







来自ng的ml-003中 18_XVIII._Application_Example-_Photo_OCR
这是ng2013年在coursera上最后的一课了。这一系列的几个视频还是相比前面有些难懂,。。。。。。
ng说拿这个做例子有三个原因:一、演示如何将复杂的机器学习进行融合;二介绍下机器学习的type line和当你决定做某事的时候如何的利用资源;三、这个例子能够说明更多有趣的机器学习idea(将机器学习用于计算机视觉,人工数据综合)

首先是图像中的文字识别
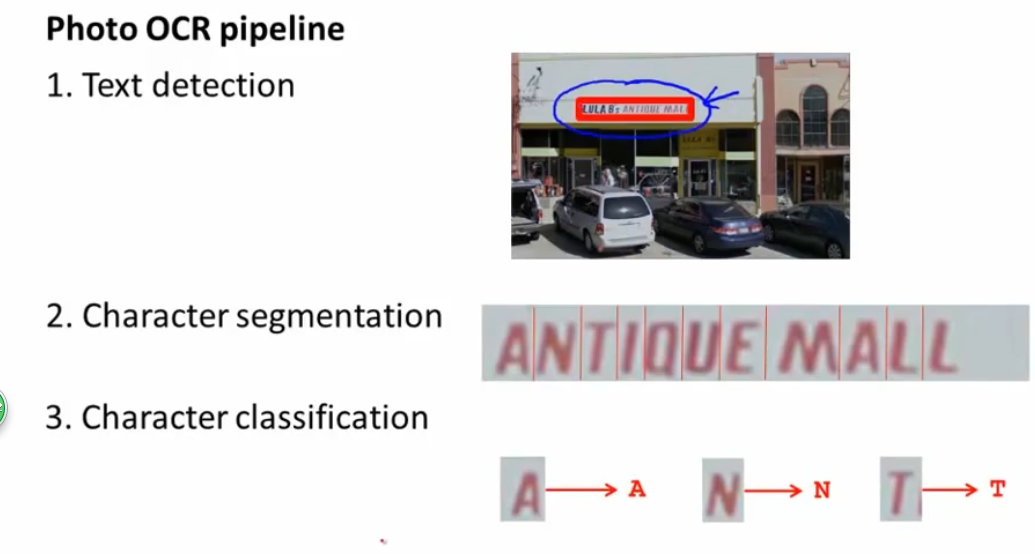
这是最简单的几部划分,(但是比如你之前的单词是cleaning,但是机器有可能会反馈给你c1eaning,会有少许的错误,简单的提下)
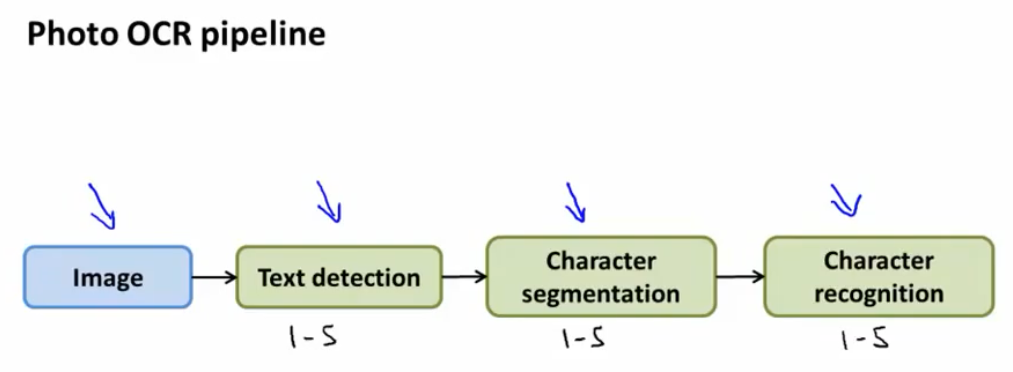
这里是一个OCR识别的管道图,下面是每个部分差不多需要这么多人的合作,但是(ng最后居然说其实一个人完成整个工作也是可以的,如果他知道怎么做的话,唉)
一、滑动窗口
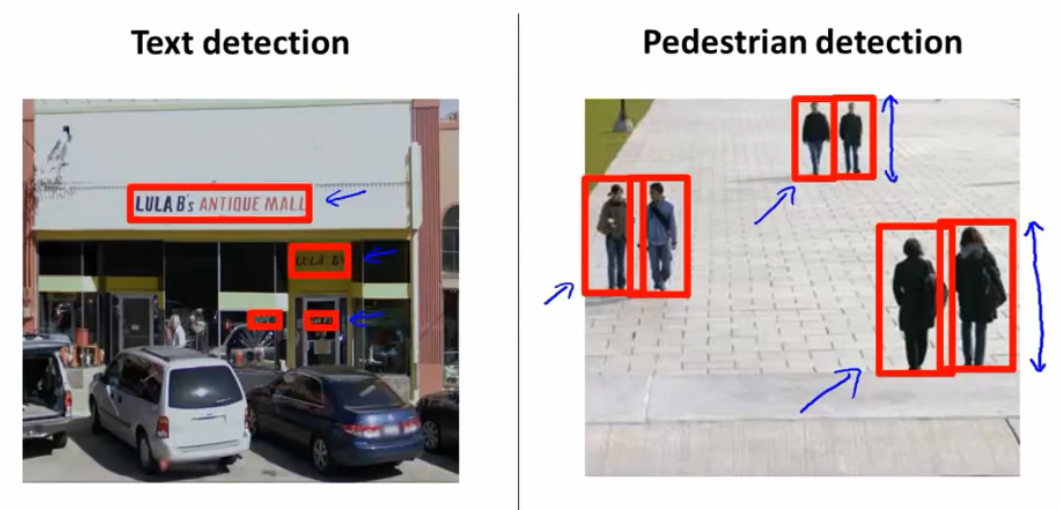
相对应来说,行人检测中的窗口比较简单,因为他的背景较为单一,不像之前的文本识别,背景很是复杂,在行人检测中,要考虑到不同距离下不同人的窗口的高度和宽度等等。

