






事件背景
11 月 27 日,滴滴出现多端 app/小程序服务异常,截至今天滴滴并未公布具体故障原因,网上说法众说纷纭,今天对这个问题展开讨论猜测一下可能的情况。

故障表现
滴滴多端不可用(包含用户端/司机端/青桔),显示网络异常,无故障期间 http/tcp 抓包,无法故障回放。网传滴滴内网同步异常,暂无求证门路。
故障猜想
- 网络攻击(网传)
- k8s 升级故障(网传)
以下均为猜测
- 中间件及 db,系统内核层面等程序爆发式 bug
- 白名单异常
- 中台重要环节故障导致调用链断裂
- 业务引擎 bug
故障猜想论证
网络攻击
网络攻击具有不确定性:不确定来源,不可预知流量,不确定攻击时间。本次故障看来从时间持续性较长,具有一定的被攻击的特征,但是在受到攻击后通常企业会做以下操作:
- 接入流量清洗,但是对于被攻击目标太大时使用流量清洗或者 WAF 也是无力的,会引入很大的接入成本和使用成本
- 直接切换入口,切换入口主要风险点在于是否有备用 ip 可以更换,链路是否冗余,域名 ttl 是否过长,但是故障收敛速度很快,不过这种方式基本只会存在于单业务故障的时候
从以上解决方案来看,故障时间都可以在较短的时间内完成故障收敛,本次故障持续了 12 小时明显站不住脚。并且攻击通常不会针对全业务进行,最多打爆某几个业务已经属于很大量的攻击了,再加上内网也同时异常,完全不符合攻击的特征。
k8s 集群升级引入
我们先看看 k8s 常见多 master 的架构:
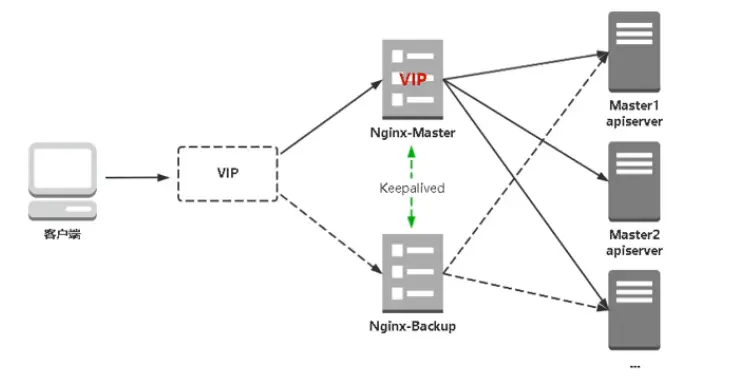
网传本次故障是更新 APIServer 导致 k8s 集群主节点崩溃,从而导致 pod 调度失败,但是反观这个观点有几点站不住脚:
- 既然是更新,那肯定是滚动更新,不可能直接全量,如果滚动更新单 master 挂了,完全可以切掉这个 master 节点,故障收敛时间不会超过一个小时,即使用单集群部署故障也会很快收敛。
- 这里我姑且认为他 master 挂了,而且无法恢复,那么,为什么影响面会这么广,莫非所有业务部署在同一集群?而且没有用多集群做 AZ 高可用或者 region 级别的高可用?
