






2008 年巴黎一个寒冷的夜晚,特拉维斯·卡兰尼克 和加勒特·坎普打不到出租车。就在那时,Uber 的想法诞生了。如果你可以“按一下按钮就可以搭车”,那该多好啊?
快进到今天,优步已成为世界上最大的移动平台。它在 70 多个国家和 10,500 个城市开展业务。Uber Eats 优食是全球除中国以外最大的外卖平台。它在 45 个国家/地区开展业务。我们将数百万司机合作伙伴和商家与超过 1.3 亿客户联系起来。我们提供数十种服务,让您可以去任何地方或获取任何东西。我们跨数十个应用程序和数千个后端服务处理数十亿个数据库事务和数百万个并发用户。
那么,我们是如何到达那里的呢?
早在 2009 年,Uber 就聘请了承包商来构建 Uber 的第一个版本,并很快将其推出给旧金山的朋友们。该团队使用经典的LAMP 堆栈构建了 Uber 的第一个版本,代码是用西班牙语编写的。
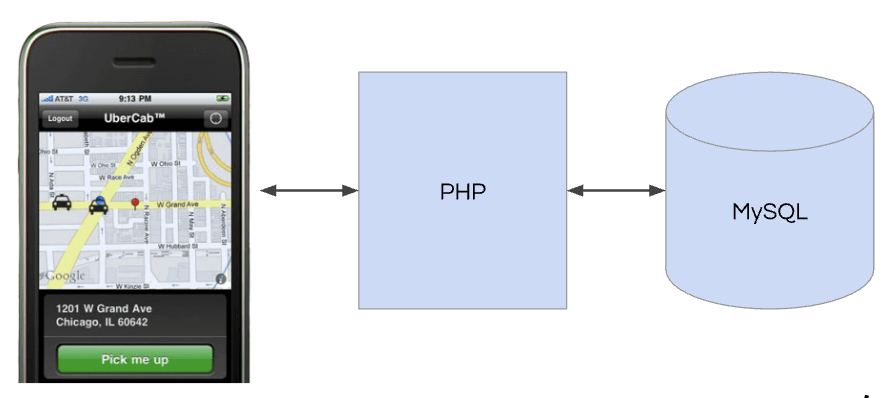
随着越来越多的人想要使用 Uber,扩展挑战就开始了。通常会出现严重的并发问题,我们会向一个人派遣两辆车,或者将一名司机与两名不同的乘客相匹配。
但该产品很受欢迎。是时候从头开始构建技术基础了。
为全球规模做好准备
2011年左右
为了构建更好、更具可扩展性的解决方案,我们需要解决这些并发问题。此外,我们需要一个可以处理大量实时数据的系统。不仅有乘客的请求,Uber 还需要跟踪司机的实时位置,以便尽可能高效地匹配乘客。最后,该产品还处于早期阶段,需要大量的测试和迭代。我们需要一个解决方案来解决所有这些场景。
Uber 采用Node.js来满足其实时需求。最终成为生产环境中Node.js 的首批主要采用者之一。Node.js 之所以成为理想选择有几个原因。首先,Node.js 异步处理请求(使用非阻塞、单线程事件循环),因此可以快速处理大量数据。其次,Node.js 运行在V8 JavaScript 引擎上,因此不仅性能优异,而且非常适合快速迭代。
随后,Uber 创建了第二个用 Python 构建的服务,用于处理身份验证、促销和票价计算等业务逻辑功能。