这里是个简单的数据集的例子,通过观察采用这么大的窗口较为合适,行人检测的数据集一般都是1k或者10k等等的

从图的左上角开始一个82*36的窗口,然后分类获得这个是y=0,就是非行人的数据,然后将窗口右移

这样就能够获得这样一个结果

通过这样的方法就能应用在文字识别上,通过不同的滑动窗口获得文本的位置

通过不同的滑动窗口最后就锁定了文字的位置,然后进行图片的放大来更清晰的显示字符串的位置

但是如果采用中间划分的方法,左边的明显是滑动窗口取到了两个字,而右边的是取到了一个完整的字

通过一种方法当滑动窗口滑倒完整的字的时候不采用切分,而滑倒两个字的时候采用切分。
二、人工数据结合
ng说见过的最好的机器学习算法都是采用一个low bias算法,然后再大量的数据上运行。对于文字识别来说。数据有一个是来自于真实的数据,一个是来自于众多的字体库

或者通过采用字体库的字体,在放到实际数据的背景上合成人工数据:

或者是在数据上加上扭曲等方法

在音频上:


对于数据添加噪声来说,添加的噪声是有意义的,比如上图中的扭曲是可以在test中真实找到的,(类似模拟test数据一样)。而下文中的椒盐噪声是无意义的,添加了也没什么帮助,因为在这个例子中,我们是想识别的文字而且文字的扭曲是真实世界中看得到的,而添加的椒盐噪声是除非你就是为了比如降噪这种噪音,能够在test中看到的,因为这里是为了识别不同形状的a,而不是为了降噪,

按照上图说的,在添加人工合成的数据的时候,一定要知道你的模型是不是过拟合的,如果模型是欠拟合的,那么增加再多的数据都是在浪费时间。其次,可以坐下来和团队的人员一起问问 想要这些数据的处理速度提升10x,需要做多少工作:1、人工合成;2、手动添加标签;3、寻找混合来源。
三、细胞级别分析

如上图来说,对于整个系统而言,每个地方都是需要做工作的,但是如何找到这个系统的瓶颈之处,通过提升这个系统的瓶颈来达到提升整个系统的效率,这是值得思考的,不然在其他表现很好的环节上大量的工作,最后还是在浪费时间
相比较而言,首先没有任何改变的情况下最好的精度是72%,然后通过修改第二项,让他的输出是100准确的,那么整个系统提升到89%的精度,有17%的改变,说明这部分值得我们花时间,然后再改动第二项的基础上,接着将第三项改动成完美情况下,整个系统只提升了1%,这说明第三项是很好的,差不多不需要花时间去完善。
这同样让我们知道每个部分的上限是多少,和在这个部分的上限上运行的时候整个系统的精度是多少


上面两个图就是一个人脸检测的模型过程。

通过与最原始的模型的效果相对比,先逐个部分的进行人工的修改(即将这个部分的精度提到上限),比如第一部分的背景移除,可以通过ps等软件人工的去除,然后将这个完美的模型代替第一部分的输出,观察整个模型提升的效果,这里第一个模型只提升了0.1%,说明这部分没什么可改善的地方。接着往下按照这种原理进行。找到整个模型的瓶颈之处。
就是用人工的小数据去验证模型的瓶颈,而不至于花了很久时间才发现其实都在浪费时间。















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









