







为什么我要做爬虫
其实做爬虫已经有几次经历了,但从来没有把爬虫的相关工作做过总结,所以在我第三次写爬虫却还要网页搜索具体写法的时候,我决定还是自己把爬虫的相关技术记录下来。
基础版爬虫
最基础版的爬虫很简单,我们都知道爬虫其实就只是要把网页信息获取,也就是你右键Ctrl+U看到的那堆源代码,然后按照自己所需要的利用正则匹配出你要抠的内容就好了,所以最基础版的爬虫作用就在于此。
人生苦短,我们用Python。Python作为世界上我最喜欢的编程语言,也有很强大的网络工具库,在Python2.7中有利器urllib2来帮助我们实现快速爬虫。
import urllib2
response = urllib2.urlopen('http://www.douban.com/')
html = response.read()
print html
爬虫的两种方式:
- 深度优先:先爬取该网页的所有链接再把这些链接中的所有链接都获取了,最后在爬内容;
- 广度优先:先爬取某网页的链接,把该网页爬完了再去爬下一个网页的内容及里面的链接
伪装成浏览器进行爬虫
为什么需要伪装
因为好多网页都设置了反爬虫=。=一旦被发现是机器而不是人的话就被被禁止访问或者禁号的。
怎么伪装
服务器一般确定到底是机器还是人在操作是看发送数据的时候发送的信息里有没有他想要查的数据,比如User-Agent,比如Header。其中这两项也是最重要的两项,下面介绍如何获取。
- 如何获取浏览器headers信息
采用debug的方式可以将爬取的信息
# /usr/bin/env python
# -*-coding:utf-8 -*
import urllib2
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(Idebuglevel=1)
opener = urllib2.urlopen(httpHandler,httpsHandler)
urllib2.install_opener(opener)
response = urllib2.urlopen('http://www.douban.com') 最后打印出的信息如下:
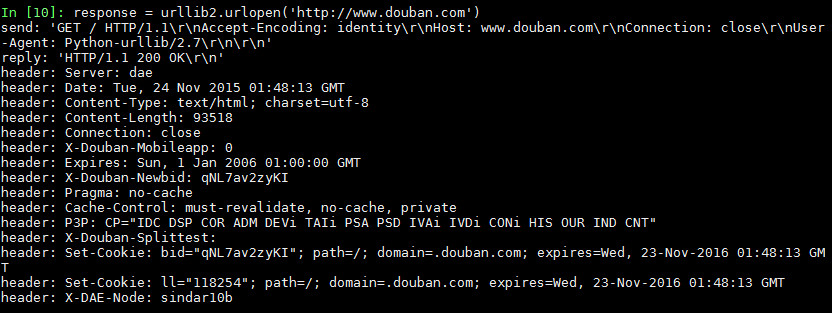
通过浏览器获取
很简单浏览器上F12,然后点击Network,刷新一下界面就可以看到你给服务器发了什么信息,服务器返回了什么信息。
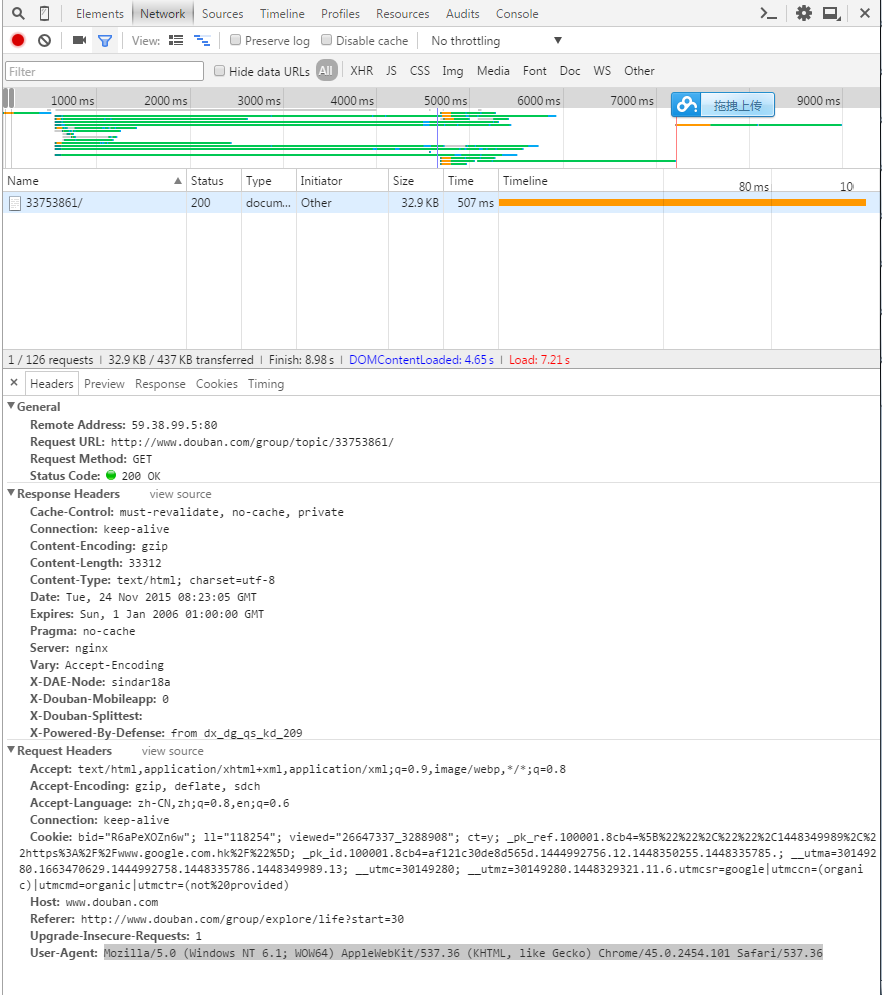
注意我上面黑色拉出来的一段就是需要的User-Agent信息
- 伪装之后需要做什么
爬网页+正则神器!
关于正则表达式的内容不在这个地方赘述了,下次单独写一篇关于正则表达式的内容。
爬虫可以使用的小tricks
- 采用sleep减慢你爬虫的速度,虽然会相对减慢速度,但这真的好过你一次一次的被封号又重新open你的程序
- 更绝一点就直接把sleep的参数设置为一个随机数=。=
- 尽量爬一个网页就保存到文本里,要不你会后悔的你真的会后悔的。别问我怎么知道~
最后,给出两个我在项目中用的代码,其实对于爬虫而言最有特点的是每个网站都不一样,所以在你确定要爬虫之前最好先解析一下网页的源代码,看看好不好爬,That’s it!
附录
百度贴吧爬虫源代码
# /usr/bin/env python
# -*-coding:utf-8 -*-
import socket