最终的架构是两个服务。一个内置于 Node.js,连接到 MongoDB,另一个内置于 Python(“API”),连接到 PostgreSQL。
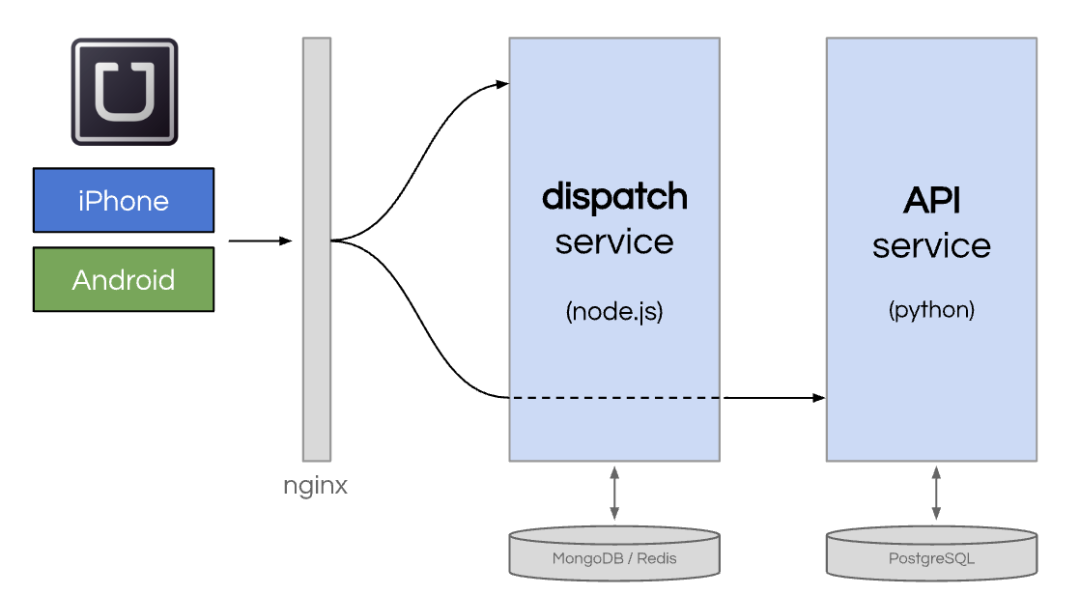
为了提高 Uber 核心调度流程的弹性,在调度和 API 之间构建了一个称为“ON”或对象节点的层,以承受 API 服务内的任何中断。(在这段视频《为失败而设计:通过打破一切来扩展 Uber 》中了解有关 Uber 为维护服务可靠性所做的最早努力的更多信息)。
这种架构开始类似于面向服务的架构。面向服务的架构可以非常强大。当您开发服务来处理更多专用功能时,它的一个附带好处是可以更轻松地将工程师分成专用团队。这样就可以更快速地扩展团队规模。
但随着团队和功能数量的增长,API 服务也变得越来越大。越来越多的功能相互冲突。工程生产力正在放缓。持续部署代码库存在巨大风险。
是时候将API拆分为适当的服务了。
从整体架构到微服务
2013年左右
为了为下一阶段的增长做好准备,Uber 决定采用微服务架构。这种设计模式强制开发专用于特定的、封装良好的领域(例如乘客计费、司机付款、欺诈检测、分析、城市管理)的小型服务。每个服务都可以用自己的语言或框架编写,并且可以有自己的数据库或没有数据库。然而,许多后端服务使用 Python,并且许多后端服务开始采用Tornado来提供异步响应功能。到 2014 年,我们拥有大约 100 项服务。
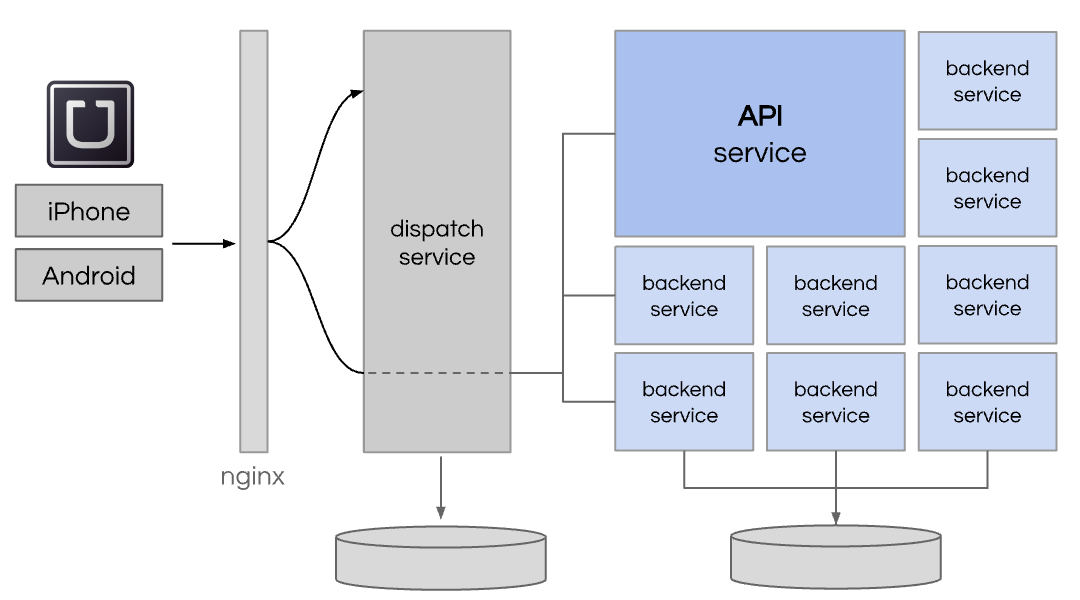
虽然微服务可以解决许多问题,但它也带来了显着的操作复杂性。您必须仅在了解权衡后才采用微服务,并可能构建或利用工具来抵消这些权衡。如果不考虑运营问题,您将简单地创建一个分布式单体。
以下是微服务造成的问题以及 Uber 采取的解决措施的一些示例。
为了保证所有服务都使用标准化的服务框架,我们开发了Clay。这是Flask上的 Python 包装器,用于构建宁静的后端服务。它为我们提供了一致的监控、日志记录、HTTP 请求、一致的部署等。
