







1、基本概念
散列(hash)同顺序、链接和索引一样,是存储数据的又一种方法。
散列存储的基本思想是:以数据(通常为集合)中的每个元素的关键字K为自变量,通过一种函数h(K)计算出函数值,
把这个值解释为一块连续存储空间(即数组空间或文件空间)的单元地址(即下标),将该元素存储到这个单元中。
散列存储中使用的函数h(K),称为散列函数或哈希函数,它实现关键字到存储地址的映射(或称转换),h(K)的值称为散列地址或哈希地址;
使用的数组空间是数据进行散列存储的地址空间,所以被称之为散列表或哈希表(hash list或hash table)。
在散列表上进行查找时,首先根据给定的关键字K,用与散列存储时使用的同一散列函数h(K)计算出散列地址,然后按此地址从散列表中取出对应的元素。
假定一个集合为
S={18,75,60,43,54,90,46}
其中每个整数可以是元素本身,也可以仅是元素的关键字,用以代表整个元素。为了散列存储该集合,假定选取的散列函数为:
h(K)=K % m
即用元素的关键字K整除以散列表的长度m,取余数(即为0至m-1范围内的一个数)作为存储该元素的散列地址,
这里假定K和m均为正整数,并且m要大于等于待散列存储的集合的长度n。在此例中,n=7,所以假定取m=13,则得到的每个元素的散列地址为:
h(18)=18 % 13=5 h(75)=75 %13=10
h(60)=60 % 13=8 h(43)=43 %13=4
h(54)=54 % 13=2 h(90)=90 %13=12
h(46)=46 % 13=7
若根据散列地址把元素存储到散列表H[m]中,则存储映象为:

2、 散列函数
1. 直接定址法
h(K) = K + C
这种方法关键字分配不连续,存储空间严重浪费
2. 除留余数法
除留余数法是用关键字K除以散列表长度m所得余数作为散列地址的方法。对应的散列函数h(K)为:
h(K) = K % m
这种方法计算简单,适用范围广
3. 数字分析法
数字分析法是取关键字中某些取值较分散的数字位做为散列地址的方法。
4. 平方取中法
平方取中法是取关键字平方的中间几位作为散列地址的方法,具体取多少位视实际要求而定。
5. 折叠法
折叠法是首先将关键字部分分割成位数相同的几段(最后一段的位数若不足应补0),段的位数取决于散列地址的位数,由实际需要而定,然后将他们的叠加和
(舍去最高位进位)作为散列地址的方法。
3、 处理冲突的方法
1、开放定址法
(1) 线性探查法
d=h(K)
di=(di-1+1) % m (1≤i≤m-1, d0=d)
向前面的例子中构造的H散列表中再插入关键字分别为31和58的两个元素,若发生冲突则使用线性探查法处理。
先看插入关键字为31的元素的情况。关键字为31的散列地址为h(31)=31 % 13=5,因H[5]单元已被占用,接着探查下一个即下标为6的单元,因该单元空闲,所以关键字为31的元素被存储到下标为6的单元中,此时对应的散列表H为:

再看插入关键字为58的元素的情况。关键字为58的散列地址为h(58)=58 % 13=6,因H[6]已被占用,接着探查下一个即下标为7的单元,因H[7]仍不为空,再接着探查下标为8的单元,这样当探查到下标为9的单元时,才查找到一个空闲单元,所以把关键字为58的元素存入该单元中,此时对应的散列表H为:

