





 ApacheFlink的DataStreamAPI用于处理数据流,它包括获取执行环境、定义数据源、应用转换、指定输出以及触发程序执行等步骤。DataStream是不可变的,通过各种API方法进行操作。Flink程序通常包含获取执行环境、加载/创建初始数据、指定转换、设置结果输出位置以及启动执行。文章还介绍了如何创建和使用数据源,以及如何应用如map、filter等转换。此外,文章提到了窗口操作、数据源(如文件、套接字、集合)以及数据流转换,包括Map、FlatMap、Filter、KeyBy、Reduce等。
ApacheFlink的DataStreamAPI用于处理数据流,它包括获取执行环境、定义数据源、应用转换、指定输出以及触发程序执行等步骤。DataStream是不可变的,通过各种API方法进行操作。Flink程序通常包含获取执行环境、加载/创建初始数据、指定转换、设置结果输出位置以及启动执行。文章还介绍了如何创建和使用数据源,以及如何应用如map、filter等转换。此外,文章提到了窗口操作、数据源(如文件、套接字、集合)以及数据流转换,包括Map、FlatMap、Filter、KeyBy、Reduce等。
Apache Flink — Stateful Computations over Data Streams
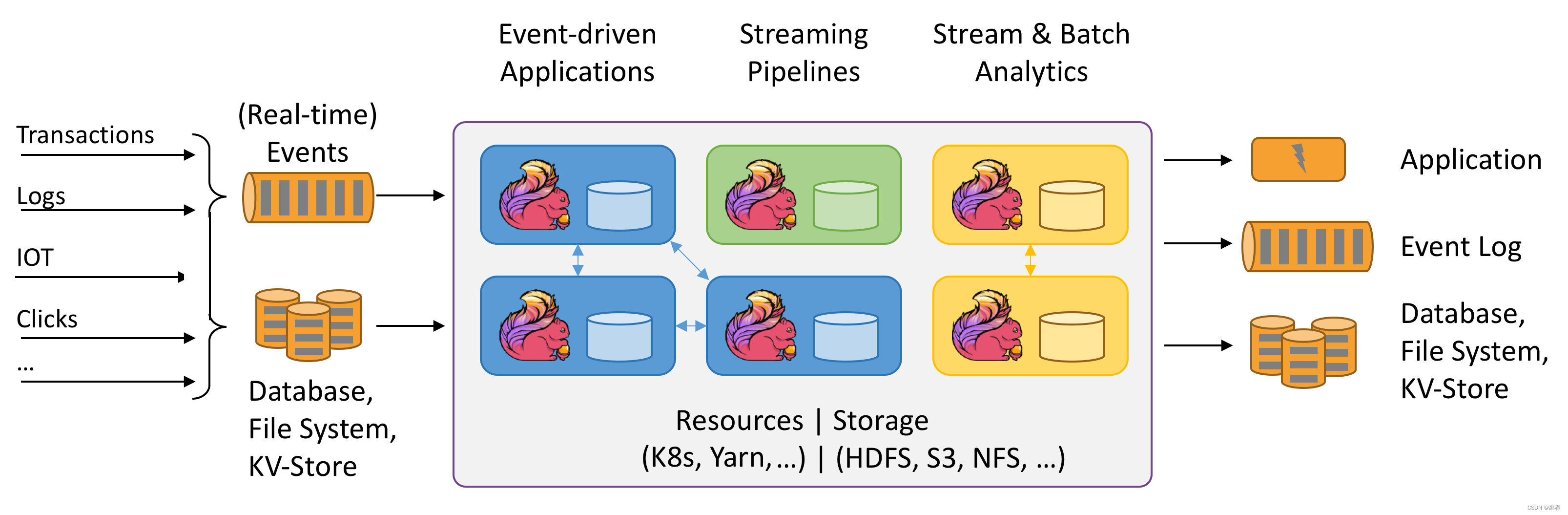
What is a DataStream?
The DataStream API gets its name from the special DataStream class that is used to represent a collection of data in a Flink program. You can think of them as immutable collections of data that can contain duplicates. This data can either be finite or unbounded, the API that you use to work on them is the same.
A DataStream is similar to a regular Java Collection in terms of usage but is quite different in some key ways. They are immutable, meaning that once they are created you cannot add or remove elements. You can also not simply inspect the elements inside but only work on them using the DataStream API operations, which are also called transformations.
You can create an initial DataStream by adding a source in a Flink program. Then you can derive new streams from this and combine them by using API methods such as map, filter, and so on.