为了发现其他服务并与之对话并提供服务弹性(容错、速率限制、熔断),Uber在Hyperbahn上构建了TChannel。TChannel 作为我们内部构建的双向 RPC 协议,主要是为了为我们的 Node 和 Python 服务获得更好的性能和转发,以及其他好处。
为了确保定义良好的 RPC 接口和跨服务的更强大的契约,Uber 使用了Apache Thrift。
为了防止跨服务功能问题,我们使用Flipr来进行标记代码更改、控制部署和许多其他基于配置的用例。
为了提高所有服务指标的可观测性,我们构建了M3。M3 允许任何工程师轻松地离线或通过 Grafana 仪表板观察其服务状态。我们还利用Nagios进行大规模警报。
为了跨服务进行分布式追踪,Uber 开发了Merckx。这通过 Kafka 从仪器流中提取数据。但随着每个服务开始引入异步模式,我们需要改进我们的解决方案。我们受到 Zipkin 的启发,最终开发了Jaeger,至今我们仍在使用。
随着时间的推移,我们已经迁移到更新的解决方案,例如gRPC和 Protobuf接口。我们的许多服务都使用 Golang 和 Java。
扩展数据库
2014年左右
虽然 Uber 创建了许多新的后端服务,但我们继续使用单一的 PostgreSQL 数据库。
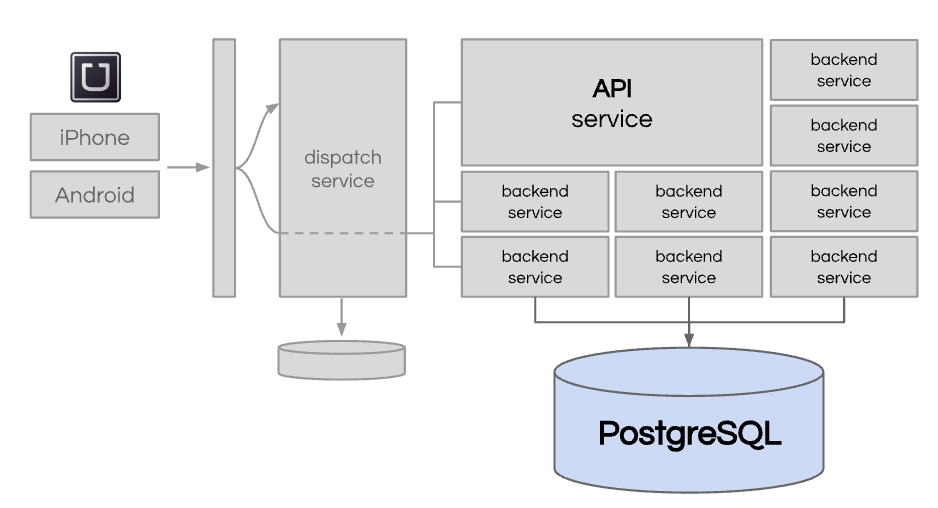
我们遇到了一些重大问题。首先,该数据库的性能、可扩展性和可用性都很困难。你只能投入这么多的内存和CPU。其次,工程师变得越来越难以高效工作。为新功能添加新行、表或索引成为问题。
问题变得越来越存在。到 2014 年初,距离万圣节之夜(一年中最盛大的夜晚之一)还有 6 个月。我们需要一个更具可扩展性的解决方案,并且需要速度更快。
当我们研究该数据库的数据组合时,大部分存储与我们的旅行相关,这也是增长最快的。
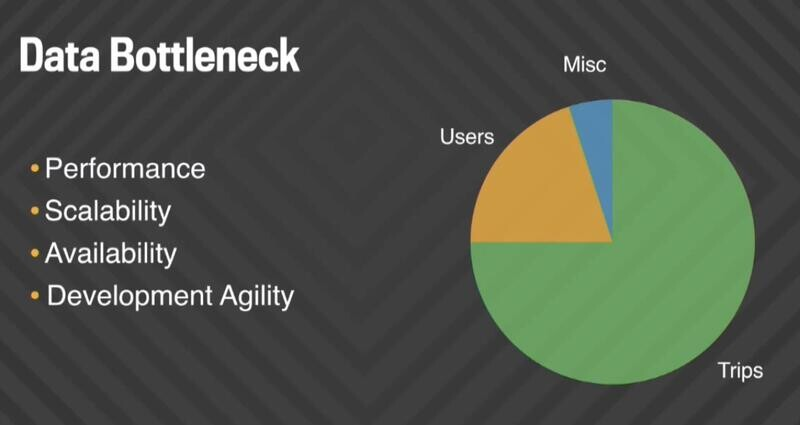
我们使用行程数据来改进 Uber Pool 等服务、提供乘客和司机支持、防止欺诈以及开发和测试建议接载等功能。因此,我们开始开发Schemaless,我们的新旅行数据存储。Schemaless 是一种仅附加的稀疏三维持久哈希图,类似于 Google 的 Bigtable,并且构建在 MySQL 之上。该模型通过将行划分到多个分片来自然地适合水平扩展,并支持我们的快速开发文化。
