







本博客文章涵盖了有关YARN资源管理的以下主题,并为每个主题提供了最佳实践:
1:Warden如何计算和分配资源给YARN?
2:YARN中的最小和最大分配单位
3:虚拟/物理内存检查器
4:Mapper,Reducer和AM的资源请求
5:瓶颈资源
1.1:Warden如何计算和分配资源给YARN?
在一个MapR Hadoop集群,Warden设置操作系统,MapR-FS,MapR Hadoop服务和MapReduce v1和YARN应用程序的默认资源分配。详细信息在MapR文档中描述:Resource Allocation for Jobs and Applications
YARN可以管理3个系统资源 - 内存,CPU和磁盘。监视器完成计算后,将设置环境变量YARN_NODEMANAGER_OPTS以启动NM。
例如,如果你执行" vi /proc//environ",能够发现:
YARN_NODEMANAGER_OPTS= -Dnodemanager.resource.memory-mb=10817 -Dnodemanager.resource.cpu-vcores=4 -Dnodemanager.resource.io-spindles=2.0 |
可以通过在NM节点上的yarn-site.xml中设置以下三个配置并重新启动NM来覆盖它们。
-
yarn.nodemanager.resource.memory-mb
-
yarn.nodemanager.resource.cpu-vcores
-
yarn.nodemanager.resource.io-spindles
要查看每个节点的可用资源,你可以访问RM UI(http://:8088 / cluster / nodes),并从每个节点中找出"Mem Avail","Vcores Avail"和"Disk Avail"。
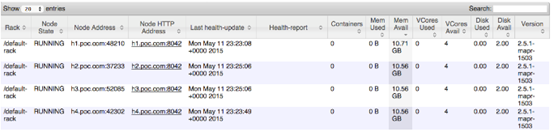
如果内存过量分配给YARN,可能发生swap,并且 kernel OOM killer有可能会触发kill container进程. 以下错误是OS OOM的标志,可能内存已超量分配给YARN。
os::commit_memory(0x0000000000000000, xxxxxxxxx, 0) failed; error='Cannot allocate memory' (errno=12) |
如果我们看到,只需要仔细检查一下,warden是否考虑到该节点上的所有内存消耗服务,并且如果需要,减少由warden分配的内存。
1.2. YARN中的最小和最大分配单位
两个资源 - 内存和CPU,如Hadoop 2.5.1,在YARN中具有最小和最大的分配单位,由以下配置在yarn-site.xml中设置:
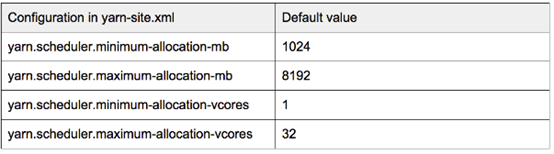
基本上,这意味着RM只能以"yarn.scheduler.minimum-allocation-mb"为增量分配容器,而不能超过"yarn.scheduler.maximum-allocation-mb";
并且它只能以"yarn.scheduler.minimum-allocation-vcores"为增量分配CPU容量,而不能超过"yarn.scheduler.maximum-allocation-vcores"。
如果需要更改,请在RM节点上的yarn-site.xml中设置上述配置,然后重新启动RM。
例如,如果一个作业要求每个map container 1025 MB的内存(set mapreduce.map.memory.mb = 1025),则RM将给它一个2048 MB(2 * yarn.scheduler.minimum-allocation-mb)container。
如果你有一个巨大的MR作业要求一个9999 MB的map container,则该作业将在AM日志中的以下错误消息中被杀死:
|
如果一个Spark on YARN工作要求一个巨大的Container,大小大于"yarn.scheduler.maximum-allocation-mb",下面的错误会显示出来:
|
在上述两种情况下,你可以在yarn-site.xml中增加"yarn.scheduler.maximum-allocation-mb"并重新启动RM。
所以在这一步中,你需要熟悉每个mapper和作业的reducer的资源需求的下限和上限,并根据此设置最小和最大分配单元。
1.3:虚拟/物理内存检查器
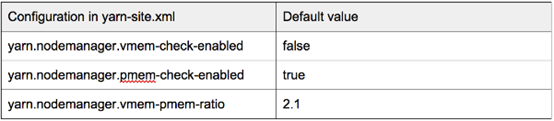
NodeManager可以监视容器的内存使用情况(虚拟和物理)。如果虚拟内存超过"yarn.nodemanager.vmem-pmem-ratio"乘以"mapreduce.reduce.memory.mb"或"mapreduce.map.memory.mb",若"yarn.nodemanager.vmem-check-enabled"设置为true,那么这个container会被kill.
如果其物理内存超过"mapreduce.reduce.memory.mb"或"mapreduce.map.memory.mb",则如果"yarn.nodemanager.pmem-check-enabled"为真,则容器将被终止。
以下参数可以在每个NM节点的yarn-site.xml中进行设置,以覆盖默认行为。
这是虚拟内存检查程序杀死的容器的示例错误:
|
这是物理内存检查器的示例错误:
|
与MapR 4.1.0的Hadoop 2.5.1一样,默认情况下启用物理内存检查,虚拟内存检查器被禁用。
由于在Centos / RHEL 6上,由于操作系统的行为,存在虚拟内存的大量分配,你应该禁用虚拟内存检查器或将yarn.nodemanager.vmem-pmem-ratio增加到一个相对较大的值。
如果发生上述错误,MapReduce作业也有可能泄漏内存,或者每个容器的内存都不够。尝试检查应用程序逻辑,并调整容器内存请求—"mapreduce.reduce.memory.mb" or "mapreduce.map.memory.mb".
1.4: Mapper,Reducer和AM的资源请求
MapReduce v2作业有3种不同的容器类型 - Mapper,Reducer和AM。 Mapper和Reducer可以要求资源 - 内存,CPU和磁盘,而AM只能要求内存和CPU。以下是三种容器类型的资源请求的配置摘要. 默认值来自MapR 4.1的Hadoop 2.5.1,它们可以在客户端节点的mapred-site.xml中被覆盖,也可以在MapReduce java代码,Pig和Hive Cli等应用程序中设置。
-
Mapper:
-
Reducer:
-
AM:

