







问题1: Operation category READ is not supported in state standby

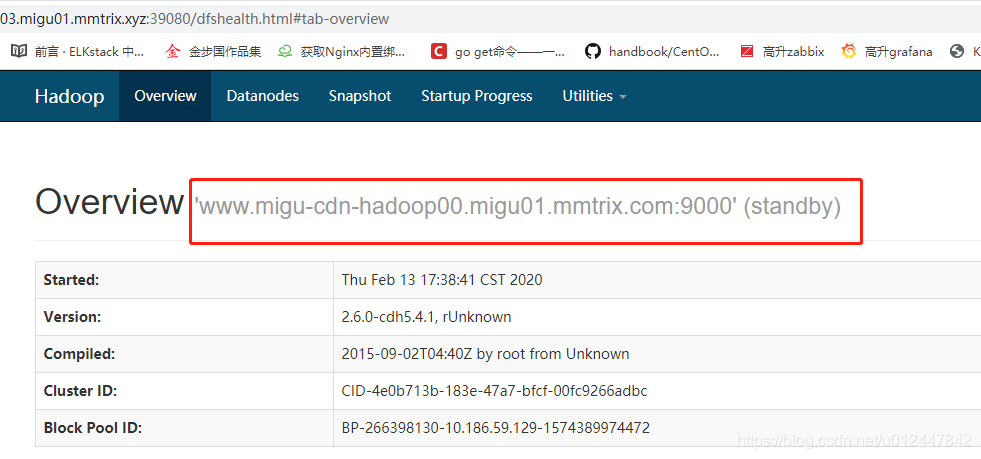
初步判断是由于HA节点中处于standby状态造成的异常,困扰:项目开放的hdfs端口只有一台服务器
原因: 原来nn1机器是active,nn2是standby, 现在nn1变成了standby。
(1)在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
(2)hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode,这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
(3)hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.4.1解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
bin/hdfs dfsadmin -report 查看hdfs的各节点状态信息
bin/hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
sbin/hadoop-daemon.sh start namenode 单独启动一个namenode进程
sbin/hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
解决方案:
查看nn1的状态
[mmtrix@mg002 hadoop]$ bin/hdfs haadmin -getServiceState nn1
standby
[mmtrix@mg002 hadoop]$ bin/hdfs haadmin -getServiceState nn2
active
修改nn2为standby状态
[mmtrix@mg002 hadoop]$ bin/hdfs haadmin -transitionToStandby --forcemanual nn2
修改nn1为active状态
[mmtrix@mg002 hadoop]$ bin//hdfs haadmin -transitionToActive --forcemanual nn1
最后结果:
[mmtrix@mg002 hadoop]$ bin/hdfs haadmin -getServiceState nn1
active
[mmtrix@mg002 hadoop]$ bin/hdfs haadmin -getServiceState nn2
standby
问题2: This is standby RM. Redirecting to the current active RM: http://www.migu-cdn-hadoop01.migu01.mmtrix.com:8088/cluster/apps/RUNNING
将active的机器的resourcemanager的进程kill掉。
standby的备用的机器变为active。
yarn-daemon.sh start resourcemanager
参考: https://www.cnblogs.com/biehongli/p/7660310.html


















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