我们先认为他们使用了一个公共集群部署所有业务,如果 master 真的故障了,也是应该第一时间切掉故障,理论上来说切掉故障点后容器重生基本就可以恢复问题了。但是不可否认可能为以下问题导致雪崩:
- 集群实在塞的太满,rolling update 策略完全跑不起来,quota 已经被用尽,新生成不了容器
- 同时挂的容器比较多,且异常容器并未正常退出,和 db 等中间件仍保持连接,重生的容器直接把这些东西的连接限制打满导致恶行循环
但是显然这些可能是不会很容易就出现的,毕竟这是滴滴,主要业务后端组件承载量不会就那么小。
换个角度,所有业务用同一套多集群公共集群
这里就有必要引入华为开发的 karmada 来说事了。我们先看看多集群架构,先不说引入 istio 多集群流量治理这一步,从最简单的多集群来说:
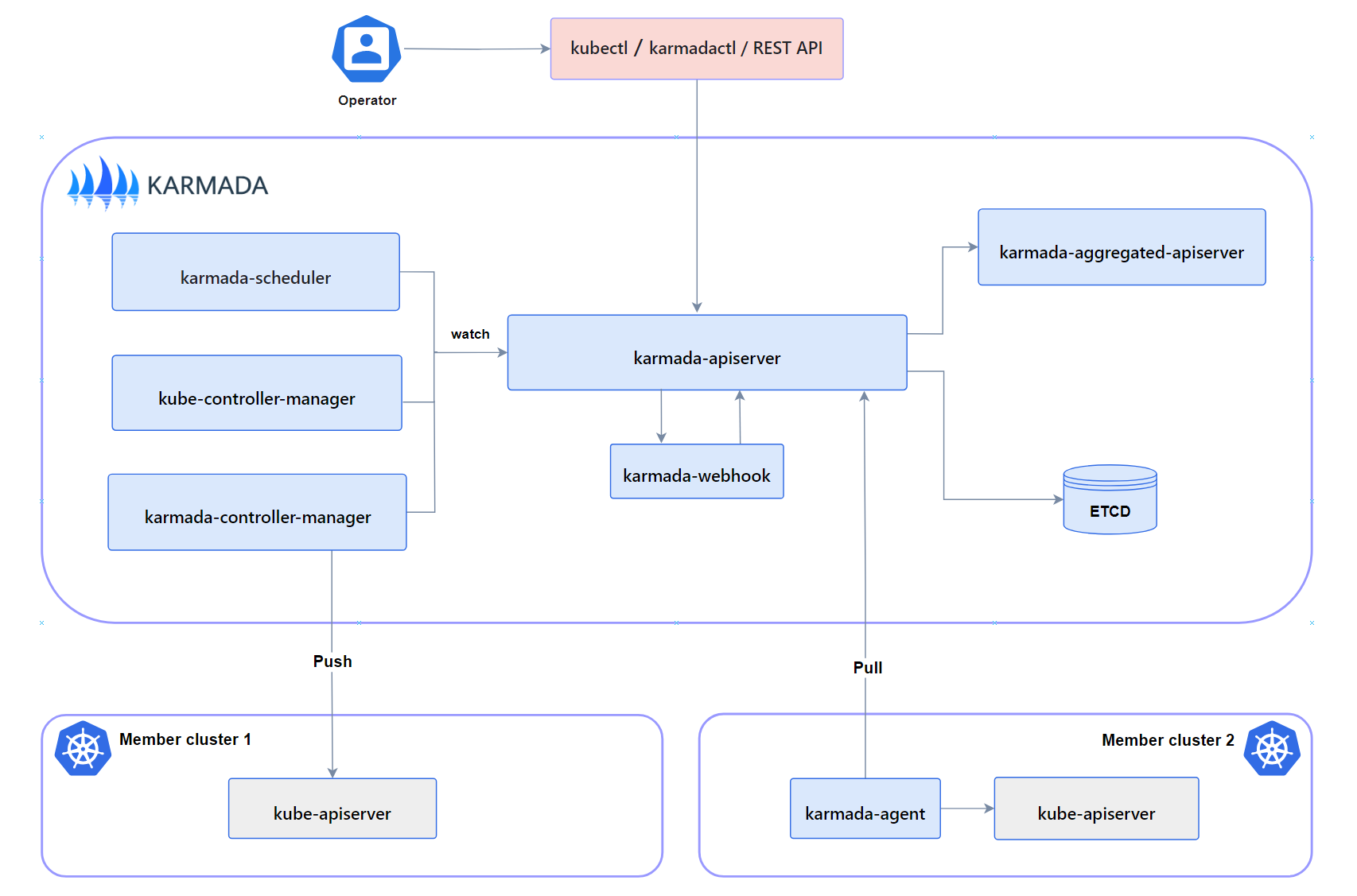
karmada 的优势在于可以通过一个入口管理到两个集群,业务可以直接通过 op/pp 定向发布到指定的集群,况且,karmada 有很强的容灾能力,甚至能做到单集群挂了之后把容器全量迁移到另一个集群上,收敛时间基本可以做到分钟级。哪怕不切域名,也至少会有部分人正常访问。
我姑且认为他们没有用这一套方案做,那么当一个集群炸了之后,第一时间应该是尽快服务降级,并切除故障集群,入口导流到另一个集群上,从收敛时间来看,也不太像。
需要注意,现在企业为了容灾都是用的多套集群分别部署多套业务,况且这是核心业务,一般都会有 AZ 高可用,但凡用了集群拆分部署不同业务也不会出现这么严重的故障。况且这么复杂的业务网关入口大概率也用了 istio 类的流量治理工具,在多集群场景下流量治理也能完成一定范围内的容灾。所以 k8s 升级故障说法不攻自破。
中间件及 db,系统内核层面等程序爆发式 bug
这个问题是很罕见的,我有幸遇到过一次。当时没有任何征兆,一千多台华为鲲鹏 cpu 机器集体趴窝,排查结果是驱动异常导致网卡和内核通信异常,直接让网卡不停的 up/down。这一情况也可能推广到 db 或者其他中间件上。但是需要注意这种情况有以下一些因素可能推翻这一可能:
- 不同业务用的中间件/db 版本,种类是不相同的,所以同一时间集体趴窝可能性不大
- 系统内核层面爆发式 bug,这种情况和内核版本/系统版本/机器机型有关,也不太可能同时趴窝
所以除非蠢到所有中间件/db/os 版本完全一样,机型也一样,才可能有这么重大的故障。
白名单异常
这个问题我认为可能性比较大,可以参考 11 月 12 日阿里云故障的表现,当时阿里云基本全系列产品都不可用。
