






纠结了好多天,终于弄懂了B440X的处理。
上篇讲到通过中断,最终网卡调用了b44_rx()来接收报文
对这个函数中的一些参数,可以这样理解:
bp->rx_cons –处理器处理到的缓冲区号
bp->rx_pending –分配的缓冲区个数
bp->rx_prod –当前缓冲区的最后一个缓冲号
这里要参数B440X的手册了解下寄存器的作用:
#define B44_DMARX_ADDR 0x0214UL /* DMA RX Descriptor Ring Address */
#define B44_DMARX_PTR 0x0218UL /* DMA RX Last Posted Descriptor */
#define B44_DMARX_STAT0x021CUL /* DMA RX Current Active Desc. + Status */
仅b44_rx()来说,B44_DMARX_ADDR储存了环形缓冲的基地址,B44_DMARX_PTR存储了环形缓冲最后一个缓冲区号,这两个寄存器都由处理来设置;B44_DMARX_STAT储存了状态及网卡当前处理到的缓冲区号,这个寄存器只能由网卡来设置。
网卡中DMA也很重要:
在网卡初始化阶段,b44_open() -> b44_alloc_consistent()
bp->rx_buffers = kzalloc(size, gfp); // size = B44_RX_RING_SIZE * sizeof(struct ring_info)
bp->rx_ring = ssb_dma_alloc_consistent(bp->sdev, size, &bp->rx_ring_dma, gfp);
// size = DMA_TABLE_BYTES
rx_ring是DMA映射的虚拟地址,rx_rind_dma是DMA映射的总线地址,这个地址将会写入B44_DMARX_ADDR寄存器,作为环形缓冲的基地址。
bw32(bp, B44_DMARX_ADDR, bp->rx_ring_dma + bp->dma_offset);
稍后在rx_init_rings() -> b44_alloc_rx_skb()
mapping = ssb_dma_map_single(bp->sdev, skb->data,RX_PKT_BUF_SZ,DMA_FROM_DEVICE);
将rx_buffers进行DMA映射,并将映射地址存储在rx_ring中
dp->addr = cpu_to_le32((u32) mapping + bp->dma_offset); // dp是rx_ring中一个
DMA的大致流程:
不准确,但可以参考下大致意思

网卡读取B44_DMARX_ADDR与B44_DMARX_STAT寄存器,得到下一个处理的struct dma_desc,然后根据dma_desc中的addr找到报文缓冲区,通过DMA处理器将网卡收到报文拷贝到addr地址处,这个过程CPU是不参与的。
prod –网卡[硬件]处理到的缓冲区号
prod = br32(bp, B44_DMARX_STAT) & DMARX_STAT_CDMASK;
prod /= sizeof(struct dma_desc);
cons = bp->rx_cons;
根据上面分析,prod读取B44_DMARX_STAT寄存器,存储网卡当前处理到的缓冲区号;cons存储处理器处理到的缓冲区号。
while (cons != prod && budget > 0) {
处理报文当前时刻网卡接收到的所有报文,每处理一个报文cons都会加1,由于是环形缓冲,因此这里用相等,而不是大小比较。
struct ring_info *rp = &bp->rx_buffers[cons];
struct sk_buff *skb = rp->skb;
dma_addr_t map = rp->mapping;
skb和map保存了当关地址,下面在交换缓冲区后会用到。
ssb_dma_sync_single_for_cpu(bp->sdev, map,RX_PKT_BUF_SZ,DMA_FROM_DEVICE);
CPU取得rx_buffer[cons]的控制权,此时网卡不能再处理该缓冲区。
rh = (struct rx_header *) skb->data;
len = le16_to_cpu(rh->len);
….
len -= 4;
CPU取得控制权后,取得报文头,再从报文头取出报文长度len,len-=4表示忽略了最后4节字的CRC,从这里可以看出,B440X网卡驱动不会检查CRC校验。而每个报文数据最前面添加了网卡的头部信息struct rx_header,这里是28字节。
struct sk_buff *copy_skb;
b44_recycle_rx(bp, cons, bp->rx_prod);
copy_skb = netdev_alloc_skb(bp->dev, len + 2);
copy_skb作为传送报文的中间量,在第三句为其分配了len + 2的空间(为了IP头对齐,稍后提到)。b44_recycle_rx()函数很关键,它作了如下工作:
1. 将缓冲区号cons赋值给缓冲区号rx_prod;
2. rx_buffers[cons].skb = NULL
3. 将缓冲区号rx_prod控制权给网卡
简单来说,就是将cons号缓冲区交由CPU处理,而用rx_prod号缓冲区代替其给网卡使用。

a. b44_recycle_rx前 b. b44_recycle_rx后
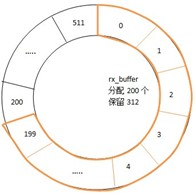
以起始状态为例,缓冲区rx_ring分配了512个,但rx_buffers仅分配了200个,此时cons = 0,rx_prod = 200。执行b44_recycle_rx()后,网卡处理缓冲区变为1~200,而0号缓冲区交由CPU处理,将报文拷贝,并向上送至协议栈。注意rx_ring和rx_buffer是不同的。
这样做的好处在于,不用等待CPU处理完0号缓冲区,网卡的缓冲区数保持200,而不会减少,这也是rx_pending = 200的原因所在。
skb_reserve(copy_skb, 2);
skb_put(copy_skb, len);
关于skb的操作自己去了解,这里skb_reserve()在报文头部保留了两个字节,我们知道链路层报头是14字节,正常IP报文会从14字节开始,这样就不是4字节对齐了,所以在头部保留2字节,使IP报文从16字节开始。
skb_copy_from_linear_data_offset(skb, RX_PKT_OFFSET,copy_skb->data, len);
skb = copy_skb;
CPU将报文从skb拷贝到copy_skb中,跳过了网卡报头的额外信息,因为这部分信息在上层协议站是没用的,所以去掉。在函数开始时说过skb是保存了cons号的地址,因为在b44_recycle_rx()后cons号不再引用skb指向的空间,而仅由skb引用,这样便可以向上层传送,而不用额外复制。
netif_receive_skb(skb);
received++;
budget--;
next_pkt:
bp->rx_prod = (bp->rx_prod + 1) & (B44_RX_RING_SIZE - 1);
cons = (cons + 1) & (B44_RX_RING_SIZE - 1);
netif_receive_skb()将报文交由上层协议栈处理,这是下一节的内容,然后CPU处理下一个报文,rx_prod和cons各加1,它们代表的含义开头有说明。
如此循环,直到cons == prod,此时网卡收到的报文都已被CPU处理,更新变量:
bp->rx_cons = cons;
bw32(bp, B44_DMARX_PTR, cons * sizeof(struct dma_desc));















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









