










猿创征文|初识TiDB生命周期
0、简介
TiDB 是 PingCAP 公司基于 GoogleSpanner/F1论文实现的开源分布式 NewSQL 数据库。实现了自动的水平伸缩,强一致性的分布式事务,基于 Raft 算法的多副本复制等重要 NewSQL 特性。 TiDB 结合了 RDBMS 和 NoSQL 的优点,部署简单,在线弹性扩容和异步表结构变更不影响业务, 真正的异地多活及自动故障恢复保障数据安全,同时兼容 MySQL 协议,使迁移使用成本降到极低。
TiDB 具备如下 NewSQL 核心特性:
SQL支持 (TiDB 是 MySQL 兼容的)
水平线性弹性扩展
分布式事务
跨数据中心数据强一致性保证
故障自恢复的高可用
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
1、前言
通过前面的简介我们了解到TiDB能做什么,以及他的一些特性,工作也有七八个年头了,从单体应用,到分布式,微服务,都离不开数据库,所使用的数据库有Mysql,Oracle,Postgrasql等等一些市面上主流的数据库,那么今天为什么来单独说下这个TiDB呢,TiDB是一款同时支持在线事务处理与在线分析处理 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。可以提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
2、周期
TiDB在公司,经历了几个周期,如下图:
从最初的测试、引入,到大规模迁移,集群数爆炸式增长,到TiDB运维体系整体完善,引入套餐与账单,再到疫情来临,资源紧张,需要进行存储空间优化、小集群优化,到了精细化运维的阶段,再到后面计划的云化阶段,来真正释放资源。

3、TiDB硬件环境
3.1、 操作系统及平台要求
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.3 及以上的 7.x 版本,8.4 及以上的 8.x 版本 |
| CentOS | 7.3 及以上的 7.x 版本,8.4 及以上的 8.x 版本 |
| Oracle Enterprise Linux | 7.3 及以上的 7.x 版本 |
| Amazon Linux | 2 |
| Ubuntu LTS | 16.04 及以上的版本 |
3.2、 编译和运行 TiDB 所依赖的库
| 编译和构建 TiDB 所需的依赖库 | 版本 |
|---|---|
| Golang | 1.18.5 及以上版本 |
| Rust nightly-2022-07-31 | 及以上版本 |
| GCC | 7.x |
| LLVM | 13.0 及以上版本 |
4、TIDB的监控