利用线性探查法处理冲突容易造成元素的堆积或称聚集。
(2) 平方探查法
平方探查法的探查序列为d,d+12,d+22,…,或表示为(d+i2) % m (0≤i≤m-1)。若使用递推公式表示,则为:
d=h(K)
di=(di-1+2i-1)% m (1≤i≤m-1, d0=d)
这种方法能够较好的避免堆积现象,它的缺点是不能探查到散列表上的所有单元,但只能探查到一半单元。
(3) 双散列函数探查法
这种方法使用两个散列函数h1和h2,其中h1和前面的h(K)一样,以关键字为自变量,产生一个0至m-1之间的数作为散列地址,h2也以关键字为自变量,
产生一个1至m-1之间的,并和m互素的数作为探查序列的地址增量。
双散列函数的探查序列为:
d=h1(K)
di=(di-1+h2(K))% m (1≤i≤m-1, d0=d)
2. 链接法
链接发又称开散列法,它是把发生冲突的同义词元素用单链表链接起来的方法。
假定一个线性表B为:
B=(18,75,60,43,54,90,46,31,58,73,15,34)
为了进行散列存储,假定采用的散列函数为:
h(K)=K % 13
当发生冲突时,假定采用链接法处理,则得到的散列表如下图所示。
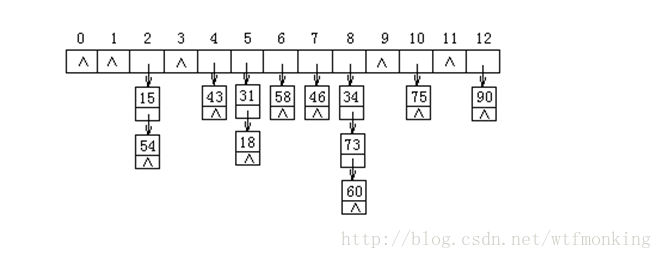
用链接法处理冲突,虽然比开放定址法多占用一些存储空间用来存储链接指针,但它可以减少在插入和查找过程中同关键字的比较次数。
4、散列表的运算操作
下面通过实例程序能够调试利用数组存储的散列表算法:
#include<stdio.h>
#include<stdlib.h>
#define HashMaxSize 43 //定义散列存储空间的最大长度为一个素数43
#define NullTag -100 //假定用 -100 作为空闲关键字标记
#define DeleteTag -200 //假定用 -200 作为已删除元素的关键字标记
struct ElemType
{
int key; //假定关键字为整型
char rest[20];//该元素类型的其他域
};
typedef struct ElemType hashlist1[HashMaxSize];//定义数组存储的散列表的类型
typedef int KeyType; //定义元素关键字的类型为整型
int H(KeyType key, int m)//可采用任一种合适的构造散列函数的方法来计算散列地址
{//这里是按关键字与m求余的方式
return key % m;
}
//1、初始化散列表
void InitHashList(hashlist1 HT)//把散列表HT中每一单元的关键字key域都设置为空标志
{
int i;
for (i = 0; i < HashMaxSize; i++)
HT[i].key = NullTag;
}//在该算法中,关键字类型为整型,NullTag为事先定义的全局常量-100,当关键字类型为
//字符串时它为空串"\0",应采用字符串函数进行比较或赋值(下同)
//2、清空一个散列表
void ClearHashList(hashlist1 HT)
{
int i;
for (i = 0; i < HashMaxSize; i++)
HT[i].key = NullTag;
}
//3、向散列表插入一个元素
int Insert(hashlist1 HT, int m, struct ElemType x)//向长度为m的散列表HT中插入一个元素x
{
int d = H(x.key, m);
int temp = d;
while (HT[d].key != NullTag)//用线性探查法处理冲突
{
d = (d + 1) % m;
if (d == temp)
{
printf("散列表空间已被占满,应重建!\n");
return 0;
}
}
HT[d] = x;
return 1
d = (d + 1) % m;
if (d == temp)
return -1;
}
return -1;
}
//5、从散列表中删除一个元素
int Delete(hashlist1 HT, int m, KeyType K)
{
int d = H(K, m);
int temp = d;
while (HT[d].key != NullTag)
{
if (HT[d].key == K)
{
HT[d].key = DeleteTag;
return 1;
}
else
d = (d + 1) % m;
if (d == temp) //循环一周仍未找到则返回0表示失败
return 0;
}
return 0;
}//在这个算法中,使用DeleteTag为删除标记,而不是直接把被删除元素单元置空,否则就割断
//了元素的查找路径,该位置也可以为后续插入元素所用,只需将插入算法中国while循环条件
//改为 HT[d].key != NullTag && HT[d].key != DeleteTag 即可。
//显示输出散列表中的所有元素,假定只输出元素的关键字
void PrintHashList(hashlist1 HT, int m)
{
int i;
printf("散列表为:");
for (i = 0; i < m; i++)
printf("%d,", HT[i].key);
