







参考:https://www.icourse163.org/learn/BIT-1001870001?tid=1467473478#/learn/announce
官网:https://www.crummy.com/software/BeautifulSoup/
安装
pip install beautifulsoup4
from bs4 import BeautifulSoup
使用
BeautifulSoup类
init
def __init__(self, markup="", features=None, builder=None,
parse_only=None, from_encoding=None, exclude_encodings=None,
element_classes=None, **kwargs):
"""Constructor.
:param markup: A string or a file-like object representing
markup to be parsed.
:param features: Desirable features of the parser to be
used. This may be the name of a specific parser ("lxml",
"lxml-xml", "html.parser", or "html5lib") or it may be the
type of markup to be used ("html", "html5", "xml"). It's
recommended that you name a specific parser, so that
Beautiful Soup gives you the same results across platforms
and virtual environments.
:param builder: A TreeBuilder subclass to instantiate (or
instance to use) instead of looking one up based on
`features`. You only need to use this if you've implemented a
custom TreeBuilder.
:param parse_only: A SoupStrainer. Only parts of the document
matching the SoupStrainer will be considered. This is useful
when parsing part of a document that would otherwise be too
large to fit into memory.
:param from_encoding: A string indicating the encoding of the
document to be parsed. Pass this in if Beautiful Soup is
guessing wrongly about the document's encoding.
:param exclude_encodings: A list of strings indicating
encodings known to be wrong. Pass this in if you don't know
the document's encoding but you know Beautiful Soup's guess is
wrong.
:param element_classes: A dictionary mapping BeautifulSoup
classes like Tag and NavigableString, to other classes you'd
like to be instantiated instead as the parse tree is
built. This is useful for subclassing Tag or NavigableString
to modify default behavior.
:param kwargs: For backwards compatibility purposes, the
constructor accepts certain keyword arguments used in
Beautiful Soup 3. None of these arguments do anything in
Beautiful Soup 4; they will result in a warning and then be
ignored.
Apart from this, any keyword arguments passed into the
BeautifulSoup constructor are propagated to the TreeBuilder
constructor. This makes it possible to configure a
TreeBuilder by passing in arguments, not just by saying which
one to use.
"""
example:
import requests
r = requests.get("http://python123.io/ws/demo.html")
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
属性
基本内容


遍历

下行遍历

上行遍历

平行便利

方法
prettify()
更加友好显示HTML编码
def prettify(self, encoding=None, formatter="minimal"):
"""Pretty-print this PageElement as a string.
:param encoding: The eventual encoding of the string. If this is None,
a Unicode string will be returned.
:param formatter: A Formatter object, or a string naming one of
the standard formatters.
:return: A Unicode string (if encoding==None) or a bytestring
(otherwise).
"""
example:

find_all()
def find_all(self, name=None, attrs={}, recursive=True, string=None,
limit=None, **kwargs):
"""Look in the children of this PageElement and find all
PageElements that match the given criteria.
All find_* methods take a common set of arguments. See the online
documentation for detailed explanations.
:param name: A filter on tag name.
:param attrs: A dictionary of filters on attribute values.
:param recursive: If this is True, find_all() will perform a
recursive search of this PageElement's children. Otherwise,
only the direct children will be considered.
:param limit: Stop looking after finding this many results.
:kwargs: A dictionary of filters on attribute values.
:return: A ResultSet of PageElements.
:rtype: bs4.element.ResultSet
"""
example:

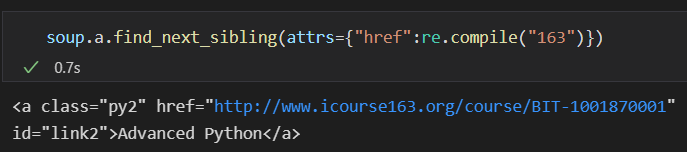
查找 拓展方法

example:















 4015
4015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