我们成功迁移了所有及时访问行程信息的服务,避免了万圣节高峰交通灾难。

虽然我们使用 Schemaless 来存储行程数据,但我们开始使用Cassandra来替代我们的其他数据需求,包括我们用于市场匹配和调度的数据库。
拆分调度
2014年左右
在 Uber 最初的两块巨石中,我们讨论了 API 演变为数百个微服务的过程。但派遣同样做得太多了。它不仅处理匹配逻辑,而且还是将所有其他流量路由到 Uber 内其他微服务的代理。因此,我们开始将调度分成两个更清洁的区域。
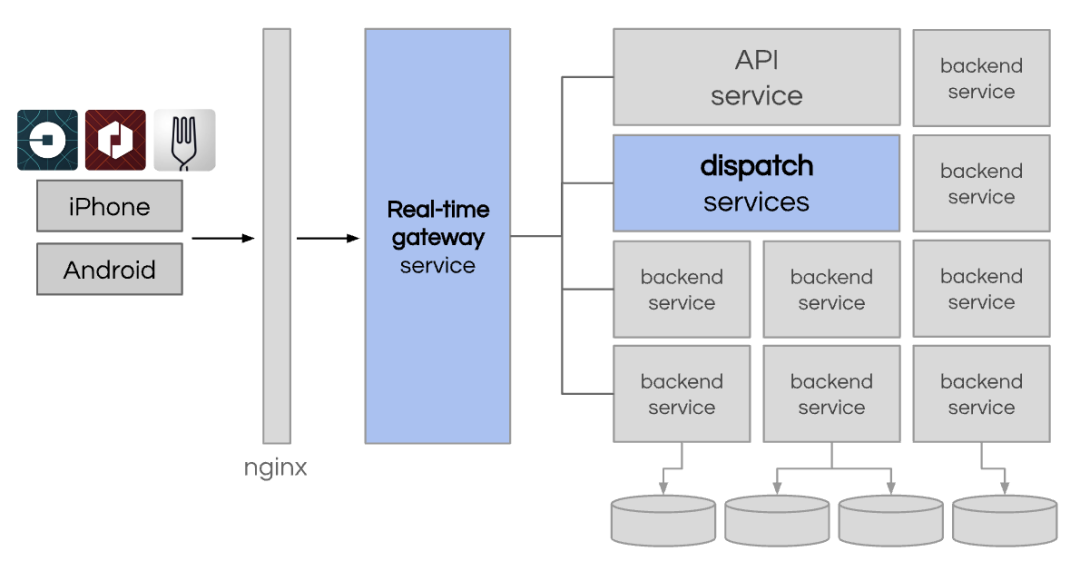
从 Dispatch 中提取 Uber 的移动网关
为了更好地处理来自移动应用程序的所有实时请求,我们创建了一个名为 RTAPI(“实时 API”)的新 API 网关层。我们继续使用 Node.js。该服务是一个单一的存储库,被分为多个专门的部署组以支持我们不断增长的业务。
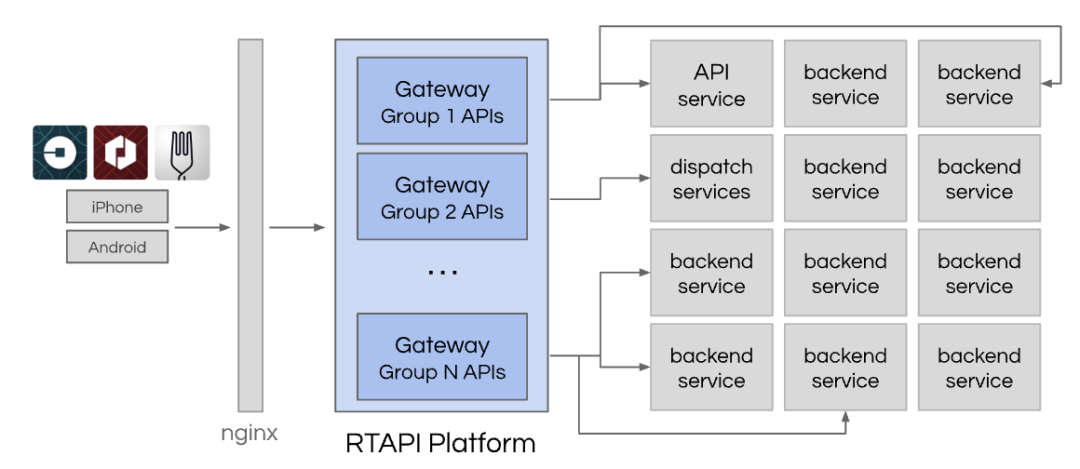
该网关为编写新代码提供了非常灵活的开发空间,并可以访问公司内的数百个服务。例如,第一代 Uber Eats 优食完全是在网关内开发的。随着团队产品的成熟,部分内容被移出网关并转移到适当的服务中。
为 Uber 不断扩大的规模重写调度
最初的调度服务是为了更简单的运输而设计的(一名司机兼一名乘客)。人们普遍认为 Uber 只需要运送人员,而不需要运送食物或包裹。其可用的司机合作伙伴的状态按城市划分。一些城市的产品数量大幅增长。
于是,dispatch被改写成一系列的服务。新的调度系统需要更多地了解车辆类型和乘客需求。
它采用了高级匹配优化,本质上是为了解决旅行商问题的一个版本。它不仅查看当前可用的司机合作伙伴的预计到达时间,还需要了解哪些司机在不久的将来可以使用。因此,我们必须建立一个地理空间索引来捕获这些信息。我们使用Google 的 S2 库将城市划分为考虑的区域,并使用 S2 小区 ID 作为分片键。
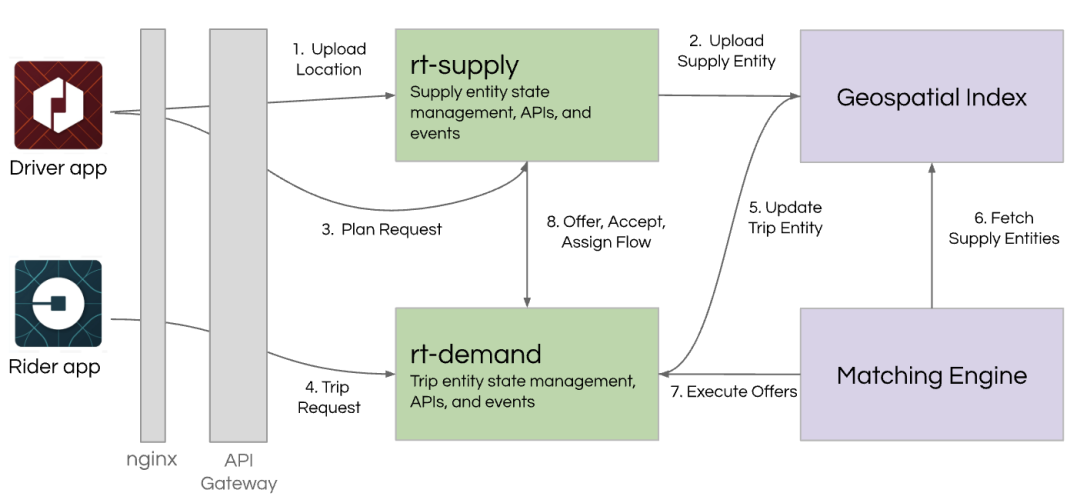
