







I/O流
IO流(数据流):对存储设备上的数据进行操作
硬盘磁头:复制文件时这里复制一次,磁头在这边复制一次;写入的那边,写一次磁头移动到那边又写一次。硬件移动花费时间量大,所以复制时要定义足够大的缓冲区来一次性复制大量数据并写入,大大增加效率
I/O流输入输出设备区分:
源设备:内存System.in、硬盘FileStream、键盘ArrayStream
目的设备:内存System.out、硬盘File Stream、控制台ArrayStream
字符流结构图:
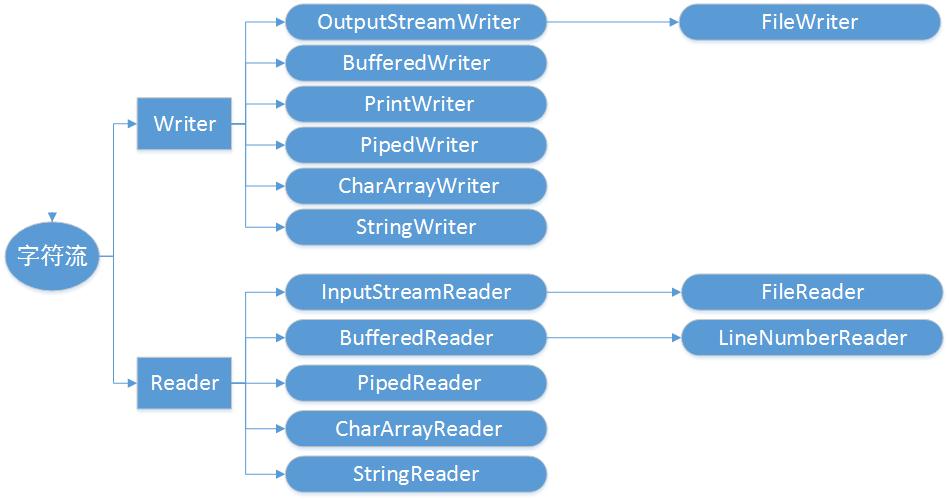
字节流结构图:
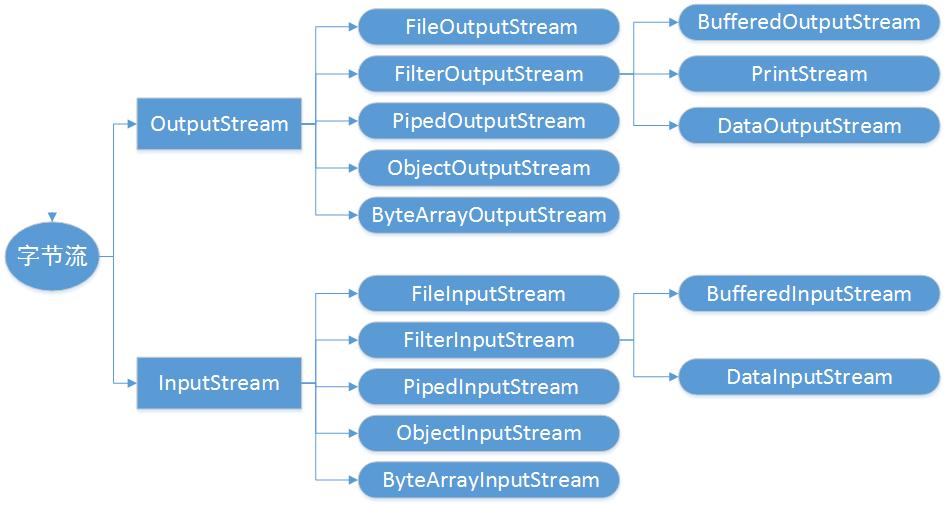
I/O流其他结构图:

1.编码表
1.码表分类
(1)ACCII码表:美国信息标准交换码,用二进制数字表示英文字符
(2)GB2312码表:中国码表,用二进制数组表示中国汉字
(3)GBK码表:前者扩容后得到的GBK码表,现在为GBK18030。GBK中每个中文用2个字节表示
(4)UNICODE码表:世界码表,国际标准化组织用二进制数字表示全世界所有文字。Java默认编码形式,char类型数据的编码
(5)UTF-8码表:前者优化得来的,主要优化了任何字符都在UNICODE码表中占用了个字节的问题。UTF-8中每个中文用3个字节表示。有自己的标识头,数据最开始有标识,读取数据方便
(6)IOS8859-1:拉丁码表,欧洲码表,服务器Tomcat用的就是该码表,当用get方法传递数据是必须手动转码,post方法可以用内置对象解决
2.知识点
2.1 编码:字符串变为字节数组。数据存储在硬盘上是进行了编码操作
byte[] | getBytes(Charset charset) 使用给定的 charset 将此 String 编码到 byte 序列,并将结果存储到新的 byte 数组。 |
byte[] | getBytes(String charsetName) 使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。 |
2.2 解码:字符数组变为字符串。用不同软件打开硬盘上的文件都是在做着解码的操作
String(byte[] bytes, Charset charset) 通过使用指定的 charset 解码指定的 byte 数组,构造一个新的 String。 |
String(byte[] bytes, String charsetName) 通过使用指定的 charset 解码指定的 byte 数组,构造一个新的 String。 |
2.3 具体例子
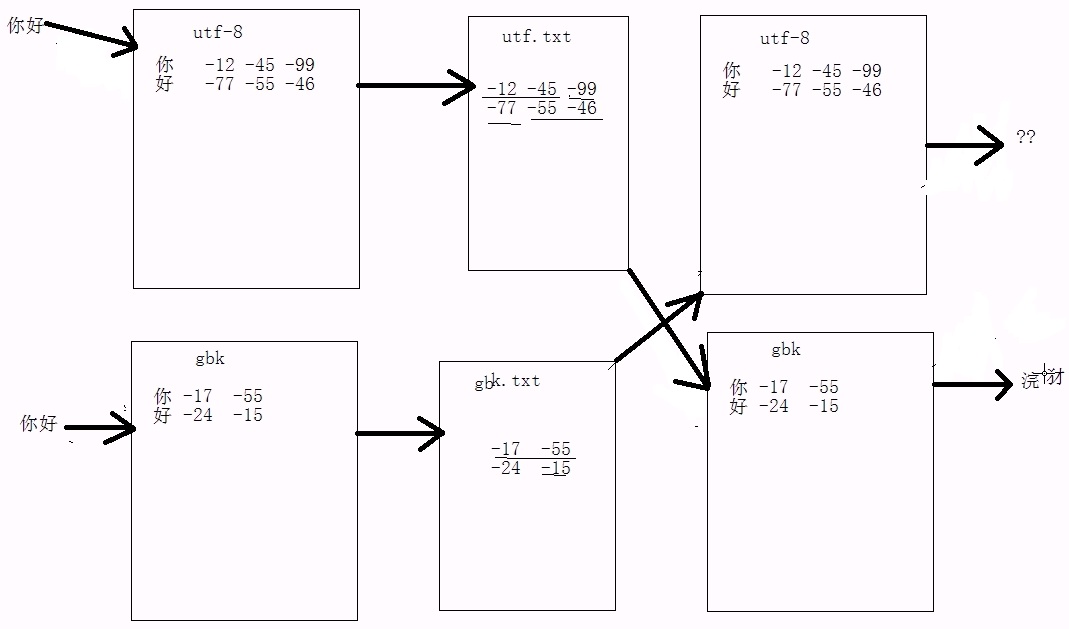
(1)字符串String str = "你好",当使用getBytes("utf-8")形式编码时,却用new String(,"gbk")形式解码,结果是:浣犲ソ。错误编码无法解决,因为底层数据错乱了
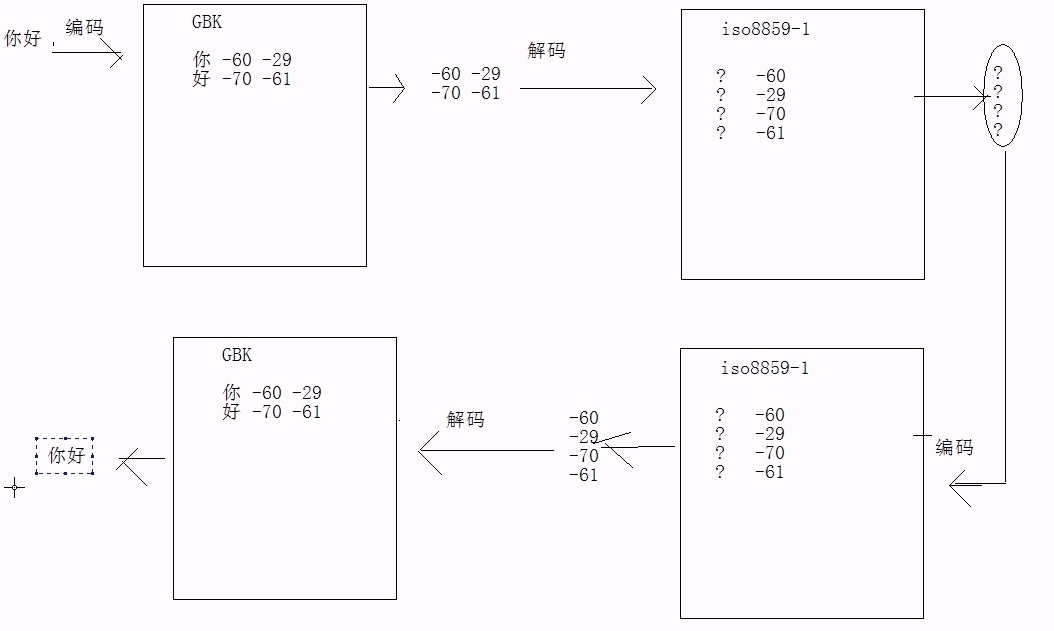
(2)字符串String str = "你好",当使用getBytes("gbk")形式编码时,却用new String(,"ISO8859-1")形式解码,结果是:???。错误解码可以解决,再次按照错误的码表编码=>getBytes("ISO8859-1"),然后按照正确的码表解码即可new String("gbk")。因为字节数组中的数据从头至尾都是正确的没有改变过。过程如下图:
注意:如果是按照“utf-8形式解码,不能用这种方法解决,因为再次编码时改变源数据。问题的产生是因为【gbk】与【utf-8】都识别中文
===================================================================================================================
(3)问题:联通(记事本txt中只存入“联通”字符,不存入任何其他字符,保存后再打开会发现解码错误,显示乱码)
阐述:自动按照utf-8码表形式解码。这里解决问题先要阐述一下utf-8码表,这个码表中有2个字节代表1字符,也有3个字节代表1字符的,这样如何判断是读取2个字节还是3个字节来查表?其实utf-8码表对每个字节都添加了一个标示头信息,通过该标示头信息就可以知道是读取1个或者2个还是字节3个字节来查表。这时我们可以获取“联通”字符串的4个字节的二进制表现形式,你会发现这2个字符正好符合utf-8定义的标识头,所以记事本没有按照gbk码表解码,而是用utf-8码表解码的。
解决:在联通前边加入任意其他中文字符即可正常解码,使用gbk解码,显示正常
特:utf-8的标示头对照表如下:
\u0001' 到 '\u007F' 范围内的所有字符都是用单个字节表示的:
位值 字节 1
0 位 6-0
null 字符 '\u0000' 以及从 '\u0080' 到 '\u07FF' 的范围内的字符用两个字节表示:
位值 字节 1
1 1 0 位 10-6 字节 2
1 0 位 5-0
'\u0800'
到
'\uFFFF'
范围内的
char
值用三个字节表示:
位值 字节 1
1 1 1 0 位 15-12 字节 2
1 0 位 11-6 字节 3
1 0 位 5-0
===================================================================================================================
2.字符流
特点:主要用于操作字符数据。基于字节流,解决了编码问题,因为内部融合了编码表,查字节对码表。可以自定义指定所需要的码表
注意:应用系统不同换行符不同,windows为 \r\n, Linux为 \n
1.Writer抽象类
注意:写入的过程都是在调用系统中的资源在写入数据,所以使用完毕后一定要释放资源
(1)异常的处理方法:
<1>.IO类中的方法都会抛出IOException(),所以要注意处理方式
<2>.处理方法如下:import java.io.*;
