






终端命令以不同模式运行Python Spark
在“终端”中以不同模式运行Python Spark程序需要输入很长的命令,例如分别以local、Hadoop YARN、和Spark Standalone模式运行Python Spark(这里以~/pythonwork/PythonProject/wordcount.py为例)每次都要输入命令:
local:cd ~/pythonwork/PythonProject
spark-submit --driver-memory 2g --master local[4] wordcount.py
Hadoop YARN:cd ~/pythonwork/PythonProject
Hadoop_CONF_DIR=/usr/local/hadoop/etc/hadoop spark-submit --driver-memory 512m --executor-cores 2 --master yarn --deploy-mode client wordcount.py
Spark Standalone:cd ~/pythonwork/PythonProject
spark-submit --master spark://master:7077 --deploy-mode client --executor-memory 500M --deploy-mode client --total-executor-cores 2 wordcount.py
Pycharm添加spark-submit外部工具
点击菜单栏“File”–>”Settings”–>”Tools”–>”External Tools”–>”+”,先设置spark-submit路径:
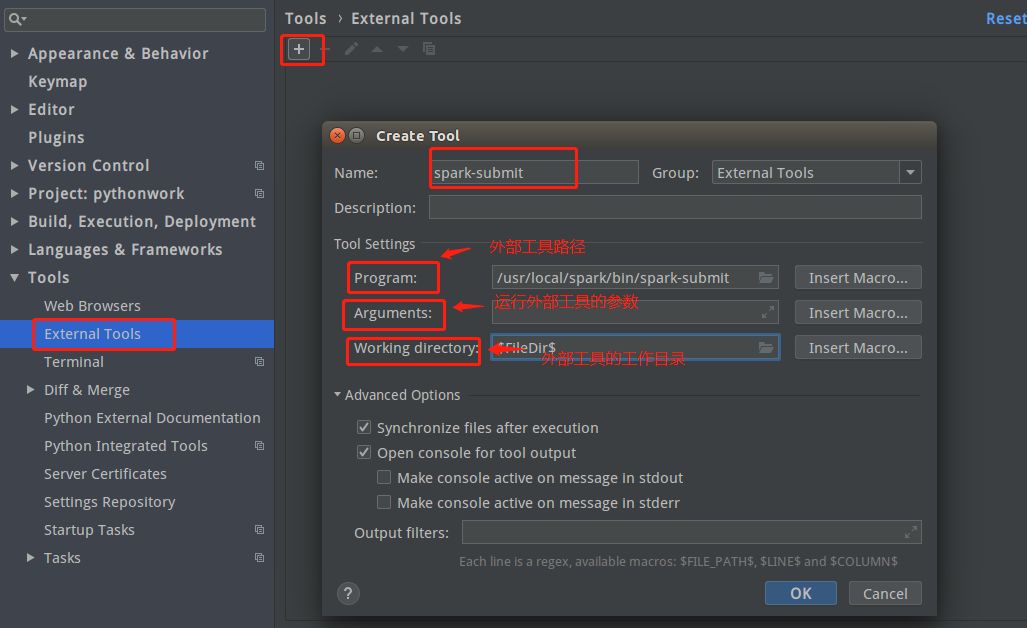
再设置运行spark-submit的参数,在”Arguments”中输入--driver-memory 2g --master local[4](具体参数值可以改变)之后,点击”Insert Macro…”,找到”Filename”并选中,下方空白出现wordcount.py,再点击“Insert”
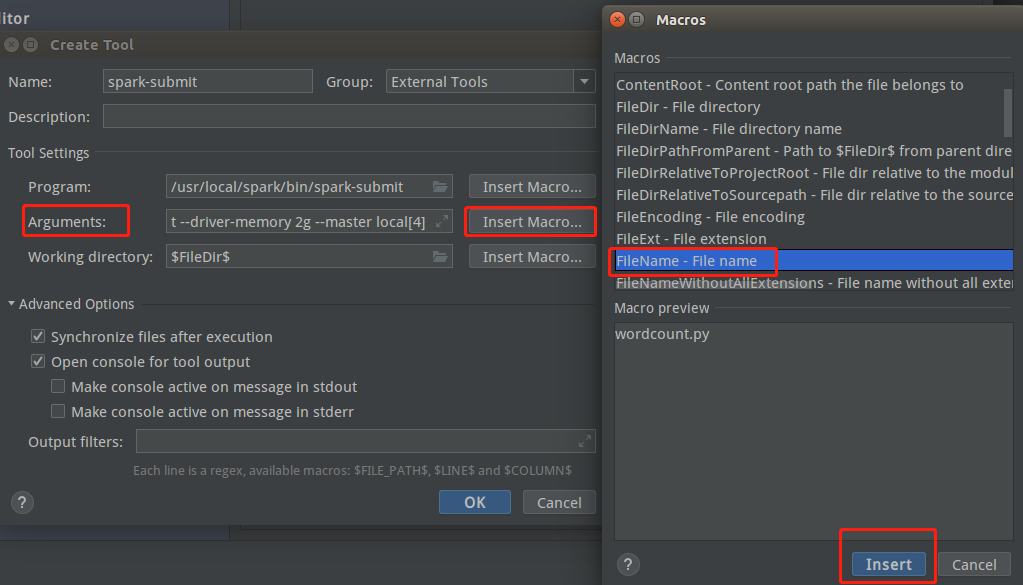
最后设置工作目录,工作目录即wordcount.py所在目录,和上面同样方法设置:
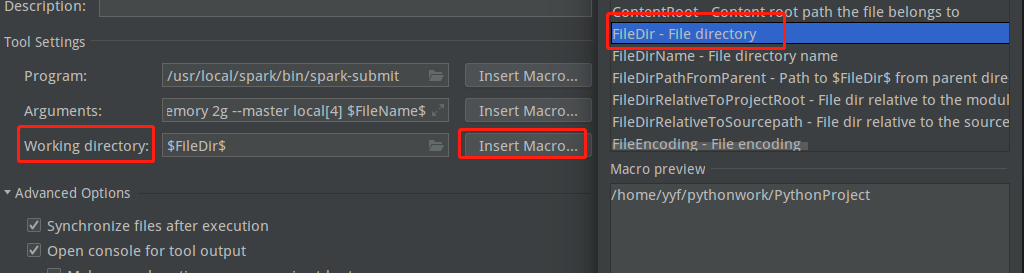
点击OK,OK设置完成。
测试设置是否成功:选中wordcount.py,点击菜单栏”Tools”–>”External Tools”,点击运行”spark submit”
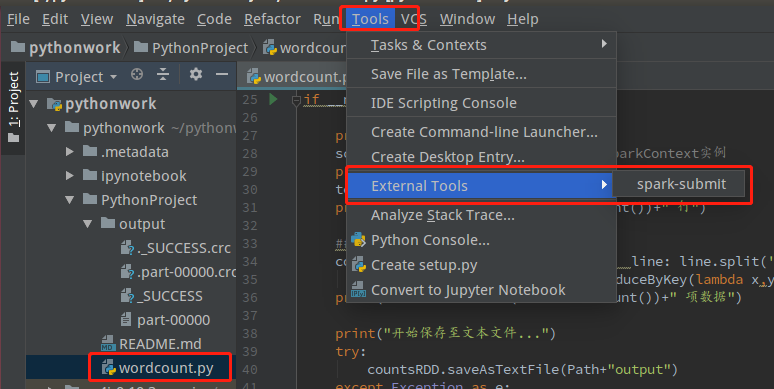
之后下方出现运行结果:
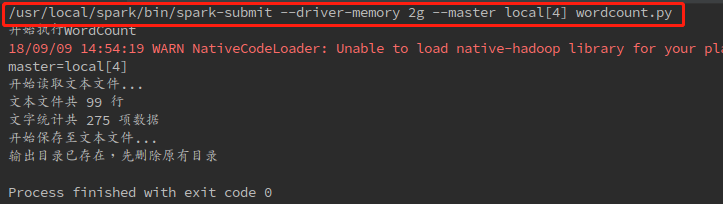
可以看到第一行显示的就是在终端运行spark-submit的所输入的命令。
Pycharm添加spark-submit yarn-client外部工具
即在Pycharm中以Hadoop YARN运行Python Spark,除了运行参数设置不同,其余和spark sumbit设置相同。
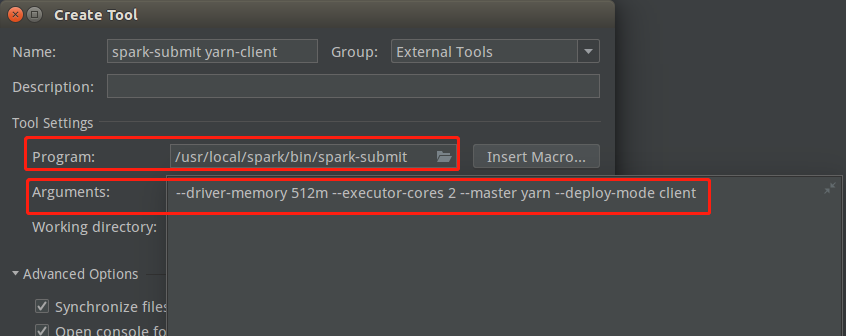
这时如果运行spark-sumbit yarn-client,可能会出现下列报错,原因在于没有配置HADOOP_CONF_DIR环境变量:
“Exception in thread “main” java.lang.IllegalArgumentException: Missing application resource.”