由于这些服务仍然在 Node.js 上运行并且是有状态的,因此我们需要一种随着业务增长而扩展的方法。因此,我们开发了Ringpop,这是一种基于八卦协议的方法,用于共享地理空间并提供定位以实现高效匹配。
大规模移动应用程序开发
大约2016年至今
Uber 旗舰产品之所以能够存在,是因为 2007 年 iPhone 和 Android 操作系统的推出创造了新的移动范式。这些现代智能手机包含位置跟踪、无缝地图、支付体验、设备传感器、功能丰富等关键功能。用户体验等等。
因此,Uber 的移动应用程序始终是我们扩展故事的关键部分。

随着 Uber 在全球范围内扩张,对功能的需求也不断增加。其中许多是特定于某些国家/地区的,例如本地化支付类型、不同的汽车产品类型、详细的机场信息,甚至是应用程序中的一些新选项,例如 Uber Eats 和 Uber for Business。
移动应用程序的存储库慢慢遇到了与后端单体类似的瓶颈。许多功能和许多工程师都试图在单个可发布的代码库上工作。
这导致 Uber 开发了移动设备的RIB 架构,从重写 Uber 主应用程序开始。
Uber Eats 优食的崛起
2017年左右
自 2014 年以来,Uber 一直在尝试一些“Uber for X 按需”概念。所有早期迹象都指向食品。因此,2015 年末 Uber Eats 优食在多伦多推出。并遵循与 UberX 类似的快速增长轨迹。
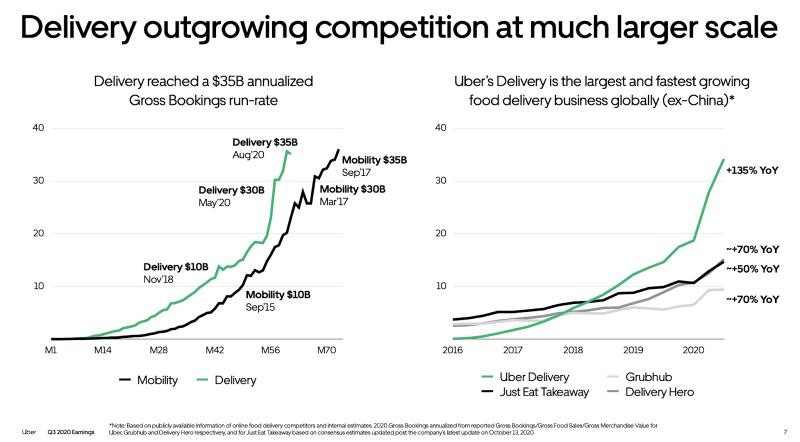
为了实现这种快速增长,Uber Eats 尽可能多地利用现有的 Uber 技术堆栈,同时创建食品配送独有的新服务和 API(例如购物车、菜单、搜索、浏览等电子商务功能)。
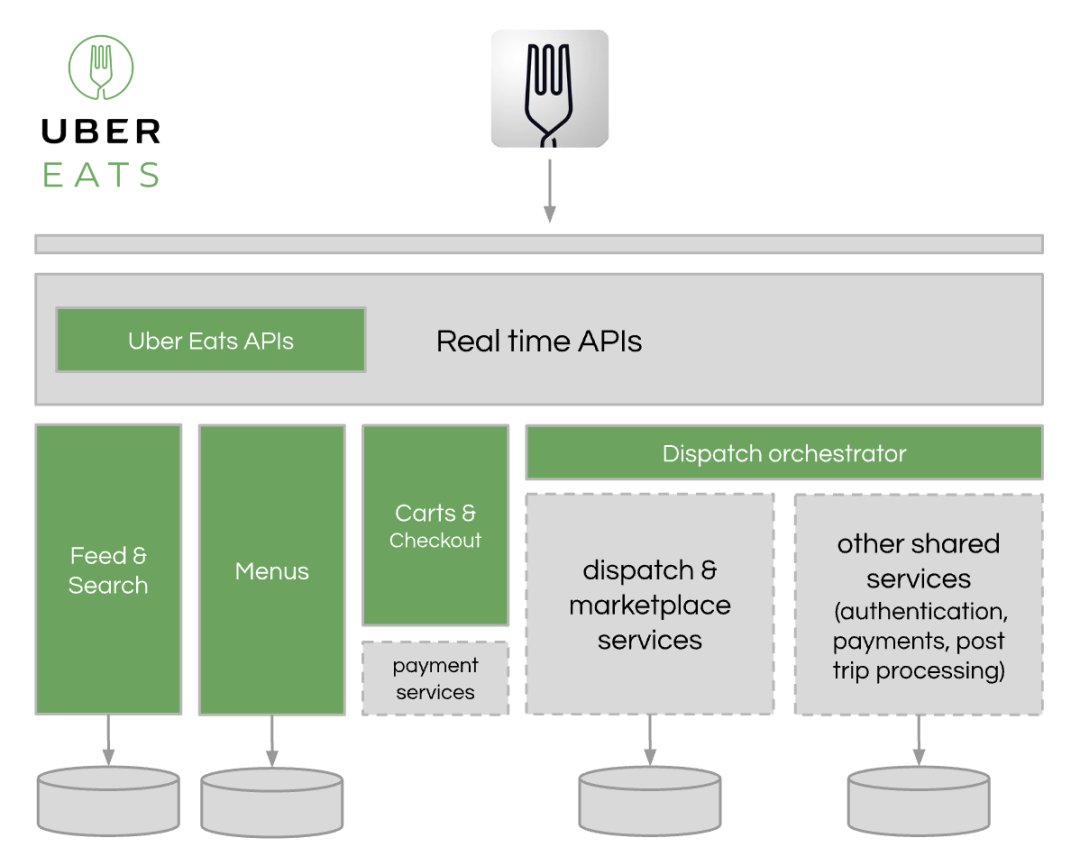
需要调整城市市场的运营团队经常发挥创造力,做一些无法扩展的事情(直到建立适当的技术)。

早期的 Uber Eats 优食很“简单”,因为它支持一个消费者、一个餐厅和一个司机伙伴的三向市场。如今的 Uber Eats 优食(超过 130 亿用户,数十个国家)支持多种订餐模式和功能,可以支持 0-N 个消费者(例如客人结账、团体订餐)、N 个商家(例如多餐厅订餐)和0-N 司机合作伙伴(例如大订单、提供自己的送货车队的餐馆)。