class java
{
public static void main(String[] args){
FileWriter fw = null;//定义引用
try{
//创建文件写入流
fw = new FileWriter("d:\\a.txt");
//写入数据
fw.write("郑天成是个SB!");
}catch(IOException e){//处理异常
e.printStackTrace();
}finally{
if(fw!=null)//判断是否为空
try{
fw.close();//关资源
}catch(IOException e){
e.printStackTrace();
}
}
}
}| 方法摘要 | |
|---|---|
abstract void | close() 关闭此流,但要先刷新它。(会刷新流一次)(因为给个子类实现方式是不一样的,所以抽象) |
abstract void | flush() 刷新该流的缓冲。(清空缓冲区,把其中的数据传送到指定文件中) |
void | write(char[] cbuf) 写入字符数组。 |
abstract void | write(char[] cbuf, int off, int len) 写入字符数组的某一部分。 |
void | write(int c) 写入单个字符。 |
void | write(String str) 写入字符串。(写的数据不是直接写入文件中,而是写入到了流的缓冲(内存)里面,需要flush刷新一下才能写入文件) |
void | write(String str, int off, int len) 写入字符串的某一部分。 |
1.1 OutputStreamWriter类
| 构造方法摘要 | |
|---|---|
OutputStreamWriter(OutputStream out) 创建使用默认字符编码的 OutputStreamWriter。 | |
OutputStreamWriter(OutputStream out, CharsetEncoder enc) 创建使用给定字符集编码器的 OutputStreamWriter。 | |
OutputStreamWriter(OutputStream out, String charsetName) 创建使用指定字符集的 OutputStreamWriter。 | |
| 方法摘要 | |
|---|---|
String | getEncoding() 返回此流使用的字符编码的名称。 |
1.2 FileWriter类
FileWriter字符集:采用平台默认字符编码
| 构造方法摘要 | |
|---|---|
FileWriter(File file) 根据给定的 File 对象构造一个 FileWriter 对象。 | |
FileWriter(File file, boolean append) 根据给定的 File 对象构造一个 FileWriter 对象。 | |
FileWriter(String fileName) 根据给定的文件名构造一个 FileWriter 对象。(该对象一初始化就必须明确要操作文件,并将该文件会在指定目录下被创建,而且会覆盖同名文件) | |
FileWriter(String fileName, boolean append) 根据给定的文件名以及指示是否附加写入数据的 boolean 值来构造 FileWriter 对象。(true代表不覆盖已有文件) | |
2.Reader抽象类
注意:windows每个文件结尾处都有一个被系统识别的结束标识
| 方法摘要 | |
|---|---|
abstract void | close() 关闭该流并释放与之关联的所有资源。(因为给个子类实现方式是不一样的,所以抽象) |
int | read() 读取单个字符。(读取方式1:此方法返回的是一个字符,当读取到文件末尾时返回-1) |
int | read(char[] cbuf) 将字符读入数组。(读取方式2:此方法返回的是读到的字符个数,cbuf是自定义的用来存储读取到的字符的数组,长度最好定义为1024的整数倍,1kb,字符转成字符串必须用new String(char[],offset,length)这种形式,因为不这样定义最后一次读取时可能读取到与上次重叠的元素。换行不同自己去添加,java会读取到windows中每行的换行符) |
abstract int | read(char[] cbuf, int off, int len) 将字符读入数组的某一部分。 |
long | skip(long n) 跳过字符。 |
2.1 InputStreamReader类
| 构造方法摘要 | |
|---|---|
InputStreamReader(InputStream in) 创建一个使用默认字符集的 InputStreamReader。 | |
InputStreamReader(InputStream in, Charset cs) 创建使用给定字符集的 InputStreamReader。 | |
InputStreamReader(InputStream in, String charsetName) 创建使用指定字符集的 InputStreamReader。 | |
| 方法摘要 | |
|---|---|
String | getEncoding() 返回此流使用的字符编码的名称。 |
2.2 FileReader类
FileWriter字符集:采用平台默认字符编码
| 构造方法摘要 | |
|---|---|
FileReader(File file) 在给定从中读取数据的 File 的情况下创建一个新 FileReader。 | |
FileReader(String fileName) 在给定从中读取数据的文件名的情况下创建一个新 FileReader。(如果文件不存在则抛出FileNotFoundException()) | |
(1)代码演示:(将一个文件读取并打印在控制台上)
import java.io.*;
/**
*将一个文件读取并打印在控制台上
*/
