







1. 背景
在工作中,不管是写app代码,还是阅读framework中的源码,涉及到解析xml的代码片段非常多,本篇文章从两个点来讲解一下,第一个点:xml文件结构 第二个点:怎么用XmlPullParser去解析。掌握这些知识后,对在阅读分析PMS解析包安装管理xml文件的源码,就会比较清晰明了。
2. XML文件结构
2.1 XML 定义
XML: Extentsible Markup Language(可扩展标记语言)的缩写,它的格式与HTML文件的格式类似,xml是使用自定义标记来定义对象和每个对象中的数据,xml文件可以被认为是基于文本的数据库。
2.2 XML文件结构和基本语法
一个XML文档由两部分构成:第一部分是文档声明,第二部分是文档元素(节点)
文档声明通常位于XML文档的顶端,根元素之前出现,它是一个特定的包含XML 文档设定信息的部分
XML 文档由如下几个部分组成:
- XML 声明:用来设置XML文档解析时所需的基本参数。
- 处理指令:为某个特定类型的软件反馈一条特殊的指令。
- 文档类型定义:用来设置更多高级的信息,如实体、属性及有效性相关的信息。
- 注释:用于提醒XML文档作者或临时标注出文档中不完善的部分。
接下来介绍几个重要的概念:
xml文档声明
XML 文档声明是为XML 解析器进行文档处理时提供相关信息的一个很小的配置信息集合。每一个XML 文档应当包含一个XML 声明,并且XML 声明必须放在文档的第一行。如下:
<?xml version="1.0" encoding="utf-8" standalone="no"?> XML 声明中包括三个属性,每个属性设置的具体形式为:属性名称="属性值"。其中属性值需要是使用双引号或者单引号括起来,多个属性之间使用空格进行分隔。XML 声明中的三个属性的名称分别是:version、encoding和standalone。
version: 此属性用来声明XML 文档所遵循的XML 标准版本。现在通常情况下该属性的值都是1.0,尽管 XML 1.1 已经称为 W3C 的推荐标准,但是大部分的 XML 解析器还是采用 XML 1.0 标准。version 是 XML 声明中必须包含的一个属性。
encoding: encoding 属性用来告诉 XML 解析程序当前 XML 文档使用什么样的字符编码。该属性是可选的。当 XML 声明中没有明确给出字符编码方式时,XML 解析程序将默认为 XML 文档采用的是 UTF-8 字符编码。
standalone : standalone 属性定义了是否可以在不读取任何其他文件的情况下处理该文档。例如,XML 文档没有引用任何其他文件,则可以指定属性值为 yes。如果 XML 文档引用其他描述该文档可以包含的文件,则可以指定属性值为 no。因为 no 是 standalone 属性默认的属性值,所以较少会在 XML 声明中看到 standalone 属性。
注意点:如果同时设置了 encoding 和 standalone 属性,standalone 属性必须位于 encoding 属性之后。
元素
XML元素指XML文件中出现的标签,一个标签分为起始和结束标签(不能省略),一个标签有如下几种书写形式
---- 包含标签主体: <tagName> some content</tagName>
----不含标签主体: <mytag><mytag>
一个标签中可以嵌套若干个子标签,但所有标签必须合理的嵌套,不允许有交叉嵌套
---- <tag1><tag2></tag1></tag2> 错误
一个XML文档必须有且仅有一个根标签。其他标签都是这个根标签的子标签或孙标签
属性:
一个元素可以有多个属性,每个属性都有它自己的名称和取值,例如:<tag name="张三"/>
属性值一定要用引号“单引号或双引号”引用起来
元素中的属性是不允许重复的
在XML技术中,标签属性所代表的信息也可以用子元素的形式来描述。
语法格式如下:
<tagName attribute1="value1" attribute2="value2"......>tagData</tagName>注释:
XML 注释的语法格式: <!--这里是注释-->
注意点:XML声明前不能有注释,也就是第一行之前不能有注释,否则报错
注释不能嵌套
2.3 XML实例
demo.xml代码如下:
<?xml version="1.0" encoding="utf-8"?> <!--xml文档声明-->
<resources> <!--根元素-->
这里是资源文本
<!--元素第一种标准写法-->
<color value="#FF0000" name="红色"></color>
<!--元素第二种写法-->
<color value="#00FF00" name="绿色"/>
</resources>
代码解读:
第一行为文档声明
<resources> 为根元素
<color> 为子元素,其内部有2个属性 value 和 name
第二个xml例子: 标签属性所代表的信息也可以用子元素的形式来描述,比如name 和age 就是用子元素形式表示的,但是不提倡这么写,这样子在解析的时候,代码就会比较难写。推荐上面的那种写法。
<?xml version="1.0" encoding="UTF-8"?>
<students>
<person id="1111">
<name>李四</name> <!--标签属性所代表的信息也可以用子元素的形式来描述-->
<age>30</age>
</person>
<person id="2222" name="张三" age="20"></person >
<person id="3333" name="王五" age="10"/>
</students>
第一行 <?xml version="1.0" encoding="UTF-8"?> 就是XML声明,当前面版本号为1, 使用的是UTF-8编码
students 为根元素: 文件体的最顶层元素称为根元素,根元素只能有一对,其名字可以自定义。所有其他元素均以子元素的形式存在于根元素内。子元素是可以重复出现的。
子元素: person
上面的xml中 子元素 person,定义了三个属性值 id name age 上面的三种写法都是等价的