使用TiDB-Ansible安装TiDB集群默认会安装一套Prometheus+Grafana的监控;我们使用Prometheus+Grafana对TIDB做监控。监控的架构图如下:
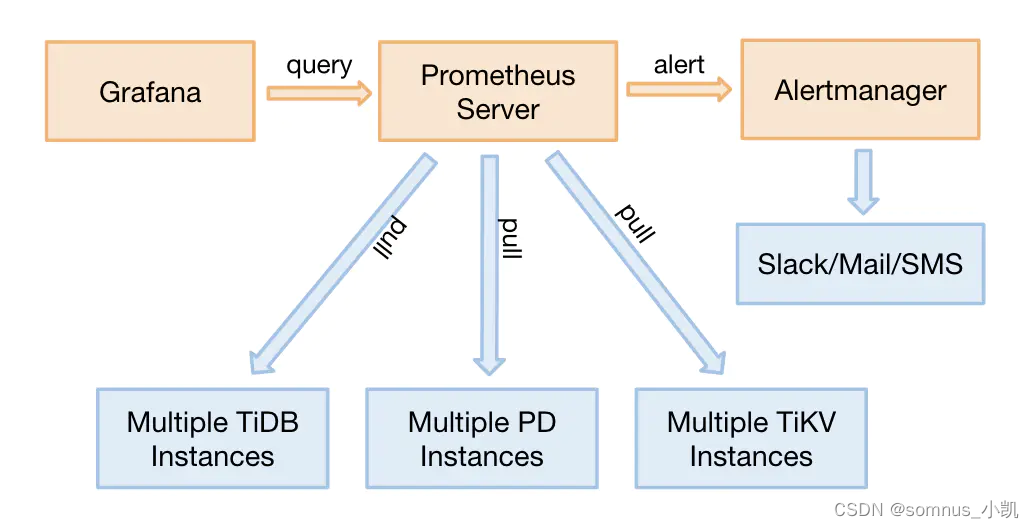
监控对于TIDB来说非常重要,建议单独对Prometheus以及Grafana深入学习。
5、问题
当前运维了大量的TiDB,从资源合理性角度 或精细化运维的角度,有如下问题:
**【问题】:**新的业务上TiDB,集群创建了半年,存储空间还小于100G,面对10个节点的TiDB,这种存是低于接入门槛的资源浪费情况,且与TiDB的运维规范不符
【方案】:
- 咨询业务增长情况,如果可以保证近期有大量增长,则可以继续保留
- 如果近期无大量增长,则回迁MySQL,可利用TiDB CDC来进行回迁
**【问题】:**已经上线有一定时间的集群,上线了很多大表,但有些表是只需要存储近期的数据即可,即历史数据可以清理,但是目前没有清理的,这种是无用数据占大量存储资源的浪费情况
【方案】:
- 与业务咨询,确认哪些表的数据可以清理
- 业务自己写程序清理
- DBA提供批量清理的方式,业务添加清理任务、保留时间即可自动清理
**【问题】:**已经上线了一定时间的集群,表无变更,不查询,这种是业务下线集群未下线的浪费情况
【方案】:
-
与业务咨询,确认是否可以整体删除、集群下线
-
DBA开发生命周期,自动扫描出未用的集群,通知业务,进行自动化下线
面对如上问题,近期组内进行了精细化运营的相关工作: -
确定迁移MySQL方案:
- 引入TiCDC,验证TiDB迁移至MySQL方案
-
开发生命周期相关程序:
- 自动获取低负载的集群
- 自动获取低存储的集群
- 自动通知业务
- 自动化回收、下线集群
-
开发数据自动清理任务:
- 利用pt工具,实现自动化分批清理
- 支持单次清理、定期清理
-
调研TiDB云化实现方式:
- 容器化部署TiDB的可行性
- TiDB的容器部署流程测试
- TiDB的容器部署性能测试
6、生命周期
生命周期的概念:是指数据库从申请到使用到下线的整个生命周期的记录。
7、TiDB生命周期
7.1、空闲集群判断条件
| 条件 | 判断阈值 |
| 表更新时间 | 半年内无更新 |
| 集群运行时间 | 运行时间半年以上 |
| 六个月以内连接数 | 无连接 |
| 集群qps | 连续半年小于70000则为空闲集群 |
| 半年内工单数量 | 半年内无工单 |
| 自助查询判断 | 半年内自助查询次数 |
7.2、表更新时间
表的更新时间,TiDB是不太好实现的,在MySQL里面,我们可以看文件的更新时间来确认表的更新时间。
TiDB里面有一个命令:SHOW STATS_META,可以查看表的总行数以及修改的行数等信息。