class java
{
public static void main(String[] args){
FileReader fr = null;
try{
fr = new FileReader("t03.java");//指定读取的文件
char[] chr = new char[1024];//定义存储数据的数组
int length = 0;//定义判断标记,数组可用数据长度
while((length=fr.read(chr))!=-1){
System.out.print(String.valueOf(chr,0,length));
}
}catch(IOException e){
System.out.println(e.toString());
}finally{//保证一定关闭资源
if(fr!=null)//防止抛异常后空指针的出现
try{
fr.close();//关闭资源
}catch(IOException e){
System.out.println(e.toString());
}
}
}
}
(2)代码演示:(将D盘的一个文本文件拷贝到E盘)
/**
*将D盘一个文本文件复制到E盘
*/
class java
{
public static void main(String[] args){
FileReader fr = null;
FileWriter fw = null;
try{
fr = new FileReader("t03.java");//指定读取的文件
fw = new FileWriter("E:\\java复制的文件.txt");//指定复制的地址与文件名
char[] chr = new char[1024];//定义存储数据的数组
int length = 0;//定义判断标记,数组可用数据长度
while((length=fr.read(chr))!=-1){
fw.write(String.valueOf(chr,0,length));
fw.flush();
}
}catch(IOException e){
System.out.println(e.toString());
}finally{//保证一定关闭资源
if(fr!=null)//防止抛异常后空指针的出现
try{
fr.close();//关闭资源
}catch(IOException e){
System.out.println(e.toString());
}
if(fw!=null)
try{
fw.close();//关闭资源
}catch(IOException e){
System.out.println(e.toString());
}
}
}
}3.缓冲区
意义:缓冲区的出现是为了增加流操作数据的效率的,所有在创建缓冲区之前,一定要有流对象。
知识:下载工具中就有缓冲区的存在,表示先把数据放在一块设定好大小的内存当中——缓冲区,然后当缓冲区填满后再传输进硬盘
3.1 BufferedWriter类
| 构造方法摘要 | |
|---|---|
BufferedWriter(Writer out) 创建一个使用默认大小输出缓冲区的缓冲字符输出流。 | |
BufferedWriter(Writer out, int sz) 创建一个使用给定大小输出缓冲区的新缓冲字符输出流。 | |
| 方法摘要 | |
|---|---|
void | newLine() 写入一个行分隔符。(跨平台的换行符) |
3.2 BufferedReader类
| 构造方法摘要 | |
|---|---|
BufferedReader(Reader in) 创建一个使用默认大小输入缓冲区的缓冲字符输入流。 | |
BufferedReader(Reader in, int sz) 创建一个使用指定大小输入缓冲区的缓冲字符输入流。 | |
| 方法摘要 | |
|---|---|
String | readLine() 读取一个文本行。(读取方式3:能够读取一行的方法,读到末尾处返回null) |
(1)自定义一个BufferedReader(注意最后一行没有换行符时,单单只判断结束标记会导致最后一行无法返回)
class MyBufferedReader
{
private FileReader fr;
MyBufferedReader(FileReader fr){
this.fr = fr;
}
//可以每次读取一行的方法
public String myReadLine()throws IOException{
//原缓冲区是用的字符数组,这里为了方便用了StringBuilder
StringBuilder sb = new StringBuilder();
int ch;
while((ch=fr.read())!=-1){
if(ch=='\r')
continue;
else if(ch=='\n')
return sb.toString();
else
sb.append((char)ch);
}
//当最后一行没有回车时不加下边语句,最后一行不会返回
if(sb.length()!=0)
return sb.toString();
return null;
}
public void myClose()throws IOException{
fr.close();
}
}3.2.1 LineNumberReader类
1.知识点:
(1)是BufferedReader的子类,增加了修改和添加行号两个方法2.功能简介:
| 方法摘要 | |
|---|---|
int | getLineNumber() 获得当前行号。 |
void | setLineNumber(int lineNumber) 设置当前行号。 |
3.字节流
特点:当操作的数据不是本文数据,比如多媒体数据,应该用字节流操作
要点:(底层)
问题:当读取到一个多媒体文件时,由于多媒体文件数据排列不一,很可能出现其中1字节的数据是1111-1111,因为1111-1111对应的十进制数字是-1,这样读到的这一字节返回值就是-1。没有读到文件结尾处就返回了-1
解决:你会发现API中read方法返回值为int型,这是为什么?