import string
import re
import urllib2
class HTML_Tool:
# 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
BgnCharToNoneRex = re.compile("(\t|\n| |<a.*?>|<img.*?>)")
# 用非 贪婪模式 匹配 任意<>标签
EndCharToNoneRex = re.compile("<.*?>")
# 用非 贪婪模式 匹配 任意<p>标签
BgnPartRex = re.compile("<p.*?>")
CharToNewLineRex = re.compile("(<br/>|</p>|<tr>|<div>|</div>)")
CharToNextTabRex = re.compile("<td>")
# 将一些html的符号实体转变为原始符号
replaceTab = [("<","<"),(">",">"),("&","&"),("&","\""),(" "," ")]
def Replace_Char(self,x):
x = self.BgnCharToNoneRex.sub("",x)
x = self.BgnPartRex.sub("\n ",x)
x = self.CharToNewLineRex.sub("\n",x)
x = self.CharToNextTabRex.sub("\t",x)
x = self.EndCharToNoneRex.sub("",x)
for t in self.replaceTab:
x = x.replace(t[0],t[1])
return x
class Baidu_Spider:
# 申明相关的属性
def __init__(self,url):
self.myUrl = url + '?see_lz=0'
self.datas = []
self.myTool = HTML_Tool()
print u'已经启动百度贴吧爬虫,咔嚓咔嚓'
# 初始化加载页面并将其转码储存
def baidu_tieba(self):
try:
# 读取页面的原始信息并将其从utf8转码
myPage = urllib2.urlopen(self.myUrl).read().decode('utf-8')
# 计算楼主发布内容一共有多少页
endPage = self.page_counter(myPage)
# 获取最终的数据
self.save_data(self.myUrl,endPage)
except UnicodeDecodeError,urllib2.URLError:
print u'不小心解码出错了,我直接跳到下一个可以么~'
pass
#用来计算一共有多少页
def page_counter(self,myPage):
# 匹配 "共有<span class="red">12</span>页" 来获取一共有多少页
myMatch = re.search(r'class="red">(\d+?)</span>', myPage, re.S)
if myMatch:
endPage = int(myMatch.group(1))
print u'爬虫报告:发现共有%d页的原创内容' % endPage
else:
endPage = 0
print u'爬虫报告:无法计算有多少页!'