printf("\n");
}
//主函数
void main()
{
int n, m, i, j;
struct ElemType x;
hashlist1 ht;
InitHashList(ht);
printf("从键盘输入待散列元素的个数n和散列表长度m:");
do
{
scanf(" %d %d", &n, &m);
if (n > m || m > HashMaxSize)
printf("重输n和m值:");
}while (n > m || m > HashMaxSize);
printf("从键盘向散列表输入%d个元素的关键字:\n", n);
for (i = 0; i < n; i++)
{
scanf(" %d", &x.key);
Insert(ht, m, x);
}
PrintHashList(ht, m);
printf("输入待删除一批元素的关键字,用-1作为结束!\n");
do
{
scanf(" %d", &x.key);
if (x.key == -1)
break;
Delete(ht, m, x.key);
}while(1);
PrintHashList(ht, m);
printf("输入待插入散列表的一批元素的关键字,用-1作为结束!\n");
do
{
scanf(" %d", &x.key);
if (x.key == -1)
break;
Insert(ht, m, x);
}while(1);
PrintHashList(ht, m);
printf("从键盘上输入一批待查找元素的关键字,用-1作为结束!\n");
do
{
scanf(" %d", &x.key);
if (x.key == -1)
break;
if ((j = Search(ht, m, x.key)) != -1)
printf("查找关键字为%d的元素成功,返回下标值为%d\n", x.key, j);
else
printf("查找关键字为%d的元素失败!\n", x.key);
}while(1);
ClearHashList(ht);
}
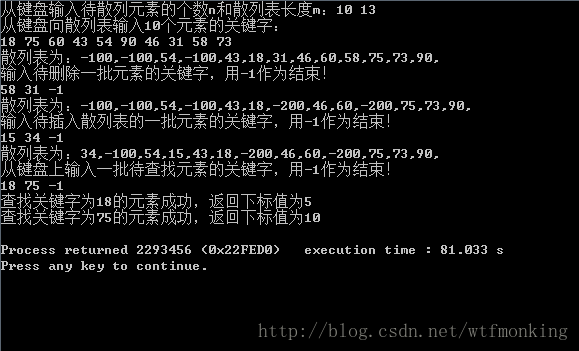
上面程序处理冲突是采用的开放定址法,运行结果如下:
若采用链接法处理冲突,则具体运算如下:
struct sNode
{
ELemType data;
struct sNode* next;
};
typedef struct sNode* hashlist2[HashMaxSize];
//1、初始化散列表
void InitHashList(hashlist2 HT)
{
int i;
for (i = 0; i < HashMaxSize; i++)
HT[i] = NULL;
}
//2、清空一个散列表
void ClearHashList(hashlist2 HT)
{
int i;
struct sNode* p;
for (i = 0; i < HashMaxSize; i++)
{
p = HT[i];
while (p != NULL)
{
HT[i] = p->next;
free(p);
p = HT[i];
}
}
}
//3、向散列表插入一个元素
int Insert(hashlist2 HT, int m, struct ElemType x)
{
int d = H(x.key, m);
struct sNode* p = malloc(sizeof(struct sNode));
if (p == NULL)
{
printf("内存空间用完!\n");
return 0;
}
p->data = x;
p->next = HT[d];//把新节点插入到d单链表的表头
HT[d] = p;
return 1;
}
//4、从散列表中查找一个元素
struct ELemType* Search(hashlist2 HT, int m, KeyType K)
{
int d = H[K, m];
struct sNode* p = HT[d];
while (p != NULL)
{
if (p->data.key == K)
return &(p->data);
else
p = p->next;
}
return NULL;
}
//5、从散列表中删除一个元素
int Delete(hashlist2 HT, int m, KeyType K)
{
int d = H(K, m);
struct sNode* p = HT[d], *q;
if (p == NULL)
return 0;
if (p->data.key == K)//若表头结点为被删除的结点
{
HT[d] = p->next;
free(p);
return 1;
}
q = p->next;
while (q != NULL) //从第二个结点开始向下查找被删除的元素
{
if (q->data.key == K)
{
p->next = q->next;
free(q);
return 1;
}
else
{
p = q;
q = q->next;
}
}
return 0;
}















 5124
5124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









