协议构建的过程是先进行数据报文建模,然后再连接每一个数据报文组成状态机,至于其他的模块是辅助fuzzing,来让用户更好地了解fuzzing的状态。
本章的内容有点难懂,最好的方式是通过编码的形式来了解Sulley,没关系,大家可以在之后的章节中回顾这些内容。
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