Anatomy of a Flink Program
Flink programs look like regular programs that transform DataStreams. Each program consists of the same basic parts:
1 Obtain an execution environment,
2 Load/create the initial data,
3 Specify transformations on this data,
4 Specify where to put the results of your computations,
5 Trigger the program execution
All Flink Scala APIs are deprecated and will be removed in a future Flink version. You can still build your application in Scala, but you should move to the Java version of either the DataStream and/or Table API.
See FLIP-265 Deprecate and remove Scala API support
We will now give an overview of each of those steps, please refer to the respective sections for more details. Note that all core classes of the Java DataStream API can be found in org.apache.flink.streaming.api .
The StreamExecutionEnvironment is the basis for all Flink programs. You can obtain one using these static methods on StreamExecutionEnvironment:
getExecutionEnvironment();
createLocalEnvironment();
createRemoteEnvironment(String host, int port, String... jarFiles);
Typically, you only need to use getExecutionEnvironment(), since this will do the right thing depending on the context: if you are executing your program inside an IDE or as a regular Java program it will create a local environment that will execute your program on your local machine. If you created a JAR file from your program, and invoke it through the command line, the Flink cluster manager will execute your main method and getExecutionEnvironment() will return an execution environment for executing your program on a cluster.
For specifying data sources the execution environment has several methods to read from files using various methods: you can just read them line by line, as CSV files, or using any of the other provided sources. To just read a text file as a sequence of lines, you can use:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("file:///path/to/file");
This will give you a DataStream on which you can then apply transformations to create new derived DataStreams.
You apply transformations by calling methods on DataStream with a transformation functions. For example, a map transformation looks like this:
DataStream<String> input = ...;
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
This will create a new DataStream by converting every String in the original collection to an Integer.
Once you have a DataStream containing your final results, you can write it to an outside system by creating a sink. These are just some example methods for creating a sink:
writeAsText(String path);
print();
Once you specified the complete program you need to trigger the program execution by calling execute() on the StreamExecutionEnvironment. Depending on the type of the ExecutionEnvironment the execution will be triggered on your local machine or submit your program for execution on a cluster.
The execute() method will wait for the job to finish and then return a JobExecutionResult, this contains execution times and accumulator results.
If you don’t want to wait for the job to finish, you can trigger asynchronous job execution by calling executeAsync() on the StreamExecutionEnvironment. It will return a JobClient with which you can communicate with the job you just submitted. For instance, here is how to implement the semantics of execute() by using executeAsync().
final JobClient jobClient = env.executeAsync();
final JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
That last part about program execution is crucial to understanding when and how Flink operations are executed. All Flink programs are executed lazily: When the program’s main method is executed, the data loading and transformations do not happen directly. Rather, each operation is created and added to a dataflow graph. The operations are actually executed when the execution is explicitly triggered by an execute() call on the execution environment. Whether the program is executed locally or on a cluster depends on the type of execution environment.
The lazy evaluation lets you construct sophisticated programs that Flink executes as one holistically planned unit.
Example Program
The following program is a complete, working example of streaming window word count application, that counts the words coming from a web socket in 5 second windows. You can copy & paste the code to run it locally.
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
To run the example program, start the input stream with netcat first from a terminal:
nc -lk 9999
Just type some words hitting return for a new word. These will be the input to the word count program. If you want to see counts greater than 1, type the same word again and again within 5 seconds (increase the window size from 5 seconds if you cannot type that fast ☺).
Data Sources
Sources are where your program reads its input from. You can attach a source to your program by using StreamExecutionEnvironment.addSource(sourceFunction). Flink comes with a number of pre-implemented source functions, but you can always write your own custom sources by implementing the SourceFunction for non-parallel sources, or by implementing the ParallelSourceFunction interface or extending the RichParallelSourceFunction for parallel sources.
There are several predefined stream sources accessible from the StreamExecutionEnvironment:
File-based:
- readTextFile(path) - Reads text files, i.e. files that respect the TextInputFormat specification, line-by-line and returns them as Strings.
- readFile(fileInputFormat, path) - Reads (once) files as dictated by
the specified file input format. - readFile(fileInputFormat, path, watchType, interval, pathFilter,
typeInfo) - This is the method called internally by the two previous
ones. It reads files in the path based on the given fileInputFormat.
