







后缀树组是一个字符串的所有后缀的排序数组。后缀是指从某个位置 i 开始到整个串末尾结束的一个子串。字符串 r 的从 第 i 个字符开始的后缀表示为 Suffix(i) ,也就是Suffix(i)=r[i..len(r)] 。如下图所示:
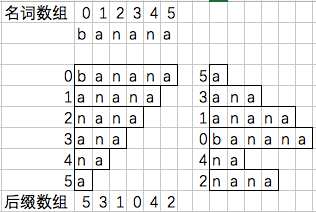
对于字符串banana,所有的后缀字符串是banana,anana,nana,ana,na,a。我们对其进行排序得到右边的排序序列,其相应的索引值这时候就构成了后缀数组[5, 3, 1, 0, 4, 2]。同时我们定义一个名词数组Rank。
其中,后缀数组SA是一个一维数组,他保存1…n的某个排列SA[1], SA[2], … , SA[n],并且S的n个后缀从小到大进行排序之后,把排好序的后缀的开头位置放入SA中。名词数组Rank[i]保存的是Suffix(i)在所有后缀中从小到大排列的名次。名词数组Rank[i]和后缀数组SA胡逆。一种通俗的解释是:
后缀数组是“排在第几的是谁”,名次数组是“你排第几”。
具体到banana这个例子的后缀数组[5, 3, 1, 0, 4, 2],我们可以知道,排在第0位的后缀是从banana第5位开始的后缀a,排在第1位的后缀是从banana第3位开始的后缀ana,排在第2位的后缀是从banana第1位开始的后缀anana,以此类推。
在C中后缀数组是通过指针实现的。我们尝试在Python中实现后缀数组。
最简单的方式是使用numpy包中自带的argsort()函数,直接返回按照字典序排序后原始数组的索引值
from numpy import argsort
def suffixArray(s):
if s == None or len(s) == 0:
return None
allSuffix = []
for i in range(len(s)):
allSuffix.append(s[i:])
SA = argsort(allSuffix)
return SA
print(suffixArray("banana"))输出即为[5 3 1 0 4 2]。接着尝试自己编写代码实现argsort()功能。
def suffixArray(s):
if s == None or len(s) == 0:
return None
allSuffix = []
for i in range(len(s)):
allSuffix.append([s[i:], i])
sortedList = sorted(allSuffix)
SA = [w[1] for w in sortedList]
return SA
print(suffixArray("banana"))我们首先生成所有后缀数组,同时每个数组匹配的Index也一并写入一个新的数组,这样的空间复杂度就是O(n2),之后我们利用系统自带的排序方法,一般时间效率为O(nlogn)。
下面我们利用后缀数组解决最长公共子串问题。
首先我们在求字符串A和B的最长公共子串的时候,可以将A和B连接到一起, 如果某一个子串s是他们的公共字串,那么s一定会在连接后字符串后缀数组中出现两次,但是我们要注意的是,有可能会出现某个字符串出现两次,但它只是A或者B内部的某个重复子串,因此我们在连接A和B的时候,在中间加入一个特殊字符“#”,即连接之后的字符串变为A#B。这时候我们可以得到A#B的后缀数组,后缀数组中的每个位置对应的后缀字符串一定是排好序的,所以最长的公共字串出现的位置一定是后缀数组中相邻元素对应的后缀字符串的位置。同时得到 # 的位置,其中A和B的后缀子串开始的位置和 # 的差值一定是一个大于0,一个小于0,即乘积小于0。
整体步骤如下:
1. 首先将A、#、B连接形成新的字符串S。
2. 求得S的后缀数组以及#的位置indexOfSharp。
3. 遍历后缀数组SA,求取后缀数组中第i个位置对应的后缀字符串和第i+1个位置对应的后缀字符串,同时应该满足(SA[i] - indexOfSharp) * (SA[i + 1] - indexOfSharp) 小于0,也就是这两个后缀数组分别位于 # 的两侧。
4. 然后比较新求得的两个后缀子串的最长前缀和之前存储的最长前缀maxLen的大小,如果大于maxLen,则更新maxLen,以及maxIndex。最后返回相应的共同字符串的长度以及字符串。
具体Python代码如下:
# 利用后缀数组解决最长公共子串问题
def longestCommonSubstring2(self, A, B):
if A == None or B == None:
return
s = A + "#" + B
indexOfSharp = len(A)
SA = self.suffixArray(s)
maxLen, maxIndex = 0, 0
hasCommon = False
for i in range(len(s) - 1):
# 判断后缀数组中两个相邻元素对应的后缀字符串是否位于“#”两侧,即是否属于A和B两个不同字符串
diff = (SA[i] - indexOfSharp) * (SA[i + 1] - indexOfSharp)
if diff < 0:
tempLen = self.comlen(s, SA[i], SA[i + 1])
if tempLen > maxLen:
maxLen = tempLen
maxIndex = SA[i]
hasCommon = True
return (maxLen, s[maxIndex:maxIndex + maxLen]) if hasCommon else False
# 得到一个字符串的后缀数组
def suffixArray(self, s):
if s == None or len(s) == 0:
return None
allSuffix = []
for i in range(len(s)):
allSuffix.append([s[i:], i])
sortedList = sorted(allSuffix)
SA = [w[1] for w in sortedList]
return SA
# 比较得到后缀数组中两个相邻的元素分别对应的后缀字符串的最长前缀
def comlen(self, s, p, q):
j = 0
while j < len(s[p:]) and j < len(s[q:]) and s[p:p + j + 1] == s[q:q + j + 1]:
j += 1
return j














 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