返回的byte型-1二级制形式为1111-1111,正常转换为int型后应该是1111-1111 1111-1111 1111-1111 1111-1111。这样还是不能解决问题。
不过可以通过int型-1=>1111-1111 1111-1111 1111-1111 1111-1111 和 255=>0000-0000 0000-0000 0000-0000 1111-1111做"&"的运算。
结果为255,二级制表现形式为 0000-0000 0000-0000 0000-0000 1111-1111,你会发现在这样处理既保证元数据没有变化,又避免了-1这种情况的草出现。这也是为什么返回值不是byte型,而是int型的原因。返回的结果都在做着 &255的操作。
read()方法读取到的数据是int类型,是原来byte类型大小的四倍;而wirte()方法又在做着强转的过程,保证了写入的数据是byte类型,只往出写数据的最低8位。(内存中真正的过程)
1.OutputStream抽象类
| 方法摘要 | |
|---|---|
void | close() 关闭此输出流并释放与此流有关的所有系统资源。 |
void | flush() 刷新此输出流并强制写出所有缓冲的输出字节。() |
void | write(byte[] b) 将 b.length 个字节从指定的 byte 数组写入此输出流。 |
void | write(byte[] b, int off, int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。 |
abstract void | write(int b) 将指定的字节写入此输出流。 |
2.1 FileOutputStream类
注意:此类写数据时不用刷新,因为此类没用到缓冲区,这是对最小单位字节的操作,直接往目的地里存即可,中间过程不涉及任何转换,所以用不到缓冲区,也就不会用到刷新操作
| 构造方法摘要 | |
|---|---|
FileOutputStream(File file) 创建一个向指定 File 对象表示的文件中写入数据的文件输出流。 | |
FileOutputStream(File file, boolean append) 创建一个向指定 File 对象表示的文件中写入数据的文件输出流。 | |
FileOutputStream(String name) 创建一个向具有指定名称的文件中写入数据的输出文件流。 | |
FileOutputStream(String name, boolean append) 创建一个向具有指定 name 的文件中写入数据的输出文件流。 | |
1.InputStream抽象类
| 方法摘要 | |
|---|---|
int | available() 返回此输入流下一个方法调用可以不受阻塞地从此输入流读取(或跳过)的估计字节数。(获取目标文件中的字节数量,从此方法的字节数组长度刚好,可以不定义循环,获取文件中的全部数据。不过虚拟机启动后分配的大小为64M,用此种解决方式容易出现内存溢出。所以此方法要慎用) |
void | close() 关闭此输入流并释放与该流关联的所有系统资源。 |
abstract int | read() 从输入流中读取数据的下一个字节。 |
int | read(byte[] b) 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。 |
int | read(byte[] b, int off, int len) 将输入流中最多 len 个数据字节读入 byte 数组。 |
long | skip(long n) 跳过和丢弃此输入流中数据的 n 个字节。 |
/**
*键盘录入:定义输入设备,键盘录入,然后打印输入文本的大写形式,输入over结束本功能
*/
class java
{
public static void main(String[] args)throws IOException{
InputStream is = System.in;//键盘录入读取流
StringBuilder sb = new StringBuilder();//缓冲区
while(true){
int ch = is.read();//记住读到的字符
if(ch=='\r')
continue;
if(ch=='\n'){
String str = sb.toString();
if("over".equals(str))//输入over结束的实现
break;
System.out.println(str.toUpperCase());//输出大写形式
sb.delete(0,sb.length());//清空缓冲区
}
else
sb.append((char)ch);//存入缓冲区
}
}
}1.1 FileInputStream类
| 构造方法摘要 | |
|---|---|
FileInputStream(File file) 通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象file 指定。 | |
FileInputStream(String name) 通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。 | |
(1)代码演示:(复制一张图片)
/**
*复制一张图片到指定位置
*/
class java
{
public static void main(String[] args){
InputStream fis = null;//字节输入流
OutputStream fos = null;//字节输出流
try{
fis = new FileInputStream("MIKU.jpg");//目标文件
fos = new FileOutputStream("我的图片.jpg");//目的地
byte[] ch = new byte[1024];//缓冲区数组
int len;//数组长度
while((len=fis.read(ch))!=-1)
fos.write(ch,0,len);//写数据
}catch(IOException e){
throw new RuntimeException(e);//异常传递
}finally{
if(fis!=null)
try{
fis.close();//关闭资源
}catch(IOException e){
throw new RuntimeException(e);
}
if(fos!=null)
try{
fos.close();//关闭资源
}catch(IOException e){
throw new RuntimeException(e);
}
}
}
}3.缓冲区
注意:缓冲区一定要用read(byte[])的方法,不然不但不增加效率,而且减少效率,还不如在FileInputStream中自定义new byte[1024]这种来的有效率
特点:缓冲区就是自定义一个数组接收临时数据,存多了一起存数存储介质中
3.1 BufferedOutputStream类
| 构造方法摘要 | |
|---|---|
BufferedOutputStream(OutputStream out) 创建一个新的缓冲输出流,以将数据写入指定的底层输出流。 | |
BufferedOutputStream(OutputStream out, int size) 创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。 | |
| 方法摘要 | |
|---|---|
void | flush() 刷新此缓冲的输出流。 |
3.2 BufferedInputStream类
| 构造方法摘要 | |
|---|---|
BufferedInputStream(InputStream in) 创建一个 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。 | |
BufferedInputStream(InputStream in, int size) 创建具有指定缓冲区大小的 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。 | |
(1)缓冲区效率上的体现(三个函数分别采用三种方式复制文件)
import java.io.*;
/**
*比较缓冲区相比正常文件流效率上的优化
*/
class java
{
public static void main(String[] args)throws Exception{
long start = System.currentTimeMillis();
copy_3();
long end = System.currentTimeMillis();
System.out.println((end-start)+"毫秒");
}
public static void copy_1(){
InputStream fis = null;//字节输入流
OutputStream fos = null;//字节输出流
try{
fis = new FileInputStream("笨蛋、测试、召唤兽第一季-OP.m4a");//目标文件
fos = new FileOutputStream("01.m4a");//目的地
byte[] ch = new byte[1024];//缓冲区数组
int len;//数组长度
while((len=fis.read(ch))!=-1)
fos.write(ch,0,len);//写数据
}catch(IOException e){
throw new RuntimeException(e);//异常传递
}finally{
if(fis!=null)
try{
fis.close();//关闭资源
}catch(IOException e){
throw new RuntimeException(e);
}
if(fos!=null)
try{
fos.close();//关闭资源
}catch(IOException e){
throw new RuntimeException(e);
}
}
}
public static void copy_2()throws IOException{
BufferedInputStream bufis = new BufferedInputStream(new FileInputStream("笨蛋、测试、召唤兽第一季-OP.m4a"));
BufferedOutputStream bufos = new BufferedOutputStream(new FileOutputStream("01.m4a"));
int ch;