return endPage
def save_data(self,url,endPage):
# 加载页面数据到数组中
self.get_data(url,endPage)
# 打开本地文件
f = open('baidu.06-16','a')
f.writelines(self.datas)
print u'爬虫报告:文件已下载到本地并打包成txt文件'
f.close()
#f.close()
# 获取页面源码并将其存储到数组中
def get_data(self,url,endPage):
url = url + '&pn='
for i in range(1,endPage+1):
print u'爬虫报告:爬虫%d号正在加载中...' % i
myPage = urllib2.urlopen(url + str(i),timeout=30).read()
# 将myPage中的html代码处理并存储到datas里面
self.deal_data(myPage.decode('utf-8'))
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('id="post_content.*?>(.*?)</div>',myPage,re.S)
for item in myItems:
data = self.myTool.Replace_Char(item.replace("\n","").encode('utf-8'))
self.datas.append(data+'\n')
##获取当前地址的内容
def get_current_content(url):
print u'已开始启动爬虫...'
print u'要爬的吧是:'+url
content = urllib2.urlopen(url,timeout=30).read().decode('utf8')
print u'网页信息已全部获取'
return content
##获取下一页的地址
def get_next_href(current_content):
#格式为<a href="/f/909090" class="next">
#匹配该模式,获取下一页的地址
next = re.compile(r'href="(\S*)"[^><]* class="next"')
next_page = re.findall(next,current_content)
#判断下一页是否存在
if (next_page is []):
print u'我擦嘞,累死老娘了,终于完了啊你~~~'
return False
else:
next_page_url='http://tieba.baidu.com'+str(next_page[0])
print u'怎么还有啊,累死姐了...'
return next_page_url
##获取当前页面的所有href及其内容
def get_current_href_content(content,title):
#格式为<a href="/p/2020020200" title = "" target ="_blank" class = "j_th_tit" >
#匹配该模式,获取href
match = re.compile(r'href="(\S*)"[^><]*target="_blank" class="j_th_tit"')
list= re.findall(match,content)
#把链接地址补全
for item in list:
item=item.replace(item,'http://tieba.baidu.com'+item)
print item
##对每一个href进行爬虫
mySpider = Baidu_Spider(item)
mySpider.baidu_tieba()
def find_title(content):
# 匹配 <h1 class="core_title_txt" title="">xxxxxxxxxx</h1> 找出标题
myMatch = re.search(r'<title>(.*?)</title>', content, re.S)
title = u'暂无标题'
if myMatch:
title = myMatch.group(1)
else:
print u'爬虫报告:无法加载文章标题!'