Uber Eats 优食的发展历史可能值得有一个自己的扩展故事,也许有一天我会讲到它。
但就目前而言,要了解更多早期的情况,我强烈建议听听 Uber Eats 创始人 Jason Droege 讲述“构建 Uber Eats”。
提高标准 - 方舟计划
2018年左右
如果不了解公司的背景和文化,任何扩展故事都是不完整的。随着优步继续逐个城市扩张,当地运营人员被聘请以确保他们的城市推出能够成功。他们拥有确保当地市场保持健康、飞轮不断发展的工具。因此,Uber 拥有一种非常分布式和去中心化的文化。这有助于 Uber 在 2018 年成功覆盖 600 个城市。
这种权力下放的文化在工程领域继续存在,我们最早的文化价值观之一就是“让建筑商建造”。这带来了快速的工程开发,补充了 Uber 在全球范围内发展的成功。
但多年后,它导致了微服务的激增(到 2018 年已有数千个)、数千个代码存储库、解决非常相似问题的多种产品解决方案以及常见工程问题的多种解决方案。例如,有不同的消息队列解决方案、不同的数据库选项、通信协议,甚至编程语言的多种选择。
“你有五六个系统,它们的激励措施彼此之间有 75% 相似”——Uber 前首席技术官 Thuan Pham 开发人员的生产力受到损害。
工程领导层认识到是时候提高标准化和一致性,并成立了方舟计划。方舟计划试图解决有助于扩展的工程文化的许多方面:
工程师生产力,
工程师跨团队协调,
复制,
未维护的关键系统,以及知识获取和文档。
因此,我们将 Java 和 Go 提升为官方后端语言,以获得类型安全和更好的性能。并弃用使用 Python 和 Javascript 进行后端服务。我们开始将代码库从 12,000 个减少到仅包含我们的主要语言(Java、Go、iOS、Android和 Web)。我们定义了更标准化的架构层,其中客户端、表示、产品和业务逻辑都有清晰的归属。我们引入了抽象,可以将许多服务组合在一起(服务“域”)。并继续对一系列服务库进行标准化,以处理跟踪、日志记录、网络协议、弹性模式等。