while((ch=bufis.read())!=-1)
bufos.write(ch);
bufis.close();
bufos.close();
}
public static void copy_3()throws IOException{
BufferedInputStream bufis = new BufferedInputStream(new FileInputStream("笨蛋、测试、召唤兽第一季-OP.m4a"));
BufferedOutputStream bufos = new BufferedOutputStream(new FileOutputStream("01.m4a"));
byte[] buf = new byte[1024];
int ch;
while((ch=bufis.read(buf))!=-1)
bufos.write(buf,0,ch);
bufis.close();
bufos.close();
}
}4.转换流
注意:下边两个类的使用方法请在标题2中去查找
文件字符流其实就是封装了本地字符集(GBK)的转换流,做了简单的封装。所以不是GBK就用转换流就好
1.OutputStreamWriter类
意义:此转换流是字节流通向字符流的桥梁,实际应用时就是为了用字符流的特殊方法操作字节流接收的数据
2.InpuStreamReader类
意义:此转换流是字节流通向字符流的桥梁,实际应用时就是为了用字符流的特殊方法操作字节流接收的数据
(1)代码实际操作
/**
*键盘录入:定义输入设备,键盘录入,然后打印输入文本的大写形式,输入over就是本功能
*/
class java
{
public static void main(String[] args)throws IOException{
//获取键盘录入,通过转换流来实现用字符缓冲读取流操作
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
//获取打印控制台的流,通过转换流老实现字符缓冲写入流操作
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));
String line = null;
while((line=bufr.readLine())!=null){
if("over".equals(line))//定义结束标记
break;
bufw.write(line.toUpperCase());//大写输出
bufw.newLine();//跨平台换行
bufw.flush();//刷新
}
bufr.close();
bufw.close();
}
}5.File类
(1)用来将文件或文件夹封装成对象,可以操作文件或文件夹的属性信息
| 构造方法摘要 | |
|---|---|
File(File parent, String child) 根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。 | |
File(String pathname) 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。 | |
File(String parent, String child) 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。 | |
| 字段摘要 | |
|---|---|
static String | pathSeparator 与系统有关的路径分隔符,为了方便,它被表示为一个字符串。 |
static char | pathSeparatorChar 与系统有关的路径分隔符。 |
static String | separator 与系统有关的默认名称分隔符,为了方便,它被表示为一个字符串。 |
static char | separatorChar 与系统有关的默认名称分隔符。 |
1 功能简介:
1.1 创建
| 方法摘要 | |
|---|---|
boolean | createNewFile() 当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。(文件已存在时则不重新创建) |
static File | createTempFile(String prefix, String suffix) 在默认临时文件目录中创建一个空文件,使用给定前缀和后缀生成其名称。(创建临时文件) |
static File | createTempFile(String prefix, String suffix, File directory) 在指定目录中创建一个新的空文件,使用给定的前缀和后缀字符串生成其名称。(创建临时文件) |
boolean | mkdir() 创建此抽象路径名指定的目录。(只能创建一级目录) |
boolean | mkdirs() 创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。(可以创建多级目录) |
1.2 删除
| 方法摘要 |
|---|
boolean | delete() 删除此抽象路径名表示的文件或目录。(删除失败返回false,可能文件正在运行无法删除,当程序出现异常也可能无法删除) |
void | deleteOnExit() 在虚拟机终止时,请求删除此抽象路径名表示的文件或目录。 |
1.3 判断
| 方法摘要 | |
|---|---|
boolean | canExecute() 测试应用程序是否可以执行此抽象路径名表示的文件。 |
boolean | canRead() 测试应用程序是否可以读取此抽象路径名表示的文件。 |
boolean | canWrite() 测试应用程序是否可以修改此抽象路径名表示的文件。 |
int | compareTo(File pathname) 按字母顺序比较两个抽象路径名。 |
boolean | equals(bject obj) 测试此抽象路径名与给定对象是否相等。 |
boolean | exists() 测试此抽象路径名表示的文件或目录是否存在。 |
boolean | isAbsolute() 测试此抽象路径名是否为绝对路径名。 |
boolean | isDirectory() 测试此抽象路径名表示的文件是否是一个目录。(在判断是否是目录时要先判断目录是否存在) |
boolean | isFile() 测试此抽象路径名表示的文件是否是一个标准文件。(在判断是否是文件时要先判断文件是否存在) |
boolean | isHidden() 测试此抽象路径名指定的文件是否是一个隐藏文件。 |
1.4 获取信息
| 方法摘要 | |
|---|---|
String | getName() 返回由此抽象路径名表示的文件或目录的名称。 |
String | getParent() 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。 |
File | getParentFile() 返回此抽象路径名父目录的抽象路径名;如果此路径名没有指定父目录,则返回 null。 |
String | getPath() 将此抽象路径名转换为一个路径名字符串。(封装了什么路径就返回什么路径) |
File | getAbsoluteFile() 返回此抽象路径名的绝对路径名形式。 |
String | getAbsolutePath() 返回此抽象路径名的绝对路径名字符串。(只返回绝对路径) |
long | lastModified() 返回此抽象路径名表示的文件最后一次被修改的时间。 |
long | length() 返回由此抽象路径名表示的文件的长度。 |
static File[] | listRoots() 列出可用的文件系统根。(获取系统中全部有效盘符) |
String[] | list() 返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中的文件和目录。(获取指定目录下全部文件和文件夹的名称) |
String[] | list(FilenameFilter filter) 返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
File[] | listFiles() 返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。(获取一个目录中全部的文件对象) |
File[] | listFiles(FileFilter filter) 返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
File[] | listFiles(FilenameFilter filter) 返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
1.5 移动
| 方法摘要 | |
|---|---|
boolean | renameTo(File dest) 重新命名此抽象路径名表示的文件。 |
2.FilenameFilter接口
意义:这是文件名过滤器
| 方法摘要 | |
|---|---|
boolean | accept(File dir, String name) 测试指定文件是否应该包含在某一文件列表中。 |
3.FileFilter接口
意义:这是文件名过滤器
| 方法摘要 | |
|---|---|
boolean | accept(File pathname) 测试指定抽象路径名是否应该包含在某个路径名列表中。 |
import java.io.*;
/**
*文件名过滤器
*/
class java
{
public static void main(String[] args)throws Exception{
File mainDir = new File("F:\\我妹妹最近有点怪");
File[] arr = mainDir.listFiles(new FileFilter(){//传入文件名过滤器
public boolean accept(File pathname){
if(pathname.getName().endsWith(".mkv"))//判断是否是mkv格式
return true;
return false;
}
});
for(File f : arr){
System.out.println(f);//获取文件信息打印在控制台上
}
}
}4.递归
(1)事实:就是函数自身运行的过程中调用自身。递归需要限定条件才能实现,不然就是无限循环
(2)代码演示:(最简单的递归)
/**
*最简单的递归,递归就是函数自身运行时调用自身
*/
class java
{