好了,理解上面xml各标签的定义后,接下来开始解析内容。
3. XmlPullPaser 解析
先看看第一个Demo:
import java.io.IOException;
import java.io.StringReader;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import org.xmlpull.v1.XmlPullParserFactory;
public class SimpleXmlPullApp
{
public static void main (String args[])
throws XmlPullParserException, IOException
{
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
XmlPullParser xpp = factory.newPullParser();
xpp.setInput( new StringReader ( "<foo>Hello World!</foo>" ) );
int eventType = xpp.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
if(eventType == XmlPullParser.START_DOCUMENT) {
System.out.println("Start document");
} else if(eventType == XmlPullParser.START_TAG) {
System.out.println("Start tag "+xpp.getName());
} else if(eventType == XmlPullParser.END_TAG) {
System.out.println("End tag "+xpp.getName());
} else if(eventType == XmlPullParser.TEXT) {
System.out.println("Text "+xpp.getText());
}
eventType = xpp.next();
}
System.out.println("End document");
}
}
终端输出如下:
Start document
Start tag foo
Text Hello World!
End tag foo
End document代码解读:
eventType 有五种解析类型:
| int值 | 事件名 | 事件定义 |
| 0 | START_DOCUMENT | 开始读取文档 |
| 1 | END_DOCUMENT | 结束文档 |
| 2 | START_TAG | 读取标签 |
| 3 | END_TAG | 结束标签 |
| 4 | TEXT | 标签中的数据内容 |
然后根据获取标签数值,做对应的逻辑处理,xmlpullparser是一行一行的从上到下解析文件的。
XmlPullParser相关的API
| 方法 | 说明 |
getEventType() | 获取当前解析的事件类型,有5种:START_DOCUMENT END_DOCUMENT START_TAG END_TAG TEXT |
getName() | 获取元素的标签名 在 START_TAG事件中使用 |
| getText() | 获取文本内容, 在TEXT 事件中使用 |
getAttributeValue(String namespace,
String name); | 类似于通过key值来获取value值, 第一个参数为default值, 第二个参数为 key 返回:一个字符串 |
如果上个例子不是很明白,我们接下来继续这个Demo:
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
try {
//解析本地assets下的 xml资源文件
parserAssetXml();
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
private void parserAssetXml()throws XmlPullParserException, IOException {
//获取XmlPullParserFactory实例
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
//通过XmlPullParserFactory 来获取 xmlPullParser对象
XmlPullParser pullParser = factory.newPullParser();
//通过此API来获取输入流,作为pullParser的参数
InputStream inputStream = getAssets().open("demo.xml");
//pullParser.setInput(输入流,"编码类型");
pullParser.setInput(inputStream, "UTF-8");
//获取解析的类型, eventType有五种类型:START_DOCUMENT END_DOCUMENT START_TAG END_TAG TEXT
int eventType = pullParser.getEventType();
Log.e("test", "=====第一次打印的eventType值为 :" + eventType);
// 开始解析
while (eventType != XmlPullParser.END_DOCUMENT) {
eventType = pullParser.getEventType();
Log.e("test", "=====解析过程中eventType值为 :" + eventType);
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
Log.e("test", "=====这里是文档声明====<?xml version=\"1.0\" encoding=\"UTF-8\"?>====");