Depending on the provided watchType, this source may periodically
monitor (every interval ms) the path for new data
(FileProcessingMode.PROCESS_CONTINUOUSLY), or process once the data currently in the path and exit (FileProcessingMode.PROCESS_ONCE).
Using the pathFilter, the user can further exclude files from being
processed.
IMPLEMENTATION:
Under the hood, Flink splits the file reading process into two sub-tasks, namely directory monitoring and data reading. Each of these sub-tasks is implemented by a separate entity. Monitoring is implemented by a single, non-parallel (parallelism = 1) task, while reading is performed by multiple tasks running in parallel. The parallelism of the latter is equal to the job parallelism. The role of the single monitoring task is to scan the directory (periodically or only once depending on the watchType), find the files to be processed, divide them in splits, and assign these splits to the downstream readers. The readers are the ones who will read the actual data. Each split is read by only one reader, while a reader can read multiple splits, one-by-one.
IMPORTANT NOTES:
- If the watchType is set to FileProcessingMode.PROCESS_CONTINUOUSLY,
when a file is modified, its contents are re-processed entirely.
This can break the “exactly-once” semantics, as appending data at
the end of a file will lead to all its contents being re-processed. - If the watchType is set to FileProcessingMode.PROCESS_ONCE, the source scans the path once and exits, without waiting for the
readers to finish reading the file contents. Of course the readers
will continue reading until all file contents are read. Closing the
source leads to no more checkpoints after that point. This may lead
to slower recovery after a node failure, as the job will resume
reading from the last checkpoint.
Socket-based:
socketTextStream - Reads from a socket. Elements can be separated by a delimiter.
Collection-based:
- fromCollection(Collection) - Creates a data stream from the Java
Java.util.Collection. All elements in the collection must be of the
same type. - fromCollection(Iterator, Class) - Creates a data stream from an
iterator. The class specifies the data type of the elements returned
by the iterator. - fromElements(T …) - Creates a data stream from the given sequence of objects. All objects must be of the same type.
- fromParallelCollection(SplittableIterator, Class) - Creates a data
stream from an iterator, in parallel. The class specifies the data
type of the elements returned by the iterator. - generateSequence(from, to) - Generates the sequence of numbers in the given interval, in parallel.
Custom:
- addSource - Attach a new source function. For example, to read from Apache Kafka you can use addSource(new FlinkKafkaConsumer<>(…)). See connectors for more details.
DataStream Transformations
Operators transform one or more DataStreams into a new DataStream. Programs can combine multiple transformations into sophisticated dataflow topologies.
This section gives a description of the basic transformations, the effective physical partitioning after applying those as well as insights into Flink’s operator chaining.
Map
DataStream → DataStream
Takes one element and produces one element. A map function that doubles the values of the input stream:
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
FlatMap
DataStream → DataStream
Takes one element and produces zero, one, or more elements. A flatmap function that splits sentences to words:
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)
throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
Filter
DataStream → DataStream #
Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
KeyBy
DataStream → KeyedStream #
Logically partitions a stream into disjoint partitions. All records with the same key are assigned to the same partition. Internally, keyBy() is implemented with hash partitioning. There are different ways to specify keys.
dataStream.keyBy(value -> value.getSomeKey());
dataStream.keyBy(value -> value.f0);
A type cannot be a key if:
- it is a POJO type but does not override the hashCode() method and
relies on the Object.hashCode() implementation. - it is an array of any type.
Reduce
KeyedStream → DataStream #
A “rolling” reduce on a keyed data stream. Combines the current element with the last reduced value and emits the new value.
A reduce function that creates a stream of partial sums:
keyedStream.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2)
throws Exception {
return value1 + value2;
}
});
Window
KeyedStream → WindowedStream
Windows can be defined on already partitioned KeyedStreams. Windows group the data in each key according to some characteristic (e.g., the data that arrived within the last 5 seconds). See windows for a complete description of windows.
dataStream
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)));
WindowAll
DataStream → AllWindowedStream
Windows can be defined on regular DataStreams. Windows group all the stream events according to some characteristic (e.g., the data that arrived within the last 5 seconds). See windows for a complete description of windows.
This is in many cases a non-parallel transformation. All records will be gathered in one task for the windowAll operator.
dataStream
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
Window Apply
WindowedStream → DataStream #
AllWindowedStream → DataStream #
Applies a general function to the window as a whole. Below is a function that manually sums the elements of a window.
If you are using a windowAll transformation, you need to use an AllWindowFunction instead.
windowedStream.apply(new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() {
public void apply (Tuple tuple,
Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() {
public void apply (Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
WindowReduce
WindowedStream → DataStream #
Applies a functional reduce function to the window and returns the reduced value.