现代 Uber 的现代门户
2020年左右
到 2019 年,Uber 拥有了许多业务线和大量新应用程序(Uber Eats、Freight、ATG、Elevate 等)。在每个业务线中,团队管理其后端系统和应用程序。我们需要系统垂直独立,以实现快速产品开发。
我们当前的移动网关已经过时了。RTAPI 是多年前构建的,并继续使用 Node.js 和 Javascript(一种已弃用的语言)。我们也渴望利用 Uber 新定义的架构层,因为多年来添加到 RTAPI 的临时代码在视图生成和业务逻辑方面变得混乱。
因此,我们构建了一个新的Edge Gateway,开始对以下层进行标准化:
边缘层:API生命周期管理层。不能添加无关的逻辑以保持干净。
表示层:构建视图生成和来自许多下游服务的数据聚合的微服务。
产品层:提供描述其产品的功能性且可重用的 API 的微服务。可以被其他团队重用来组合和构建新的产品体验。
领域层:微服务是为产品团队提供单一细化功能的叶节点。
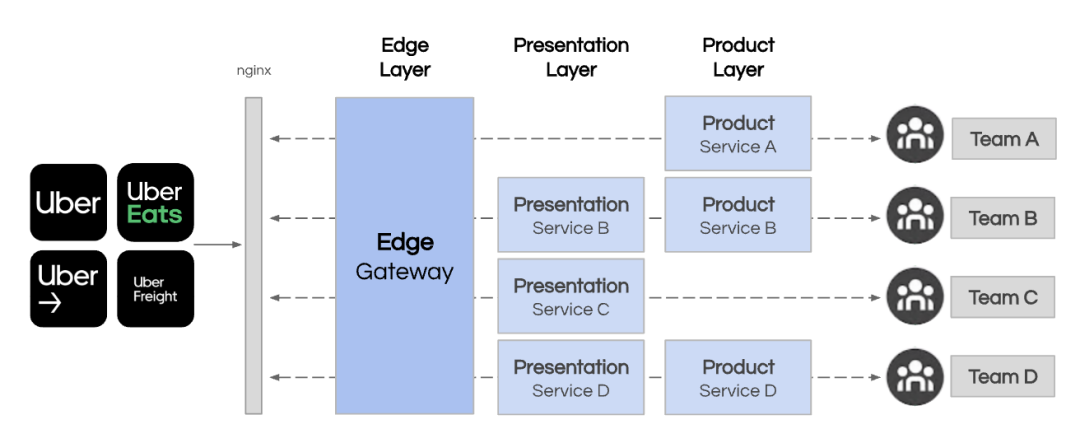
这种演变使我们能够继续快速开发新产品,同时拥有必要的结构来协调我们的 1000 名工程师。
下一代履行
大约2021年
多年来,Uber 创建了一个世界一流的平台来匹配乘客和司机合作伙伴。因此,我们的调度和履行技术堆栈是 Uber 扩展故事的关键部分。
到 2021 年,Uber 寻求为越来越多的交付和移动用例提供支持。履行堆栈已显老态,无法轻松支持所有这些新场景。例如,我们需要支持预先确认司机的预订流程、同时提供多个行程的批处理流程、机场的虚拟队列机制、Uber Eats 的三边市场以及通过 Uber Direct 交付包裹。

于是我们下了一个大胆的赌注,踏上了从头开始重写履行平台的旅程。
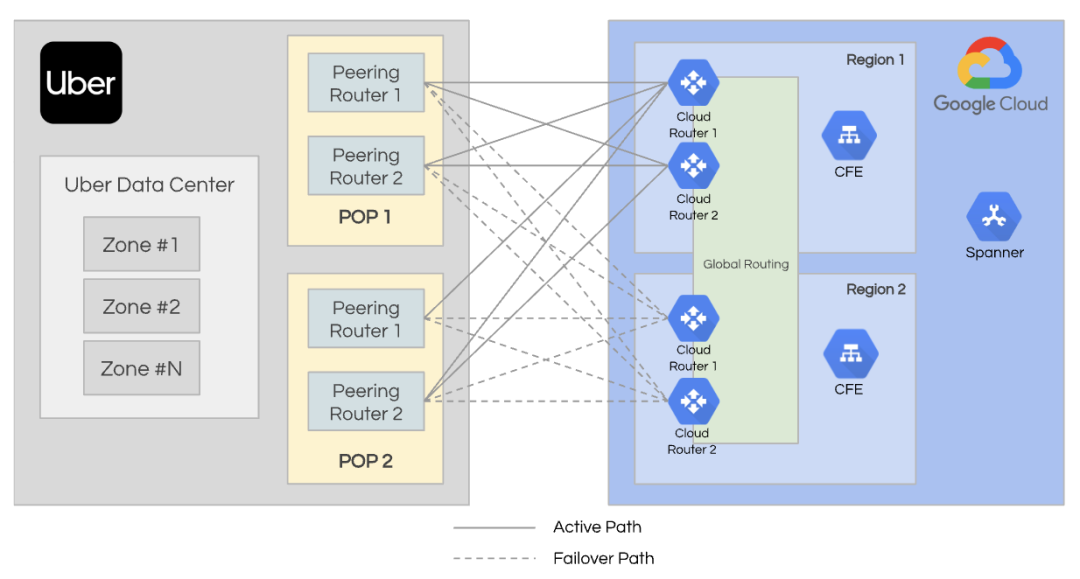
为了满足事务一致性、水平可扩展性和低运营开销的要求,我们决定利用 NewSQL 架构。并选择使用Google Cloud Spanner作为主要存储引擎。