public static void main(String[] args){
getContent(new File("E:\\新建文件夹"));
}
public static void getContent(File dir){
File[] files = dir.listFiles();
for(File file : files){
if(file.isDirectory())
getContent(file);
else
System.out.println(file);
}
}
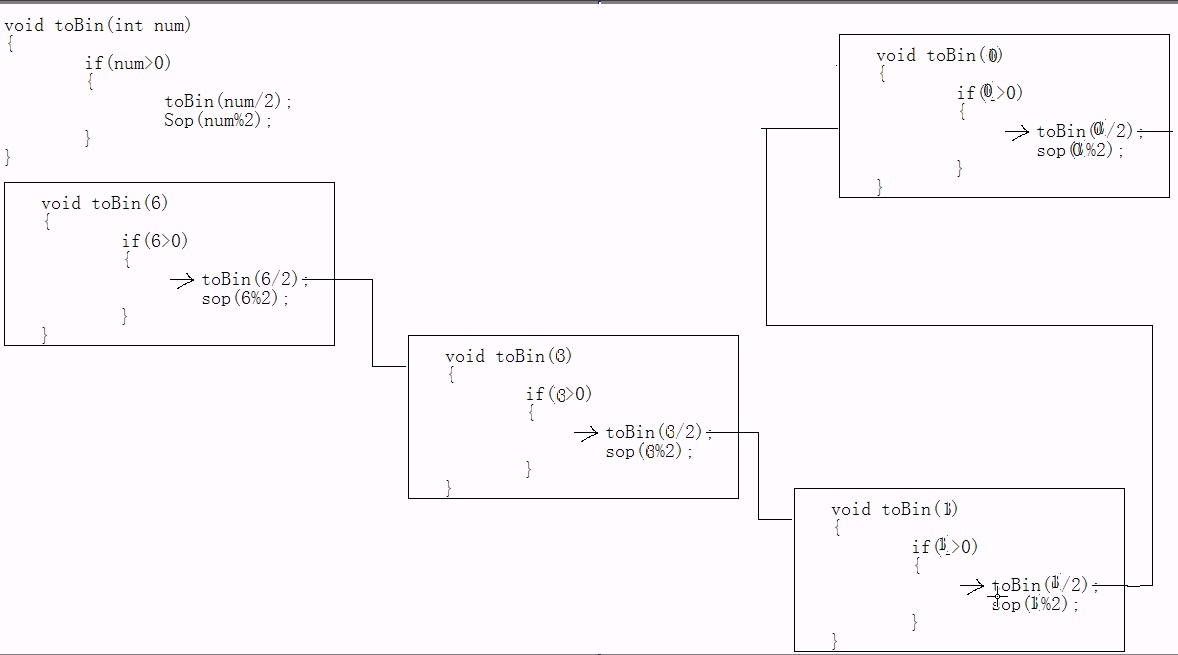
}(3)底层运算样图(以把6转换为二进制递归为例)
(4)递归与循环的优劣
<1>.递归算法:
优点:代码简洁、清晰,并且容易验证正确性。(如果你真的理解了算法的话,否则你更晕)
缺点:它的运行需要较多次数的函数调用,如果调用层数比较深,需要增加额外的堆栈处理,比如参数传递需要压栈等操作,会对执行效率有一定影响。但是,对于某些问题,如果不使用递归,那将是极端难看的代码。 递归次数太多,超出栈内寸的空间,内存溢出
<2>.循环算法:
优点:速度快,结构简单。
缺点:并不能解决所有的问题。有的问题适合使用递归而不是循环。如果使用循环并不困难的话,最好使用循环。
递归算法 和循环算法总结
1. 一般递归调用可以处理的算法,也通过循环去解决常需要额外的低效处理 。
2. 现在的编译器在优化后,对于多次调用的函数处理会有非常好的效率优化,效率未必低于循环。
(5)代码演示:(带层级的列出文件夹下的所有内容)
import java.io.*;
class java
{
public static void main(String[] args){
getContent(new File("E:\\动漫MAD"),0);
}
//添加层级字符串
public static String getLevel(int level){
StringBuilder sb = new StringBuilder();
sb.append("|--");
for(int x=0;x<level;x++){
//sb.append("|--");
sb.insert(0," ");
}
return sb.toString();
}
//递归得到目录下的全部内容
public static void getContent(File dir,int level){
File[] files = dir.listFiles();
level++;
for(File file : files){
if(!file.isHidden() && file.isDirectory())
getContent(file,level);
else
System.out.println(getLevel(level)+file);
}
}
}6 打印流
(1)注意:打印的流全是输出流,只是分为字符和字节两种
(2)打印流的好处:可以对基本数据类型直接操作,保证数据的原样性将数据打印
(3)打印流非常常用,必须会用。打印流特点方法 => println
1.PrintStream类
| 构造方法摘要 | |
|---|---|
PrintStream(File file) 创建具有指定文件且不带自动行刷新的新打印流。 (File对象) | |
PrintStream(File file, String csn) 创建具有指定文件名称和字符集且不带自动行刷新的新打印流。(File对象) | |
PrintStream(OutputStream out) 创建新的打印流。(字节输出流) | |
PrintStream(OutputStream out, boolean autoFlush) 创建新的打印流。(字节输出流,如果标记为true,println、printf、format方法将自动刷新) | |
PrintStream(String fileName) 创建具有指定文件名称且不带自动行刷新的新打印流。(字符串路径) | |
2.PrintWriter类
| 构造方法摘要 | |
|---|---|
PrintWriter(File file) 使用指定文件创建不具有自动行刷新的新 PrintWriter。(File对象) | |
PrintWriter(File file, String csn) 创建具有指定文件和字符集且不带自动刷行新的新 PrintWriter。(File对象) | |
PrintWriter(OutputStream out) 根据现有的 OutputStream 创建不带自动行刷新的新 PrintWriter。(字节输出流) | |
PrintWriter(OutputStream out, boolean autoFlush) 通过现有的 OutputStream 创建新的 PrintWriter。(字节输出流,如果标记为true,println、printf、format方法将自动刷新) | |
PrintWriter(String fileName) 创建具有指定文件名称且不带自动行刷新的新 PrintWriter。(字符串路径) | |
PrintWriter(String fileName, String csn) 创建具有指定文件名称和字符集且不带自动行刷新的新 PrintWriter。(字符串路径) | |
PrintWriter(Writer out) 创建不带自动行刷新的新 PrintWriter。(字符输出流) | |
PrintWriter(Writer out, boolean autoFlush) 创建新 PrintWriter。(字符输出流,如果标记为true,println、printf、format方法将自动刷新) | |
import java.io.*;
/**
*打印流
*/
class java
{
public static void main(String[] args)throws Exception{
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
String line = null;
PrintWriter pw = new PrintWriter(new FileWriter("Upper.txt"),true);//自动刷新
while((line=bufr.readLine())!=null){
if("over".equals(line))//结束标记
break;
pw.println(line.toUpperCase());//打印流不用刷新和换行
}
bufr.close();
pw.close();
}
}7.合并流
1.SequenceInputStream类
(1)意义:合并多个流为一个大流,从第一个开始一直读出最后一个的数据。可以同时读取多个文件的数据合并到一个文件中
| 构造方法摘要 | |
|---|---|
SequenceInputStream(Enumeration<? extends InputStream> e) 通过记住参数来初始化新创建的 SequenceInputStream,该参数必须是生成运行时类型为 InputStream 对象的 Enumeration 型参数。 | |
SequenceInputStream(InputStream s1, InputStream s2) 通过记住这两个参数来初始化新创建的 SequenceInputStream(将按顺序读取这两个参数,先读取 s1,然后读取 s2),以提供从此SequenceInputStream 读取的字节。 | |
2.切割文件
(1)切割的原理:通过定义一个固定大小的byte[]型数组,来知道每次写入数据的具体大小
(2)切割文件与合并文件代码实现:
import java.io.*;
import java.util.*;
/**
*分割与合并多个文件
*/
class java
{
public static void main(String[] args)throws Exception{
File file = new File("d:\\银魂第二季-ED1.m4a");
spitFile(file);
combineFile();
}
//分割文件
public static void spitFile(File file)throws Exception{
BufferedInputStream bufis = new BufferedInputStream(new FileInputStream(file));
BufferedOutputStream bufos = new BufferedOutputStream(new FileOutputStream("d:\\分割文件\\1.part"));;
byte[] buf = new byte[1024*1024];
for(int countFile=2,countSize=0,len;(len=bufis.read(buf))!=-1;countSize++){
if(countSize==5){//限制每个文件大小为5M
bufos = new BufferedOutputStream(new FileOutputStream("d:\\分割文件\\"+countFile+".part"));
countFile++;
countSize = 0;
}
bufos.write(buf,0,len);//写入1M数据
}
bufis.close();
bufos.close();
}
//合并文件
public static void combineFile()throws Exception{
Vector<InputStream> list = new Vector<InputStream>();
list.add(new FileInputStream("d:\\分割文件\\1.part"));
list.add(new FileInputStream("d:\\分割文件\\2.part"));
Enumeration<InputStream> en = list.elements();
BufferedInputStream bufis = new BufferedInputStream(new SequenceInputStream(en));//合并多个流
byte[] buf = new byte[1024];
int len;
PrintStream ps = new PrintStream("d:\\我的银魂.m4a");
while((len=bufis.read(buf))!=-1)
ps.write(buf,0,len);
bufis.close();
ps.close();
}
}8.操作对象的流
(1)意义:对堆内存中的对象进行持久化存储,也称为对象的序列化