break;
case XmlPullParser.START_TAG:
String tagName = pullParser.getName();
Log.e("test", "=====解析过程中tagName值为 :" + tagName);
//如果 子元素的tagName为 color,就开始打印其内容
if (tagName != null && tagName.equals("color")) {
String colorValue = pullParser.getAttributeValue("", "value");
Log.e("test", "=====解析过程中colorValue值为 :" + colorValue);
String colorName = pullParser.getAttributeValue("", "name");
Log.e("test", "=====解析过程中colorName值为 :" + colorName);
}
break;
case XmlPullParser.END_TAG:
Log.e("test", "====这里是元素的结束标签==="+pullParser.getName());
break;
case XmlPullParser.TEXT:
Log.e("test", "====解析文本内容==="+pullParser.getText());
break;
default:
break;
}
//继续解析下一个子元素
eventType = pullParser.next();
}
}
}注意Android studio工程中的assets的资源路径,不要放错位置了,否则会提示资源找不到
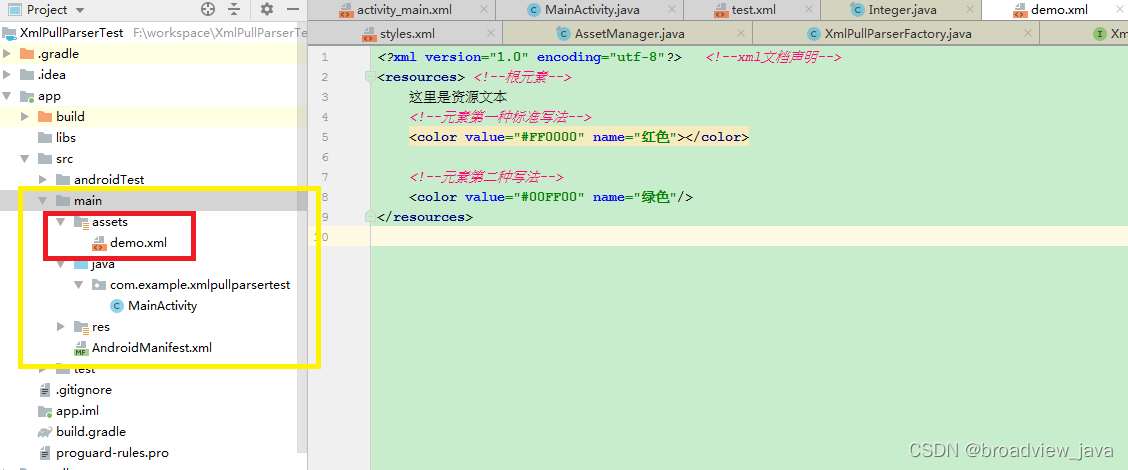
打印log内容如下:
17:30:33.903 29787 29787 E test : =====第一次打印的eventType值为 :0
17:30:33.903 29787 29787 E test : =====解析过程中eventType值为 :0
17:30:33.903 29787 29787 E test : =====这里是文档声明====<?xml version="1.0" encoding="UTF-8"?>====
17:30:33.903 29787 29787 E test : =====解析过程中eventType值为 :2
17:30:33.903 29787 29787 E test : =====解析过程中tagName值为 :resources
17:30:33.903 29787 29787 E test : =====解析过程中eventType值为 :4
17:30:33.903 29787 29787 E test : ====解析文本内容===
17:30:33.903 29787 29787 E test : 这里是资源文本
17:30:33.903 29787 29787 E test :
17:30:33.903 29787 29787 E test :
17:30:33.904 29787 29787 E test : =====解析过程中eventType值为 :2
17:30:33.904 29787 29787 E test : =====解析过程中tagName值为 :color
17:30:33.904 29787 29787 E test : =====解析过程中colorValue值为 :#FF0000
17:30:33.904 29787 29787 E test : =====解析过程中colorName值为 :红色
17:30:33.904 29787 29787 E test : =====解析过程中eventType值为 :3
17:30:33.904 29787 29787 E test : ====这里是元素的结束标签===color
17:30:33.904 29787 29787 E test : =====解析过程中eventType值为 :4
17:30:33.904 29787 29787 E test : ====解析文本内容===
17:30:33.904 29787 29787 E test :
17:30:33.904 29787 29787 E test :
17:30:33.904 29787 29787 E test :
17:30:33.904 29787 29787 E test : =====解析过程中eventType值为 :2
17:30:33.904 29787 29787 E test : =====解析过程中tagName值为 :color
17:30:33.904 29787 29787 E test : =====解析过程中colorValue值为 :#00FF00
17:30:33.904 29787 29787 E test : =====解析过程中colorName值为 :绿色
17:30:33.904 29787 29787 E test : =====解析过程中eventType值为 :3
17:30:33.904 29787 29787 E test : ====这里是元素的结束标签===color
17:30:33.904 29787 29787 E test : =====解析过程中eventType值为 :4
17:30:33.904 29787 29787 E test : ====解析文本内容===
17:30:33.904 29787 29787 E test : =====解析过程中eventType值为 :3
17:30:33.904 29787 29787 E test : ====这里是元素的结束标签===resources把代码结合log一起看:
其中 0 表示 START_DOCUMENT ,开始解析文档
每次解析一个元素的标签时,事件类型为2 START_TAG,
接下来都会走 打印 4 TEXT , 你从log中看出,只有第一次解析根元素resources标签时打印了“
这里是资源文本 接下来解析子元素color时,打印都是为空 这是为什么?