正如Uber 首席工程师 Ankit Srivastava所说,“随着我们规模和扩大全球足迹,Spanner 的可扩展性和低运营成本是无价的。在集成 Spanner 之前,我们的数据管理框架需要大量的监督和运营工作,从而增加了复杂性和支出”。
我们还做了什么?
当然,我们的扩展故事从来没有这么简单。多年来,我们在所有工程和运营团队中做了无数的事情,包括其中一些更大的举措。
我们的许多最关键的系统都有自己丰富的历史和多年来解决规模问题的演变。这包括我们的API 网关、履行堆栈、货币堆栈、实时数据智能平台、地理空间数据平台(我们在其中开源H3)以及通过Michelangelo大规模构建机器学习。
我们介绍了 Redis 缓存的各个层。我们启用了强大的新框架来帮助可扩展且可靠的系统,例如Cadence(用于编写容错、长时间运行的工作流程)。
我们构建并利用了可实现长期增长的数据基础设施,就像我们利用 Presto或扩展 Spark 的方式一样。值得注意的是,我们构建了Apache Hudi来以低延迟和高效率为业务关键数据管道提供支持。
最后,我们继续通过优化的硬件、先进的内存和系统调整以及利用更新的运行时来提高服务器的性能。
下一步是什么?走向云端
作为一家全球性公司,Uber 从一开始就在多个本地数据中心运营。但这带来了许多挑战。
首先,我们的服务器群增长迅速(超过 250,000 台服务器),并且工具和团队始终努力跟上。其次,我们的地理覆盖范围很大,需要定期扩展到更多的数据中心和可用区域。最后,由于只有本地机器,我们需要不断调整机群的规模。
在过去的几年里,我们致力于使4000 多个无状态微服务变得可移植。为了确保我们的堆栈能够在云和本地环境中同样良好地工作,我们开始使用Project Crane来解决这个问题。这一努力为 Uber 的未来奠定了良好的基础。要了解更多信息,请观看 Uber 首席工程师Kurtis Nusbaum 关于 Crane 如何解决我们的扩展问题的演讲。
我们现在计划在未来几年内将大部分在线和离线服务器迁移到云端!
随手关注或者”在看“,诚挚感谢!















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









