







1、基础概念:hadoop是适合大数据的分布式存储与计算的平台。
2、硬件和软件要求:
服务器:EXSI,可以部署多个虚拟机
PC:Linux,windows+Cygwin
SSH:客户端 SecurtCRT
Vmware clinet: 管理Esxi
3、所用框架
主框架:
(核心项目)HDFS:文件系统,用来存储文件
(核心项目)MapReduce:并行计算HDFS中的数据
Hbase:分布式按列存储数据库,能够快速响应
Hive:分布式按列存储数据仓库,让hadoop能够支持sql,使用面广,但是要求较高,
pig:与hive相似用来处理数据,但是实现方式是按照步骤一步一步实现
4、hadoop优点:
1)扩容能力强:能够存储够大的数据
2)成本低:可以用多个普通服务器来构建一个强大的服务器
3)效率高:同一批数据可以并行处理
4)可靠性:能够自动维护
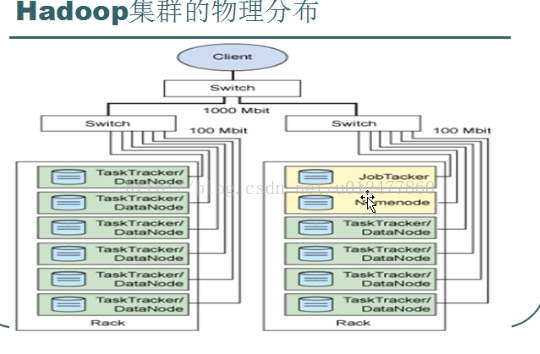
HDFS架构:
主从结构
主节点:只有一个:namenode
接收用户操作请求
维护文件系统的目录结构
管理文件和block(块)之间的关系,block与datanode之间的关系
从节点:有很多个:datanodes
存储文件
文件被分成block存储在磁盘上
保证数据安全,文件有副本
MapReduce架构:
主从结构
主节点:只有一个:JobTracker
接收用户提交的计算任务
把计算任务分给TaskTrackers执行
监控TaskTracker的执行情况
从节点,有很多个:TaskTrackers
执行JobTracker分配的计算任务
5、部署方式
本地模式:直接存储在linux磁盘上,不存HDFS上
伪分布模式:一台机器上,其他与集群类似
集群模式:















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









