







JAVA虚拟机是理解JAVA特性、JAVA多线程编程的重要基础,这篇文章整理自:《深入理解JAVA虚拟机》。 想要通过最简单的语言让读者快速回忆起JAVA虚拟机的一些基础要点。
1 JAVA内存区域

线程共享区域
方法区:存放类信息,常量,静态变量,即时编译器编译后的代码等数据
运行时常量池:是方法区的一部分
堆:存放对象实例。(因为逃逸分析,对象不一定在堆上分配)
线程私有区域
程序计数器:存放程序计数器
虚拟机栈:局部变量,操作数栈,动态链接等
本地方法栈:与虚拟机栈类似,但是是Native方法
PS:
注意和JMM所区别,JMM和上面的内存是不同级别的划分,是没有关系的。
JMM关注的是共享内存和工作内存,即线程共享的内存(不包含本地量)。
2 对象创建的过程
1. 遇到一个new指令后,先去常量池定位到一个类的符号引用,检查这个符号引用代表的类是否已经被加载,解析和初始化过,如果没有,先执行类加载过程
2. 类加载检查通过后,为新生对象分配内存
3. 内存分配完成后,将分配到的内存空间都初始化为零值(保证实例变量不赋值也能直接使用)
4. 配置对象(比如这个对象是哪个类的实例,如何才能找到类的元数据信息)。
5. 执行程序员的初始化代码
3. 类加载过程
1. 装载:导入class文件
2. 连接
a. 验证:检查class文件正确性
b. 准备:给类中的静态变量分配存储空间并且设置初始零值(但被final修饰的时候直接初始对应值)
c. 解析:将符号引用转化为直接引用(可选)
3. 初始化:对静态变量和静态代码块执行初始化工作(静态变量的初始化,静态代码块的执行等)
4. 使用
5. 卸载
4 判断对象生存状态的算法
1. 引用计数算法
给对象添加一个计数器,每当有地方引用它的时候,计数器加一。但容易死锁
2. 可达性分析:(大部分JAVA虚拟机使用的)
从GC root追踪对象,若不可达,则判断为死亡,常见GC root 包括
a. 虚拟机栈中的对象
b. 方法去中静态属性引用的对象
c. 方法去中常量引用的对象
d. 本地方法栈中JNI(native方法)引用的对象
5 对象被回收过程
1. 判断对象不可达,进入下一步
2. 筛选:
a. 没有finalize()方法或者已经执行过一次finalize()方法,直接回收
b. 有finalize方法并且未执行过,进入第3步
3. 将对象置于F-Queue中。让虚拟机一个低优先级的Finalizer线程去执行它,这里所谓的“执行”只是虚拟机会触发这个方法,但不承诺等它结束。之后GC会再次标记这个队列的对象,如果没有在finalize里重新链接,则回收。
关于finalize方法:
JAVA不鼓励使用finalize方法,因为它不能保证被执行,不能保证被执行完毕,而且代价高昂。
6 GC算法
1. 标记-清除(mark-sweep)
先标记所有要回收的,再清除。
优点:是最基本的回收算法
缺点:1.标记清除过程效率不高 2.产生大量内存碎片
2. 复制(copying)
把内存分两份,每次只使用一块,当一块用完时,复制到另一块上再清空
优点:1.不必考虑内存碎片 2.只要移动堆顶指针,按顺序分配,简单高效
缺点:1. 浪费内存 2. 对象存活率较高的时候需要过多操作 3.如果不使用50%对分策略,老年代需要空间担保策略
3. 标记-压缩(mark-compact)
标记完了之后,向一端compact内存
4. 分代(generation collecting):
a. 新生代: 复制算法
b. 老年代:标记-清理 或者 标记-整理
7 新生代中Copying算法

