







Spark集群是建立在hdfs分布式基础上的,首先我们准备hdfs分布式环境(zookeeper)。
1:其次我们需要下载scala,因为spark是基于scala语言编写的。
下载地址:http://www.scala-lang.org/download/2.10.4.html
2:安装和配置Scala
我们需要在SparkMaster(hadoop01)、SparkWorker1(hadoop05)以及SparkWorker2(hadoop06)上分别安装Scala
只需要配置环境变量即可:
export JAVA_HOME=/usr/local/jdk1.7.0_55
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/hadoop/hadoop-2.5.1
export SCALA_HOME=/home/hadoop/scala-2.11.7
export SPARK_HOME=/home/hadoop/spark-1.5.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH验证:

3:下载 Spark:http://www.apache.org/dyn/closer.cgi/spark
解压配置:

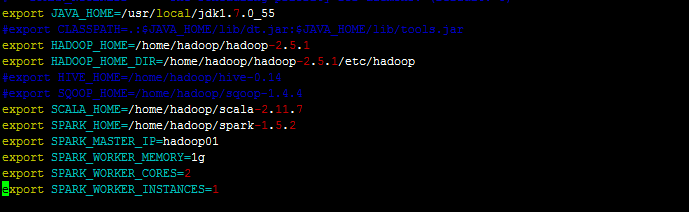
spark-env.sh配置文件:
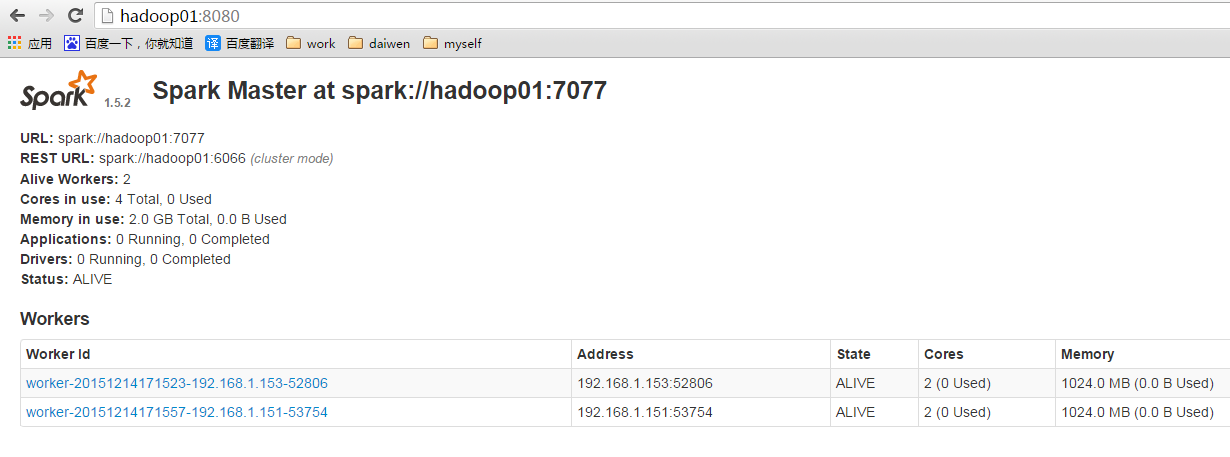
4:启动
在sbin下启动./start-all.sh















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