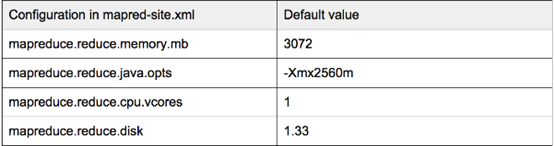
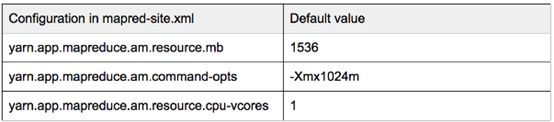
每个容器实际上都是一个JVM进程,并且java-opts的"-Xmx"上面应该适合分配的内存大小。一个最佳做法是设置为0.8 *(容器内存分配)。例如,如果请求的映射器容器具有mapreduce.map.memory.mb = 4096,我们可以设置mapreduce.map.java.opts = -Xmx3277m。
有许多因素会影响每个容器的memory需求。这些因素包括Mappers / Reducers的数量,文件类型(plain text file , parquet, ORC),数据压缩算法,操作类型(sort, group-by, aggregation, join),数据偏移等。你应该熟悉MapReduce工作的性质,并找出Mapper,Reducer和AM的最低要求。任何类型的容器都可能用完内存,并被物理/虚拟内存检查器杀死,如果它不符合最低内存要求。如果是这样,你需要检查AM日志和发生故障的容器日志以找出原因。
例如,如果MapReduce作业对parquet文件进行排序,Mapper需要将整个Parquet行组缓存在内存中。我已经做了测试 ,以证明parquet文件的行组大小越大,需要更大的Mapper内存。在这种情况下,请确保Mapper内存足够大,无需触发OOM。
另一个例子是AM内存不足。通常,AM的1G Java堆大小对于许多作业来说已经足够了。但是,如果工作要写大量的parquet文件,在作业的提交阶段,AM将调用ParquetOutputCommitter.commitJob()。它将首先读取所有输出parquet文件的页脚,并在输出目录中写入名为"_metadata"的元数据文件。
此步可能导致AM 的OOM :
|
解决方案是增加AM的内存需求,并通过"set parquet.enable.summary-metadata false"禁用该parquet功能。
除了找出每个容器的最低内存需求外,有时我们需要平衡工作性能和资源能力。例如,进行排序的作业可能需要相对较大的"mapreduce.task.io.sort.mb",以避免或减少溢出文件的数量。如果整个系统具有足够的内存容量,我们可以增加"mapreduce.task.io.sort.mb"和容器内存,以获得更好的工作性能。
在此步骤中,我们需要确保每种类型的容器满足适当的资源要求。如果OOM发生,请始终先检查AM日志,找出哪个容器以及每个stack trace的原因。
1.5 瓶颈资源
由于有三种资源类型,不同工作的不同容器可能会要求不同的资源数量。这可能导致其中一个资源成为瓶颈。假设我们有一个容量集群(1000G RAM,16个核心,16个磁盘),每个Mapper容器需要(10G RAM,1个核心,0.5个磁盘):最多可以并行运行16个Mappers,因为CPU核心成为这个瓶颈。
因此,任何人都不会使用(840G RAM,8个磁盘)资源。如果您遇到这种情况,只需检查RM UI(http://:8088 / cluster / nodes),找出哪个资源是瓶颈。您可以将剩余资源分配给可以通过此类资源提高性能的作业。例如,您可以将更多的内存分配给排序job,防止用溢出到磁盘。
1.6 总结
(1) 熟悉mapper和reducer的资源需求的下限和上限。
(2) 注意虚拟和物理内存检查器。
(3) 将每个容器的java-opts的-Xmx设置为0.8 *(容器内存分配)。
(4) 确保每种类型的容器满足适当的资源需求。
(5) 充分利用瓶颈资源。














 2289
2289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