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);
}
});
Union
DataStream* → DataStream
Union of two or more data streams creating a new stream containing all the elements from all the streams. Note: If you union a data stream with itself you will get each element twice in the resulting stream.、
dataStream.union(otherStream1, otherStream2, ...);
Window Join
DataStream,DataStream → DataStream
Join two data streams on a given key and a common window.
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...});
Interval Join
KeyedStream,KeyedStream → DataStream
Join two elements e1 and e2 of two keyed streams with a common key over a given time interval, so that e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound.
// this will join the two streams so that
// key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // lower and upper bound
.upperBoundExclusive(true) // optional
.lowerBoundExclusive(true) // optional
.process(new IntervalJoinFunction() {...});
Window CoGroup
DataStream,DataStream → DataStream #
Cogroups two data streams on a given key and a common window.
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...});
Connect
DataStream,DataStream → ConnectedStream #
“Connects” two data streams retaining their types. Connect allowing for shared state between the two streams.
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...
ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
CoMap, CoFlatMap
ConnectedStream → DataStream #
Similar to map and flatMap on a connected data stream
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});
Iterate
DataStream → IterativeStream → ConnectedStream #
Creates a “feedback” loop in the flow, by redirecting the output of one operator to some previous operator. This is especially useful for defining algorithms that continuously update a model. The following code starts with a stream and applies the iteration body continuously. Elements that are greater than 0 are sent back to the feedback channel, and the rest of the elements are forwarded downstream.
IterativeStream<Long> iteration = initialStream.iterate();
DataStream<Long> iterationBody = iteration.map (/*do something*/);
DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value > 0;
}
});
iteration.closeWith(feedback);
DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value <= 0;
}
});
Cache
DataStream → CachedDataStream #
Cache the intermediate result of the transformation. Currently, only jobs that run with batch execution mode are supported. The cache intermediate result is generated lazily at the first time the intermediate result is computed so that the result can be reused by later jobs. If the cache is lost, it will be recomputed using the original transformations.
DataStream<Integer> dataStream = //...
CachedDataStream<Integer> cachedDataStream = dataStream.cache();
cachedDataStream.print(); // Do anything with the cachedDataStream
...
env.execute(); // Execute and create cache.
cachedDataStream.print(); // Consume cached result.
env.execute();
Physical Partitioning
Flink also gives low-level control (if desired) on the exact stream partitioning after a transformation, via the following functions.
Custom Partitioning
DataStream → DataStream #
Uses a user-defined Partitioner to select the target task for each element.
dataStream.partitionCustom(partitioner, "someKey");
dataStream.partitionCustom(partitioner, 0);
Random Partitioning
DataStream → DataStream #
Partitions elements randomly according to a uniform distribution.
dataStream.shuffle();
Rescaling
DataStream → DataStream #
Partitions elements, round-robin, to a subset of downstream operations. This is useful if you want to have pipelines where you, for example, fan out from each parallel instance of a source to a subset of several mappers to distribute load but don’t want the full rebalance that rebalance() would incur. This would require only local data transfers instead of transferring data over network, depending on other configuration values such as the number of slots of TaskManagers.
The subset of downstream operations to which the upstream operation sends elements depends on the degree of parallelism of both the upstream and downstream operation. For example, if the upstream operation has parallelism 2 and the downstream operation has parallelism 6, then one upstream operation would distribute elements to three downstream operations while the other upstream operation would distribute to the other three downstream operations. If, on the other hand, the downstream operation has parallelism 2 while the upstream operation has parallelism 6 then three upstream operations would distribute to one downstream operation while the other three upstream operations would distribute to the other downstream operation.
In cases where the different parallelisms are not multiples of each other one or several downstream operations will have a differing number of inputs from upstream operations.
Please see this figure for a visualization of the connection pattern in the above example:
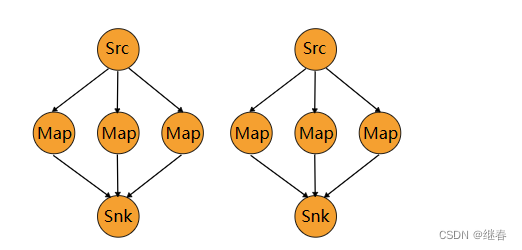
dataStream.rescale();
Broadcasting
DataStream → DataStream #
Broadcasts elements to every partition.
dataStream.broadcast();
Task Chaining and Resource Groups
Chaining two subsequent transformations means co-locating them within the same thread for better performance. Flink by default chains operators if this is possible (e.g., two subsequent map transformations). The API gives fine-grained control over chaining if desired:
Use StreamExecutionEnvironment.disableOperatorChaining() if you want to disable chaining in the whole job. For more fine grained control, the following functions are available. Note that these functions can only be used right after a DataStream transformation as they refer to the previous transformation. For example, you can use someStream.map(…).startNewChain(), but you cannot use someStream.startNewChain().