接下来打印 3 END_TAG 事件 这个元素就解析完毕
接下来就 调用 next()方法,继续解析下一个元素,重复打印 2 3 4事件。
好了,我们回答上面提出的问题?解释如下:
就是不管你有没有在 元素的标签后面添加文本内容,代码解析的时候都会走4 TEXT事件。
而且test.xml 文件你用浏览器查看的时候也是ok的,说明格式是正确的,如下:

好了,到这里,我们就把解析流程梳理完成了。 把这些理解清楚后,我们可以看看PMS中解析AndroidManifest.xml的代码片段,后续会在framework中的文章中会介绍,这里先提前说明一下
4. PMS源码片段
在PackageParser.java中,有解析AndroidManifest.xml的片段代码,如下:
private boolean parseSplitApplication(Package owner, Resources res, XmlResourceParser parser,
int flags, int splitIndex, String[] outError)
throws XmlPullParserException, IOException {
TypedArray sa = res.obtainAttributes(parser,
com.android.internal.R.styleable.AndroidManifestApplication);
if (sa.getBoolean(
com.android.internal.R.styleable.AndroidManifestApplication_hasCode, true)) {
owner.splitFlags[splitIndex] |= ApplicationInfo.FLAG_HAS_CODE;
}
final String classLoaderName = sa.getString(
com.android.internal.R.styleable.AndroidManifestApplication_classLoader);
if (classLoaderName == null || ClassLoaderFactory.isValidClassLoaderName(classLoaderName)) {
owner.applicationInfo.splitClassLoaderNames[splitIndex] = classLoaderName;
} else {
outError[0] = "Invalid class loader name: " + classLoaderName;
mParseError = PackageManager.INSTALL_PARSE_FAILED_MANIFEST_MALFORMED;
return false;
}
final int innerDepth = parser.getDepth();
int type;
while ((type = parser.next()) != XmlPullParser.END_DOCUMENT
&& (type != XmlPullParser.END_TAG || parser.getDepth() > innerDepth)) {
if (type == XmlPullParser.END_TAG || type == XmlPullParser.TEXT) {
continue;
}
ComponentInfo parsedComponent = null;
// IMPORTANT: These must only be cached for a single <application> to avoid components
// getting added to the wrong package.
final CachedComponentArgs cachedArgs = new CachedComponentArgs();
String tagName = parser.getName();
//解析清单文件中的activity信息
if (tagName.equals("activity")) {
Activity a = parseActivity(owner, res, parser, flags, outError, cachedArgs, false,
owner.baseHardwareAccelerated);
if (a == null) {
mParseError = PackageManager.INSTALL_PARSE_FAILED_MANIFEST_MALFORMED;
return false;
}
owner.activities.add(a);
parsedComponent = a.info;
//解析清单文件中的广播信息
} else if (tagName.equals("receiver")) {
Activity a = parseActivity(owner, res, parser, flags, outError, cachedArgs,
true, false);
if (a == null) {
mParseError = PackageManager.INSTALL_PARSE_FAILED_MANIFEST_MALFORMED;
return false;
}
owner.receivers.add(a);
parsedComponent = a.info;
//解析清单文件中的服务信息
} else if (tagName.equals("service")) {
Service s = parseService(owner, res, parser, flags, outError, cachedArgs);
if (s == null) {
mParseError = PackageManager.INSTALL_PARSE_FAILED_MANIFEST_MALFORMED;
return false;
}
owner.services.add(s);
parsedComponent = s.info;
} else if (tagName.equals("provider")) {
Provider p = parseProvider(owner, res, parser, flags, outError, cachedArgs);
if (p == null) {
mParseError = PackageManager.INSTALL_PARSE_FAILED_MANIFEST_MALFORMED;
return false;
}
owner.providers.add(p);
parsedComponent = p.info;
} 













 1030
1030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