通常在大型企业的防火墙是有一个专门的平台管理的,且作为基础组件/运维中台来用的,如果白名单出现 bug 或者直接挂了,生成残缺或者空白的白名单,完全有可能直接导致全部接入业务 403(七层接入)或者拒绝连接(四层接入)。并且综合内网也挂了这一表现来看,如果内网也用到了这个白名单服务的话,确实也会导致内网崩溃,所以这一可能是比较有理论依据的。
我以前恰巧也遇到过这一问题,当时防火墙系统生成了空白名单,直接导致所有接入业务(包括 CMDB,监控,日志,甚至内网认证)都出现异常,外部用户的感知是只要涉及接入的服务都会被影响到。
中台重要环节故障导致调用链断裂/基础依赖问题
这也是一种比较大的可能。比如设想一个场景:用户通过 auth 登录后,进行的每一次业务操作(比如打车发出订单,或者扫码单车,非查看类的)基本都要从鉴权那边获取用户是否可以操作,或者从计费那边检查,用户是否有未支付订单等等操作。如果这些业务出现任何一个故障,都可能直接导致用户的操作异常。从本次故障来看,用户的感知基本符合这一问题,但是同样不能解释内网挂了的原因。因为通常企业不会把内网 auth 和外网 auth 用同一套,况且法规要求数据保护,办公区网络和服务基本不可能和线上服务部署到一起且相互影响。
从恢复时间上看也可能是服务依赖问题,比如 A 服务启动需要 B 服务,B 服务启动需要 C 服务,C 服务启动需要 A 服务,这样的环形依赖,但凡任何一个服务挂了,都可能导致三个服务循环挂,而且极难恢复。根据和滴滴司机面谈,司机反馈说早上时候服务有一段时间可用,之后又不可用了,若为这个原因的话,可能在早上做了服务降级,把某一环依赖去掉了,暂时拉起服务,后又恢复业务,依赖产生之后又重新挂掉,之后直接开始 hotfix,直到问题被解决,这条路可以解释通。
也有一种可能,是直接基础依赖出现问题了,比如 dns。如果公司用自建 anycast 且办公网和业务网不隔离的情况下,确实可能出现所有业务故障。
业务引擎 bug
这个问题可能有些人比较难想到,但是像这种巨型业务,一定是对各部分进行过拆分,这个引擎可以理解为业务的最核心逻辑,为多端进行服务,业务引擎炸了,自然从引擎派生出来的多端服务也就跟着炸了,且是一起炸,极可能也是一起恢复。但是仍然解释不通内网异常这个问题。
总结
从以上分析不难看出,判别具体故障原因的必要条件就是需要明确知道滴滴的内网到底有没有挂,如果内网也挂了,基本可以断定是因为基础设施或者白名单问题导致故障,如果内网没挂,可能的原因可能很多,上面只是对我认为可能的原因进行了猜测和举证,可能还有很多原因是我没有想到的吧。但愿滴滴的运维同行今年还能拿到年终奖。

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