| 语法元素 | 说明 |
|---|---|
| db_name | 数据库名 |
| table_name | 表名 |
| partition_name | 分区名 |
| update_time | 更新时间 |
| modify_count | 修改的行数 |
| row_count | 总行数 |
以为这个update_time可以作为表的更新时间,但实际看是不可以的,这个更新时间:
- 在表结构变更时会变化
- 在analyze之后也会变
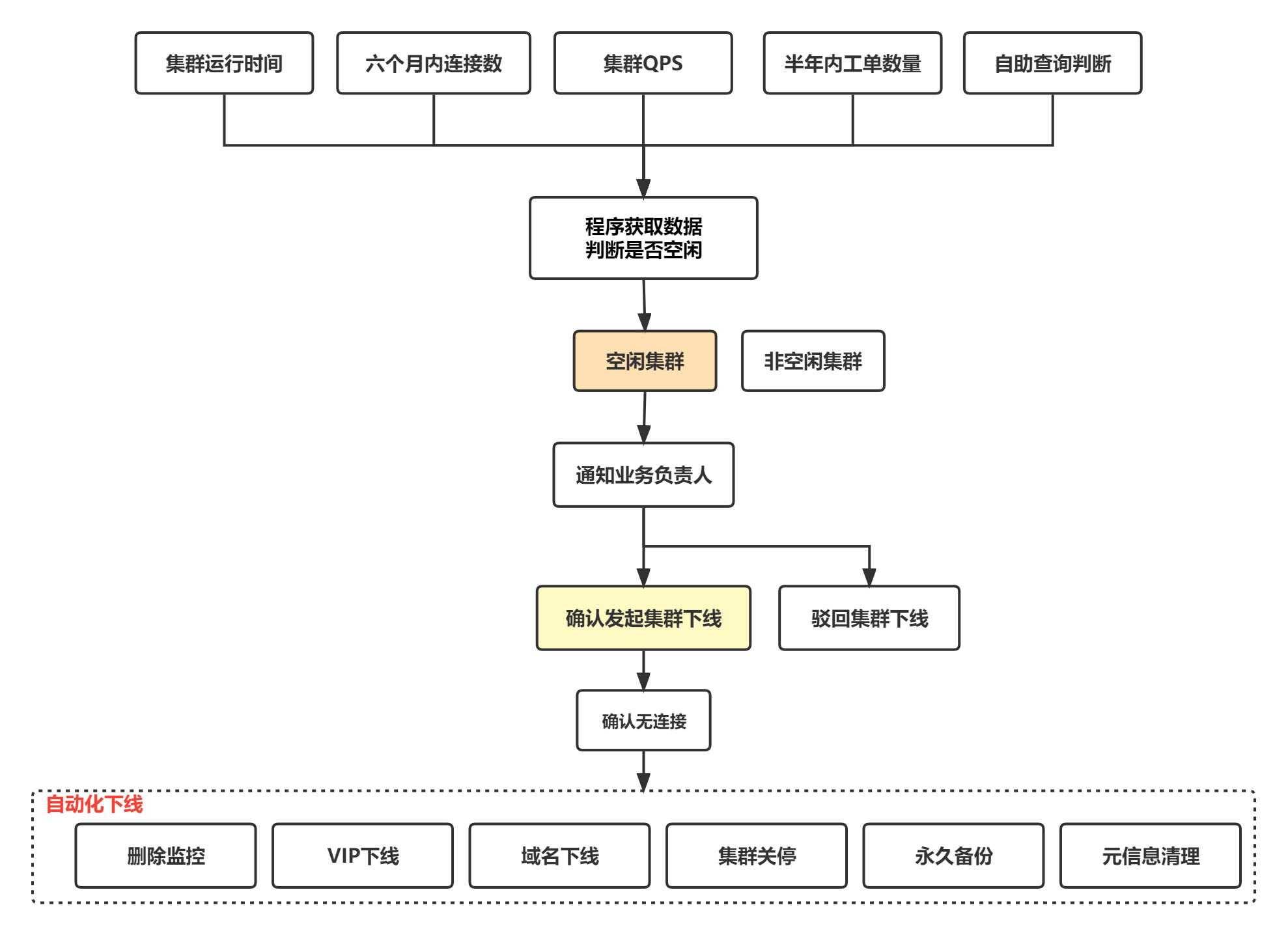
7.3、实现架构
- 通过获取集群的相关信息,判定集群是否为空闲集群
- 空闲集群则进行集群下线、备份保留等
8、TiDB其他工具
8.1、 mydumper/loader
备份恢复工具,使用 mydumper 从 TiDB 导出数据进行备份,然后用 loader 将其导入到 TiDB 里面进行恢复。虽然TiDB 也支持使用 MySQL 官方的 mysqldump 工具来进行数据的备份恢复工作,但相比于 mydumper /loader,性能会慢很多,大量数据的备份恢复会花费很多时间,因此并不推荐。
其mydumper/myloader是Percona开源产品,多线程MySQL逻辑备份和恢复工具。那为什么PingCAP还开发loader工具呢?官方是这么说的:在使用过程中,mydumper问题不大,但是 myloader 由于缺乏出错重试、断点续传这样的功能,使用起来很不方便。所以我们开发了 loader,能够读取mydumper 的输出数据文件,通过 mysql protocol 向 TiDB/MySQL 中导入数据。
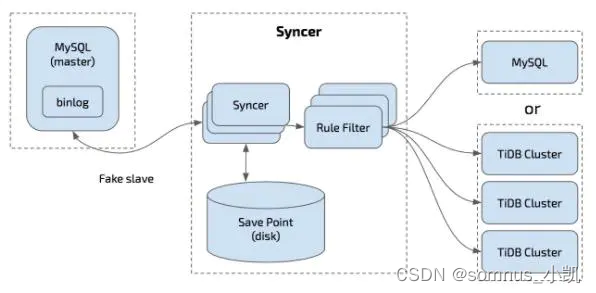
8.2、 syncer
根据MySQL binlog增量同步工具,Syncer 可以部署在任一台可以连通对应的 MySQL 和 TiDB 集群的机器上,推荐部署在 TiDB 集群。
架构图如下:
8.3、 TiDB-Binlog
TiDB-Binlog 用于收集 TiDB 的 Binlog,并提供实时备份和同步功能的商业工具。
TiDB-Binlog 支持以下功能场景:
数据同步: 同步 TiDB 集群数据到其他数据库
实时备份和恢复: 备份 TiDB 集群数据,同时可以用于 TiDB 集群故障时恢复
8.4、 PD Control
PD Control 是 PD 的命令行工具,用于获取集群状态信息和调整集群。
TiDB官方:https://pingcap.com
















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