# 文件名不能包含以下字符: \ / : * ? " < > |
title = title.replace('\\','').replace('/','').replace(':','').replace('*','').replace('?','').replace('"','').replace('>','').replace('<','').replace('|','')
return title
#------------------------------程序入口--------------------------------#
#用户选择要爬的吧,输入这个吧的网址
print u"""
#--------------------------------------------------------------------
# 程序:百度贴吧爬虫
# 作者:memory
# 日期:2014-03-27
# 语言:Python 2.7
# 功能:输入百度贴吧中某个吧的网址之后将本吧的所有内容都提取下来保存为TXT文件
#------------------------------------------------------------------------------
"""
print u'请输入贴吧首页地址...'
myurl = [
'http://tieba.baidu.com/f?kw=nba',
'http://tieba.baidu.com/f?kw=%BB%F0%BC%FD',
'http://tieba.baidu.com/f?kw=%C2%F3%B5%CF'
]
#print u'请输入贴吧名字'
for item in myurl:
#获取贴吧首页地址
#获取下一页的地址、每一个页面所有链接的地址及其内容。并返回下一页的地址
#获取当前网站的所有页面代码
url = item
content=get_current_content(url)
#获取当前页面的所有href
title = find_title(content)
print title
while(url is not False):
try:
content=get_current_content(url)
#获取当前页面的所有href
href=get_current_href_content(content,title)
#获取当前页的下一页链接地址
url=get_next_href(content)
except:
print u'啊啊啊啊,我要死了。。。真的不行了~'
print url
break
豆瓣小组爬虫源代码
#! /usr/bin/env python
# -*- coding: utf-8 -*-
#
# Copyright © 2015 memoryfeng Huazhong University of Science and Technology
#
# Distributed under terms of the MIT license.
"""
"""
import sys
import argparse
import socket
import string
import re
import urllib2
import time
hds={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36','Server':'dae','Content-Type':'text/html;charset=utf-8','Connection':'close',\
'X-Douban-Mobileapp':'0','Expires':'Sun, 1 Jan 2006 01:00:00 GMT',\
'X-Douban-Newbid':'qNL7av2zyKI','Pragma':'no-cache','Cache-Control':'t-revalidate, no-cache, private',\
'P3P' : 'CP="IDC DSP COR ADM DEVi TAIi PSA PSD IVAi IVDi CONi HIS OUR IND CNT"',\
'X-Douban-Splittest':'Set-Cookied="qNL7av2zyKI"; path=/; domain=.douban.com; expires=Wed, 23-Nov-2016 01:48:13 GMT',\
'Set-Cookie':'th=/; domain=.douban.com; expires=Wed, 23-Nov-2016 01:48:13 GMT',\
'X-DAE-Node':'sindar10b'}
def get_url(url):
# Get all the urls in this page.
# Get content here
#print url
req = urllib2.Request(url,None,hds)
data = urllib2.urlopen(req).read()
#data = urllib2.urlopen(url, timeout=30).read()
#print data
# Match the urls.Style:<h3><a href="xxx"></a></h3>
urls = re.findall('<a href="http://www.douban.com/group/topic/(\d*)/">', data,re.S)
return urls
def writetxt(lst):
f = open('doubangroup.1124','a')
for item in lst:
f.writelines(item+'\n')
f.close()
def get_content(data):
title = re.findall('<span class="topic-figure-title">(\S*?)</span>', data,re.S)
comments = re.findall('<p class="">(\S*)</p>',data,re.S)
content = re.findall('<p>(\S*)</p>',data,re.S)
writetxt(title)
writetxt(comments)
writetxt(content)
time.sleep(12)
if __name__=="__main__":
print " Crawler for Douban Group comments.\n"
print " Mission Recieved.\n"
print " Spidering now...\n"
#header = {'User-Agent':'Mozilla/5.0'}
dburl = "http://www.douban.com/group/explore/ent?start="
for page in range(0, 268):
print page
url = dburl + str(page*30)
# get all the url in this page
current_urls = get_url(url)
# get all the content & the comments in this topic page
for url in current_urls:
req = urllib2.Request('http://www.douban.com/group/topic/'+url+'/',None,hds)
#data = urllib2.urlopen('http://www.douban.com/group/topic/'+url+'/',timeout=30).read()
data = urllib2.urlopen(req).read()
get_content(data)
# write the content into the text file
print " I have got all the contents.\n"
print " Say thank you to me~\n"
print " Try again!"















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









