







1、什么是哈夫曼树
哈夫曼树:它是 n 个带权叶子结点构成的所有二叉树中,带权路径长度 WPL 最小的二叉树(又称最优二叉树)。
WPL树的带权路径长度:
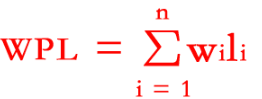
wi表示权值
li表示树的深度
例如:

上面三棵树的带权路径长度分别是:
WPL(1) = 4*2+7*3+5*3+2*1=46
WPL(2)=7*2+5*2+2*2+4*2=36
WPL(3)=7*1+5*2+2*3+4*3=35
其中第三棵就是一棵哈夫曼树。
2、如何构建一棵哈夫曼树
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1)将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2)在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权 值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
如:对下图中的六个带权叶子结点来构造一棵哈夫曼树,步骤如下:


注意:为了使得到的哈夫曼树的结构尽量唯一,通常规定生成的哈夫曼树中每个结点的左子树根结点的权小于等于右子树根结点的权。
算法如下:
//2、根据数组 a 中 n 个权值建立一棵哈夫曼树,返回树根指针
struct BTreeNode* CreateHuffman(ElemType a[], int n)
{
int i, j;
struct BTreeNode **b, *q;
b = malloc(n*sizeof(struct BTreeNode));
for (i = 0; i < n; i++) //初始化b指针数组,使每个指针元素指向a数组中对应的元素结点
{
b[i] = malloc(sizeof(struct BTreeNode));
b[i]->data = a[i];
b[i]->left = b[i]->right = NULL;
}
for (i = 1; i < n; i++)//进行 n-1 次循环建立哈夫曼树
{
//k1表示森林中具有最小权值的树根结点的下标,k2为次最小的下标
int k1 = -1, k2;
for (j = 0; j < n; j++)//让k1初始指向森林中第一棵树,k2指向第二棵
{
if (b[j] != NULL && k1 == -1)
{
k1 = j;
continue;
}
if (b[j] != NULL)
{
k2 = j;
break;
}
}
for (j = k2; j < n; j++)//从当前森林中求出最小权值树和次最小
{
if (b[j] != NULL)
{
if (b[j]->data < b[k1]->data)
{
k2 = k1;
k1 = j;
}
else if (b[j]->data < b[k2]->data)
k2 = j;
}
}
//由最小权值树和次最小权值树建立一棵新树,q指向树根结点
q = malloc(sizeof(struct BTreeNode));
q->data = b[k1]->data + b[k2]->data;
q->left = b[k1];
q->right = b[k2];
b[k1] = q;//将指向新树的指针赋给b指针数组中k1位置
b[k2] = NULL;//k2位置为空
}
free(b); //删除动态建立的数组b
return q; //返回整个哈夫曼树的树根指针
}
3、哈夫曼编码
在电报通信中,电文是以二进制的0、1序列传送的,每个字符对应一个二进制编码,为了缩短电文的总长度,采用不等长编码方式,构造哈夫曼树,
将每个字符的出现频率作为字符结点的权值赋予叶子结点,每个分支结点的左右分支分别用0和1编码,从树根结点到每个叶子结点的路径上
所经分支的0、1编码序列等于该叶子结点的二进制编码。如上文所示的哈夫曼编码如下:

a 的编码为:00
b 的编码为:01
c 的编码为:100
d 的编码为:1010
e 的编码为:1011
f 的编码为:11















 29万+
29万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