1.ObjectOutputStream类
| 构造方法摘要 | |
|---|---|
| ObjectOutputStream(OutputStream out) 创建写入指定 OutputStream 的 ObjectOutputStream。 |
| 方法摘要 | |
|---|---|
void | writeObject(Object obj) 将指定的对象写入 ObjectOutputStream。 |
void | writeUTF(String str) 以 UTF-8 修改版格式写入此 String 的基本数据。(这里使用的是修改版的UTF-8,中文占用4个字节) |
2.ObjectInputStream类
| 构造方法摘要 | |
|---|---|
| ObjectInputStream(InputStream in) 创建从指定 InputStream 读取的 ObjectInputStream。 |
| 方法摘要 |
|---|
Object | readObject() 从 ObjectInputStream 读取对象。 |
String | readUTF() 读取 UTF-8 修改版格式的 String。(这里使用的是修改版的UTF-8) |
3.Serializable接口
(1)说明:你会发现这个接口没有成员,这种接口一般被称为标记接口,就等于给实现它的类做了标记
(2)原理:ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;每个类都有一个serialVersionUID号,这样类就被ID所标识,其所生成的对象也被这个ID锁标识,这个ID一般被编译器所用。当类改变时,其ID也会随之改变,持久化存储的对象会因为ID号与新的类不同而产生不匹配的结果。这个UID是通过类中的所有成员的数字标识(数字签名)所得出的
(3)如果不想让系统自动根据成员生成UID,可由我们自动固定UID,建立子类成员变量——public static final long serialVersionUID = 42L;来让UID固定不变
(4)只有堆内存中的数据能够序列化,方法区中的静态成员无法序列化
(5)如果你不想让非静态成员序列化,那么可以用transient关键字修饰
(6)对象序列化存储的本地文件命名格式可以为:类名.object
4.transient关键字
import java.io.*;
/**
*对象的序列化
*/
class java
{
public static void main(String[] args)throws Exception{
//write(new Person[]{new Person("张天成",25),new Person("张天",5)});//传入多个对象
read(new File("d:\\save.object"));
}
//读取文件中的对象
public static void read(File file)throws Exception{
//读取序列化对象
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new FileInputStream(file)));
Person[] p = (Person[])ois.readObject();//获取对象数组
for(Person per : p){//解析出数组中的全部对象取出对象
per.get();
}
}
public static <T> void write(T t)throws IOException{
//序列化对象
ObjectOutputStream oos = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream("d:\\save.object")));
oos.writeObject(t);
oos.close();
}
}
class Person implements Serializable//实现标记接口
{
private String name;
private int age;
Person(String name,int age){
this.name = name;
this.age = age;
}
public void get(){
System.out.println(name+"..."+age);
}
}9.管道流
(1)意义:一般输出流与输入流同时操作要提供一个中转站——一个数组、字符串等,而管道流能直接连接上,不用建立中转站
(2)注意:建议通过多线程的wait、nitify来控制,单线程可能会造成死锁
1.PipedInputStream类
| 构造方法摘要 | |
|---|---|
PipedInputStream() 创建尚未连接的 PipedInputStream。 | |
PipedInputStream(int pipeSize) 创建一个尚未连接的 PipedInputStream,并对管道缓冲区使用指定的管道大小。 | |
PipedInputStream(PipedOutputStream src) 创建 PipedInputStream,使其连接到管道输出流 src。 | |
| 方法摘要 | |
|---|---|
void | connect(PipedOutputStream src) 使此管道输入流连接到管道输出流 src。 |
2.PipedOutputStream类
| 构造方法摘要 | |
|---|---|
PipedOutputStream() 创建尚未连接到管道输入流的管道输出流。 | |
PipedOutputStream(PipedInputStream snk) 创建连接到指定管道输入流的管道输出流。 | |
| 方法摘要 | |
|---|---|
void | connect(PipedInputStream snk) 将此管道输出流连接到接收者。 |
10.操作集中数据类型的流
1.操作基本数据类型
1.1 DataOutputStream类
(1)此流的功能与RundomAccessFile流中写基本数据类型的方法相同,不在一一举出
| 构造方法摘要 | |
|---|---|
DataOutputStream(OutputStream out) 创建一个新的数据输出流,将数据写入指定基础输出流。 | |
1.2 DataIntputStream类
| 构造方法摘要 | |
|---|---|
DataInputStream(InputStream in) 使用指定的底层 InputStream 创建一个 DataInputStream。 | |
2.操作字节数组中数据
2.1 ByteArrayOutputStream类
| 构造方法摘要 | |
|---|---|
ByteArrayOutputStream() 创建一个新的 byte 数组输出流。 | |
ByteArrayOutputStream(int size) 创建一个新的 byte 数组输出流,它具有指定大小的缓冲区容量(以字节为单位)。 | |
| 方法摘要 | |
|---|---|
int | size() 返回缓冲区的当前大小。 |
byte[] | toByteArray() 创建一个新分配的 byte 数组。 |
String | toString() 使用平台默认的字符集,通过解码字节将缓冲区内容转换为字符串。 |
String | toString(String charsetName) 使用指定的 charsetName,通过解码字节将缓冲区内容转换为字符串。 |
void | writeTo(OutputStream out) 将此 byte 数组输出流的全部内容写入到指定的输出流参数中,这与使用 out.write(buf, 0, count) 调用该输出流的 write 方法效果一样。 |
2.2 ByteArrayInputStream类
| 构造方法摘要 | |
|---|---|
ByteArrayInputStream(byte[] buf) 创建一个 ByteArrayInputStream,使用 buf 作为其缓冲区数组。 | |
ByteArrayInputStream(byte[] buf, int offset, int length) 创建 ByteArrayInputStream,使用 buf 作为其缓冲区数组。 | |
| 方法摘要 | |
|---|---|
void | close() 关闭 ByteArrayInputStream 无效。 |
3.操作字符数组中数据
3.1 CharArrayWriter类
| 构造方法摘要 | |
|---|---|
CharArrayWriter() 创建一个新的 CharArrayWriter。 | |
CharArrayWriter(int initialSize) 创建一个具有指定初始大小的新 CharArrayWriter。 | |
| 方法摘要 | |
|---|---|
char[] | toCharArray() 返回输入数据的副本。 |
String | toString() 将输入数据转换为字符串。 |
3.2 CharArrayReader类
| 构造方法摘要 | |
|---|---|
CharArrayReader(char[] buf) 根据指定的 char 数组创建一个 CharArrayReader。 | |
CharArrayReader(char[] buf, int offset, int length) 根据指定的 char 数组创建一个 CharArrayReader。 | |
4.操作字符串中数据
4.1 StringWriter类
| 构造方法摘要 | |
|---|---|
StringWriter() 使用默认初始字符串缓冲区大小创建一个新字符串 writer。 | |
StringWriter(int initialSize) 使用指定初始字符串缓冲区大小创建一个新字符串 writer。 | |
| 方法摘要 | |
|---|---|
StringBuffer | getBuffer() 返回该字符串缓冲区本身。 |
String | toString() 以字符串的形式返回该缓冲区的当前值。 |
4.2 StringReader类
注意:此类会抛出异常,请处理,虽说不知道为什么
| 构造方法摘要 | |
|---|---|
StringReader(String s) 创建一个新字符串 reader。 | |
11.RandomAccessFile类
(1)意义:此类实例支持对随机访问文件的读取和写入,对象内部封装了数组和指针,通过指针来操作数据
(2)特点:不算是IO体系中的子类,直接继承自Object