解决方法:在spark配置文件中的spark-env.sh加入一行:
HADOOP_CONF_DIR=/home/hadoop/hadoop-2.4.0/etc/hadoop/- 1
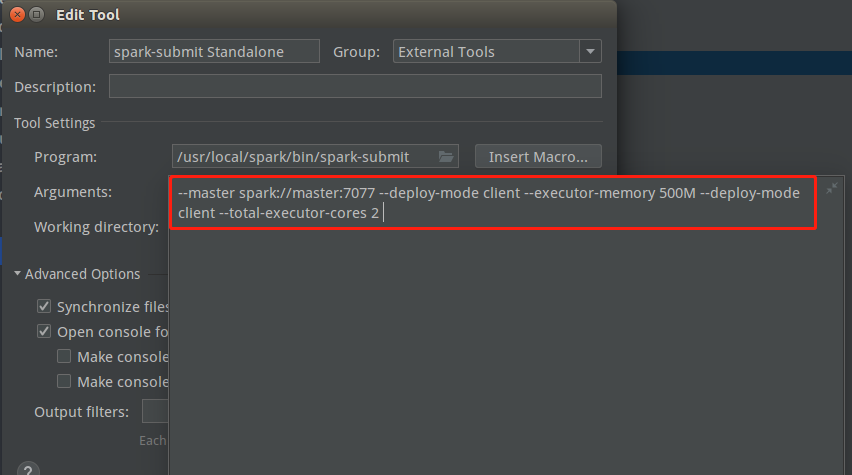
Pycharm添加spark-submit Standalone外部工具
除了参数配置不同,其他都一样:















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