A resource group is a slot in Flink, see slots. You can manually isolate operators in separate slots if desired.
Start New Chain
Begin a new chain, starting with this operator. The two mappers will be chained, and filter will not be chained to the first mapper.
someStream.filter(...).map(...).startNewChain().map(...);
Disable Chaining
Do not chain the map operator.
someStream.map(...).disableChaining();
Set Slot Sharing Group
Set the slot sharing group of an operation. Flink will put operations with the same slot sharing group into the same slot while keeping operations that don’t have the slot sharing group in other slots. This can be used to isolate slots. The slot sharing group is inherited from input operations if all input operations are in the same slot sharing group. The name of the default slot sharing group is “default”, operations can explicitly be put into this group by calling slotSharingGroup(“default”).
someStream.filter(...).slotSharingGroup("name");
Name And Description
Operators and job vertices in flink have a name and a description. Both name and description are introduction about what an operator or a job vertex is doing, but they are used differently.
The name of operator and job vertex will be used in web ui, thread name, logging, metrics, etc. The name of a job vertex is constructed based on the name of operators in it. The name needs to be as concise as possible to avoid high pressure on external systems.
The description will be used in the execution plan and displayed as the details of a job vertex in web UI. The description of a job vertex is constructed based on the description of operators in it. The description can contain detail information about operators to facilitate debugging at runtime.
someStream.filter(...).setName("filter").setDescription("x in (1, 2, 3, 4) and y > 1");
The format of description of a job vertex is a tree format string by default. Users can set pipeline.vertex-description-mode to CASCADING, if they want to set description to be the cascading format as in former versions.
Operators generated by Flink SQL will have a name consisted by type of operator and id, and a detailed description, by default. Users can set table.optimizer.simplify-operator-name-enabled to false, if they want to set name to be the detailed description as in former versions.
When the topology of the pipeline is complex, users can add a topological index in the name of vertex by set pipeline.vertex-name-include-index-prefix to true, so that we can easily find the vertex in the graph according to logs or metrics tags.
Data Sinks
Data sinks consume DataStreams and forward them to files, sockets, external systems, or print them. Flink comes with a variety of built-in output formats that are encapsulated behind operations on the DataStreams:
-
writeAsText() / TextOutputFormat - Writes elements line-wise as
Strings. The Strings are obtained by calling the toString() method of
each element. -
writeAsCsv(…) / CsvOutputFormat - Writes tuples as comma-separated
value files. Row and field delimiters are configurable. The value for
each field comes from the toString() method of the objects. -
print() / printToErr() - Prints the toString() value of each element
on the standard out / standard error stream. Optionally, a prefix
(msg) can be provided which is prepended to the output. This can help
to distinguish between different calls to print. If the parallelism
is greater than 1, the output will also be prepended with the
identifier of the task which produced the output. -
writeUsingOutputFormat() / FileOutputFormat - Method and base class
for custom file outputs. Supports custom object-to-bytes conversion. -
writeToSocket - Writes elements to a socket according to a
SerializationSchema -
addSink - Invokes a custom sink function. Flink comes bundled with
connectors to other systems (such as Apache Kafka) that are
implemented as sink functions.Note that the write*() methods on DataStream are mainly intended for debugging purposes. They are not participating in Flink’s checkpointing, this means these functions usually have at-least-once semantics. The data flushing to the target system depends on the implementation of the OutputFormat. This means that not all elements send to the OutputFormat are immediately showing up in the target system. Also, in failure cases, those records might be lost.
For reliable, exactly-once delivery of a stream into a file system, use the FileSink. Also, custom implementations through the .addSink(…) method can participate in Flink’s checkpointing for exactly-once semantics.