(3)重点:能够实现随机读写数据——就是读取某具体位置的数据或者在某个具体位置写入数据。基于这个原理可以实现数据的分段写入,并用多线程操作不同数据段来增加效率。如果让多线程操作其他的流,写完数据后就会发现写入的数据是错乱的。这就是随机读写访问,下载就是基于这个原理
(4)注意:此流不会覆盖源文件,而是在其基础上复写文件
| 构造方法摘要 | |
|---|---|
RandomAccessFile(File file, String mode) 创建从中读取和向其中写入(可选)的随机访问文件流,该文件由 File 参数指定。(只能操作文件) | |
RandomAccessFile(String name, String mode) 创建从中读取和向其中写入(可选)的随机访问文件流,该文件具有指定名称。(mode有四种格式:"r"、“rw"这两种较常用) | |
"r":以只读方式打开。调用结果对象的任何 write 方法都将导致抛出 IOException
"rw":打开以便读取和写入。如果该文件尚不存在,则尝试创建该文件
| 方法摘要 | |
|---|---|
int | read() 从此文件中读取一个数据字节。 |
int | read(byte[] b) 将最多 b.length 个数据字节从此文件读入 byte 数组。 |
int | read(byte[] b, int off, int len) 将最多 len 个数据字节从此文件读入 byte 数组。 |
boolean | readBoolean() 从此文件读取一个 boolean |
byte | readByte() 从此文件读取一个有符号的八位值。 |
char | readChar() 从此文件读取一个字符。 |
double | readDouble() 从此文件读取一个 double。 |
float | readFloat() 从此文件读取一个 float。 |
int | readInt() 从此文件读取一个有符号的 32 位整数。 |
String | readLine() 从此文件读取文本的下一行。 |
long | readLong() 从此文件读取一个有符号的 64 位整数。 |
short | readShort() 从此文件读取一个有符号的 16 位数。 |
String | readUTF() 从此文件读取一个字符串。 |
void | write(byte[] b) 将 b.length 个字节从指定 byte 数组写入到此文件,并从当前文件指针开始。 |
void | write(byte[] b, int off, int len) 将 len 个字节从指定 byte 数组写入到此文件,并从偏移量 off 处开始。 |
void | write(int b) 向此文件写入指定的字节。 |
void | writeBoolean(boolean v) 按单字节值将 boolean 写入该文件。 |
void | writeByte(int v) 按单字节值将 byte 写入该文件。 |
void | writeBytes(String s) 按字节序列将该字符串写入该文件。 |
void | writeChar(int v) 按双字节值将 char 写入该文件,先写高字节。 |
void | writeChars(String s) 按字符序列将一个字符串写入该文件。 |
void | writeDouble(double v) 使用 Double 类中的 doubleToLongBits 方法将双精度参数转换为一个 long,然后按八字节数量将该 long 值写入该文件,先定高字节。 |
void | writeFloat(float v) 使用 Float 类中的 floatToIntBits 方法将浮点参数转换为一个 int,然后按四字节数量将该 int 值写入该文件,先写高字节。 |
void | writeInt(int v) 按四个字节将 int 写入该文件,先写高字节。 |
void | writeLong(long v) 按八个字节将 long 写入该文件,先写高字节。 |
void | writeShort(int v) 按两个字节将 short 写入该文件,先写高字节。 |
void | writeUTF(String str) 使用 modified UTF-8 编码以与机器无关的方式将一个字符串写入该文件。(这里使用的是修改版的UTF-8) |
void | seek(long pos) 设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作。(pos是字节数,可以通过此方法把数据写到指定位置,不管前边写没写;或者覆盖此位置之前的数据)(这是此类最重要的方法) |
int | skipBytes(int n) 尝试跳过输入的 n 个字节以丢弃跳过的字节。(跳过指定字节数,相对的) |
import java.io.*;
import java.util.*;
/*
需求:有五个学生,每个学生有3门课的成绩,从键盘输入以上数据(包括姓名,三门课成绩)
输入格式:如:张三 30, 40, 60计算出总成绩,并把学生的信息和计算出来的总分数高低顺序高低顺序存放在磁盘文件"stud.txt"
思路:1.首先键盘录入是可以这样表示
*/
class java
{
public static void main(String[] args)
{
new StudentIn().inputInfo();
}
}
class Student implements Comparable<Student>
{
private String name;
private int math;
private int en;
private int chis;
private int bio;
//初始化成员
Student(String name,int math,int en, int chis,int bio){
this.name = name;
this.math = math;
this.en = en;
this.chis = chis;
this.bio = bio;
}
//获取成员
public int getMath(){
return math;
}
public int getEn(){
return en;
}
public int getChis(){
return chis;
}
public int getBio(){
return bio;
}
public int getGrade(){
return math+en+chis+bio;
}
public String getName(){
return this.name;
}
//复写hashCode方法
public int hashCode(){
return name.hashCode()+math*6+en*2+chis*9+bio*7;
}
//复习equal方法
public boolean equals(Object o){
if(!(o instanceof Student))
throw new ClassCastException();
Student s = (Student)o;
return name.equals(s.getName()) && getGrade() == s.getGrade();
}
//判断大小
public int compareTo(Student s){
if(getGrade()==s.getGrade())
return name.compareTo(s.getName());
else
return new Integer(getGrade()).compareTo(s.getGrade());
}
}
class StudentIn
{
public void inputInfo(){
File file = new File("studentInfo.text");//获取数据存储文件地址
BufferedReader bufr = null;
PrintWriter pw = null;
//存储数据的集合,对学生成绩总分进行排序,按照从大到小的顺序
TreeSet<Student> ts = new TreeSet<Student>(Collections.reverseOrder());
try{
bufr = new BufferedReader(new InputStreamReader(System.in));
pw = new PrintWriter(new BufferedWriter(new FileWriter(file)),true);
for(int x=0;x<3;x++){//存入三个学生
System.out.print("请输入学生名称:");
String name = bufr.readLine();
System.out.print("请输入数学成绩:");
int math = Integer.parseInt(bufr.readLine());
System.out.print("请输入英语成绩:");
int en = Integer.parseInt(bufr.readLine());
System.out.print("请输入语文成绩:");
int chis = Integer.parseInt(bufr.readLine());
System.out.print("请输入生物成绩:");
int bio = Integer.parseInt(bufr.readLine());
System.out.println("======================");
Student s = new Student(name,math,en,chis,bio);
ts.add(s);//存入TreeSet集合,并进行排序
}
//写入数据到文件
for(Student s : ts){
pw.println("姓名:"+s.getName());
pw.println("数学:"+s.getMath());
pw.println("英语:"+s.getEn());
pw.println("语文:"+s.getChis());
pw.println("生物:"+s.getBio());
pw.println("总分:"+s.getGrade());
pw.println();
}
pw.close();
bufr.close();//便于观看,未添加到finally代码块
}catch(IOException e){
throw new RuntimeException("存入数据出错",e);
}
System.out.print("========信息存入成功========");
}
}














 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









