






hive安装手册&hive词频统计
版本信息: hive-2.3.9 hadoop3.1.4
〇、一些参考网址综合
https://blog.csdn.net/tyh1579152915/article/details/109405407
https://dlcdn.apache.org/ (apache的下载官网)
https://blog.csdn.net/weixin_52851967/article/details/127280009
https://www.cnblogs.com/wang–/p/16760098.html
一、安装MySQL 5.7版本
宝塔安装(放开端口0-65535)
在宝塔上安装mysql5.7版本,去修改root密码为mysql
# 1. 登录
mysql -uroot -pmysql
# 2. 授权root用户对所有数据库在任何ip都可以进行操作
grant all on *.* to root@"%" identified by "mysql" with grant option;
# 3. 刷新数据库
flush privileges;
用户: root mysql
使用Navicat,使用192.168.247.142 root mysql就可以连上了
二、安装Hive
上传hive的安装包,解压,配置/etc/profile 环境变量
source /etc/profile
修改复制出三个文件:
cp hive-env.sh.template hive-env.sh
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-default.xml.template hive-site.xml
在hive-log4j2.properties
property.hive.log.dir =/opt/module/hive-2.3.9/logs
在hive-env.sh添加(根据自身环境适当修改一些地方)
JAVA_HOME=/usr/java/default
HADOOP_HOME=/opt/module/hadoop-3.1.4
export HIVE_CONF_DIR=/opt/module/hive-2.3.9/conf
在hive-site.xml配置(根据自身环境适当修改一些地方)
<!-- hive元数据的存储位置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.247.140:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property><!-- 指定驱动程序 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 连接数据库的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>qdhive</value>
<description>username to use against metastore database</description>
</property>
<!-- 连接数据库的口令 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>MySQL.123</value>
<description>password to use against metastore database</description>
</property>
<!--显示查询出的数据的字段名称-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<!--在hive中显示当前所在数据库名称-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<!--使得查询单列数据不会执行mapreduce-->
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns)
</description>
</property>
<property>
<name>hive.server2.long.polling.timeout</name>
<value>5000</value>
<description>Time in milliseconds that HiveServer2 will wait, before responding to asynchronous calls that use long polling</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.247.140</value>
<description>Bind host on which to run the HiveServer2 Thrift interface.
Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>
Setting this property to true will have HiveServer2 execute
Hive operations as the user making the calls to it.
</description>
</property>
将hive中lib下的guava-14.0.1.jar删除换上hadoop里面的/opt/module/hadoop-3.1.4/share/hadoop/common/lib下的guava-27.0-jre.jar
将 mysql-connector-java-5.1.47.jar 拷贝到 $HIVE_HOME/lib
schematool -initSchema -dbType mysql
start-all.sh 开启hadoop集群
关闭安全模式
hadoop dfsadmin -safemode leave
hive 常用命令练习
https://dblab.xmu.edu.cn/blog/2440/
三、使用hive完成词频统计(WordCount)
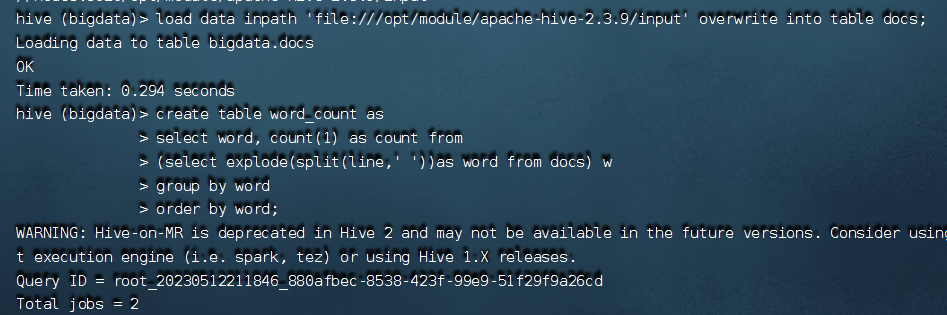
create table docs(line string);
load data inpath 'file:opt/module/hive-2.3.9/input' overwrite into table docs;
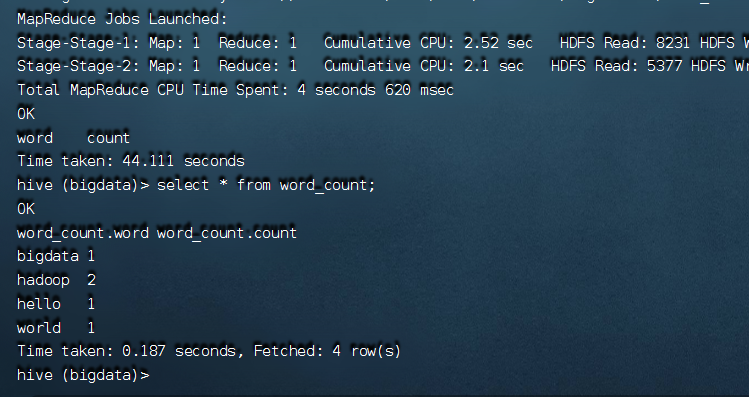
create table word_count as
select word, count(1) as count from
(select explode(split(line,' '))as word from docs) w
group by word
order by word;















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