Iterations
Iterative streaming programs implement a step function and embed it into an IterativeStream. As a DataStream program may never finish, there is no maximum number of iterations. Instead, you need to specify which part of the stream is fed back to the iteration and which part is forwarded downstream using a side output or a filter. Here, we show an example using filters. First, we define an IterativeStream
IterativeStream<Integer> iteration = input.iterate();
Then, we specify the logic that will be executed inside the loop using a series of transformations (here a simple map transformation)
DataStream<Integer> iterationBody = iteration.map(/* this is executed many times */);
To close an iteration and define the iteration tail, call the closeWith(feedbackStream) method of the IterativeStream. The DataStream given to the closeWith function will be fed back to the iteration head. A common pattern is to use a filter to separate the part of the stream that is fed back, and the part of the stream which is propagated forward. These filters can, e.g., define the “termination” logic, where an element is allowed to propagate downstream rather than being fed back.
iteration.closeWith(iterationBody.filter(/* one part of the stream */));
DataStream<Integer> output = iterationBody.filter(/* some other part of the stream */);
For example, here is program that continuously subtracts 1 from a series of integers until they reach zero:
DataStream<Long> someIntegers = env.generateSequence(0, 1000);
IterativeStream<Long> iteration = someIntegers.iterate();
DataStream<Long> minusOne = iteration.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value - 1 ;
}
});
DataStream<Long> stillGreaterThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value > 0);
}
});
iteration.closeWith(stillGreaterThanZero);
DataStream<Long> lessThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value <= 0);
}
});
Execution Parameters
The StreamExecutionEnvironment contains the ExecutionConfig which allows to set job specific configuration values for the runtime.
Please refer to execution configuration for an explanation of most parameters. These parameters pertain specifically to the DataStream API:
- setAutoWatermarkInterval(long milliseconds): Set the interval for
automatic watermark emission. You can get the current value with long getAutoWatermarkInterval()
Fault Tolerance
State & Checkpointing describes how to enable and configure Flink’s checkpointing mechanism.
Controlling Latency
By default, elements are not transferred on the network one-by-one (which would cause unnecessary network traffic) but are buffered. The size of the buffers (which are actually transferred between machines) can be set in the Flink config files. While this method is good for optimizing throughput, it can cause latency issues when the incoming stream is not fast enough. To control throughput and latency, you can use env.setBufferTimeout(timeoutMillis) on the execution environment (or on individual operators) to set a maximum wait time for the buffers to fill up. After this time, the buffers are sent automatically even if they are not full. The default value for this timeout is 100 ms.
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
To maximize throughput, set setBufferTimeout(-1) which will remove the timeout and buffers will only be flushed when they are full. To minimize latency, set the timeout to a value close to 0 (for example 5 or 10 ms). A buffer timeout of 0 should be avoided, because it can cause severe performance degradation.
Debugging
Before running a streaming program in a distributed cluster, it is a good idea to make sure that the implemented algorithm works as desired. Hence, implementing data analysis programs is usually an incremental process of checking results, debugging, and improving.
Flink provides features to significantly ease the development process of data analysis programs by supporting local debugging from within an IDE, injection of test data, and collection of result data. This section give some hints how to ease the development of Flink programs.
Local Execution Environment
A LocalStreamEnvironment starts a Flink system within the same JVM process it was created in. If you start the LocalEnvironment from an IDE, you can set breakpoints in your code and easily debug your program.
A LocalEnvironment is created and used as follows:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
DataStream<String> lines = env.addSource(/* some source */);
// build your program
env.execute();
Collection Data Sources
Flink provides special data sources which are backed by Java collections to ease testing. Once a program has been tested, the sources and sinks can be easily replaced by sources and sinks that read from / write to external systems.
Collection data sources can be used as follows:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// Create a DataStream from a list of elements
DataStream<Integer> myInts = env.fromElements(1, 2, 3, 4, 5);
// Create a DataStream from any Java collection
List<Tuple2<String, Integer>> data = ...
DataStream<Tuple2<String, Integer>> myTuples = env.fromCollection(data);
// Create a DataStream from an Iterator
Iterator<Long> longIt = ...;
DataStream<Long> myLongs = env.fromCollection(longIt, Long.class);
Note: Currently, the collection data source requires that data types and iterators implement Serializable. Furthermore, collection data sources can not be executed in parallel ( parallelism = 1).
Iterator Data Sink
Flink also provides a sink to collect DataStream results for testing and debugging purposes. It can be used as follows:
DataStream<Tuple2<String, Integer>> myResult = ...;
Iterator<Tuple2<String, Integer>> myOutput = myResult.collectAsync();


















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









