







一直想对Hadoop有一个比较全面的了解,这次正好趁做作业的机会,对第一代和第二代Hadoop架构进行了整理和分析。文中第二代Hadoop的内容主要来自第一篇参考文献——发表在SoCC2013上的一篇文章。(文中的图片都来自于文后所列出的参考文献。)
1 前言
Hadoop是一个开源的分布式系统框架,由Apache基金会开发,是当前最热门的大数据技术。它一开始主要应用在一些大型网站,如Yahoo!、Facebook、淘宝、百度等。随着人们对大数据的价值越来越重视,Hadoop开始在各类企业中得到广泛应用,成为人们对大数据进行存储、分析和挖掘的最主要的工具。Hadoop的应用已经形成了一个强大稳定的生态系统。
Hadoop的出现受到Google两篇论文(The Google File System和MapReduce: SimplifiedData Processing on Large Clusters)的启发。其设计初衷是解决搜索引擎中的可扩展性问题。Hadoop最大的特点是可以将数千台普通的廉价商用服务器组成一个稳定可靠、计算能力强大的集群,能够对PB量级的数据进行存储和计算。
Hadoop可以使用户可以在不了解底层细节的情况下,开发分布式的应用程序,实现高效可靠的分布式计算。Hadoop基于java开发,用户可以用java, C/C++开发自己的应用。
Hadoop技术以其低廉的成本和强大的计算能力得到人们的广泛认可。人们对Hadoop技术的使用已经远远超出了Hadoop最初的设计目标,同时也暴露出越来越多的问题。人们对Hadoop的可扩展性、可靠性、可用性都提出了更高的要求。2013年末,第二代Hadoop系统YARN发布。新的架构在原来的基础上作了很多改进,性能和可扩展性更高,而且可以支持更多的计算模型。
本文第二部分介绍第一代Hadoop技术的架构,并分析其优缺点;第三部分介绍第二代Hadoop技术YARN的架构;第四部分简单介绍跟Hadoop类似的计算框架;第五部分对本文进行总结。
2 第一代Hadoop系统
第一代Hadoop从资源管理到任务调度都采用了主从结构。如图1所示,Hadoop有两个核心组件:HDFS和MapReduce编程框架。下面分别对这两个组件进行介绍。
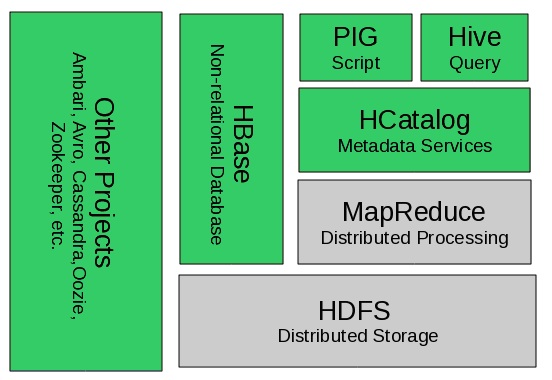
图 1 第一代Hadoop 生态系统
2.1 HDFS
HDFS是Hadoop Distributed File System的简称。它是一个高度容错的分布式文件系统,可以部署在廉价集群上,实现高吞吐量的数据访问。在HDFS中,大的数据集被分成很多小块,每一块有多个备份并保存在不同的节点上,从而实现大规模数据的分布式可靠存储。另外,在计算时,数据并不需要大量移动,而是由调度器将执行程序加载到存储数据的节点上,通过数据的本地化降低数据访问开销,节省网络带宽。这保证了在处理数据密集型任务时的高效性。
如图 2所示,HDFS采用主从结构(master-slave),由NameNode、Seco
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1820
1820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