在copying算法中不一定非要对半分, 新生代中98%的对象都是朝生夕死,所以将内存划分为一块Eden和两块survivor。
每次只使用Eden空间+1块survivor,回收的时候把所有存活对象复制到另一块survivor中。再清空。
这样有个问题,就是当一个survivor不够放下所有存活对象的时候,需要依赖其他内存(这里指老年代)进行内存担保。
8 Stop-the-world 垃圾收集器
Stop-the world从应用中停下来进入到GC执行过程中去。一旦Stop-the-world发生,除了GC所需要的线程外,其他线程都将停止工作,中断了的线程直到GC任务结束才继续它们的任务。GC调优通常是为了改善Stop-the-world的时间。
根据不同的代,有不同的垃圾收集器:
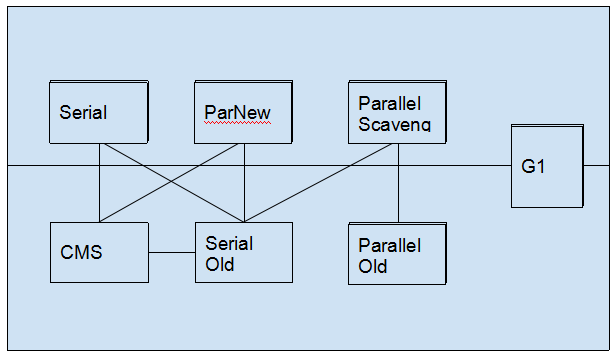
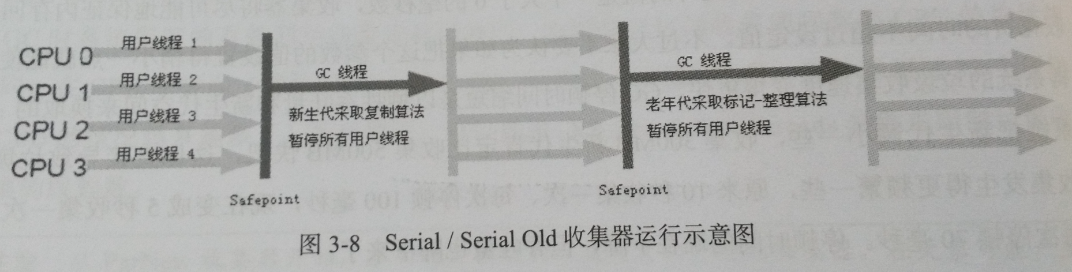
Serial:
过程:采用复制算法,采用单线程,停下所有工作来进行GC
优点:简单而高效,没有多线程的开销
缺点:停顿
适用:对运行在client模式下的虚拟机来说是一个很好的选择(如用户桌面应用场景中,分配给新生代的内存至多几百兆)
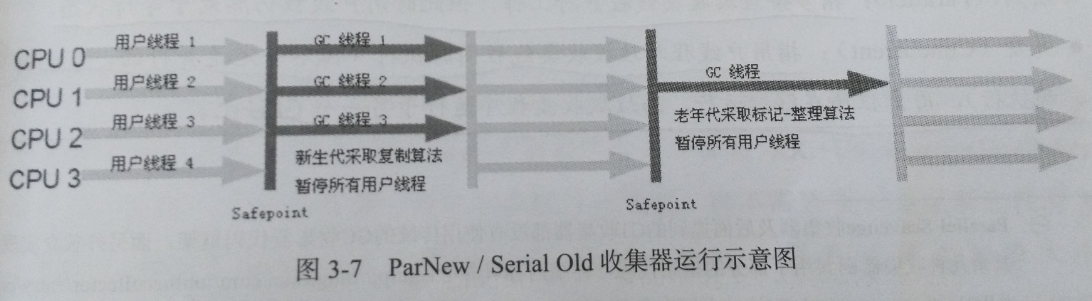
ParNew:
过程:采用复制算法,Serial的多线程版本。
优点:并发执行,除了Serial外,只有它能和CMS配合工作
缺点:当CPU数目不多时候,开销过大
适用:Server模式
Parallel Scavenge:
过程:采用复制算法,“吞吐量优先”收集器,
优点:为高吞吐量设计(少考虑交互延迟,多考虑利用CPU)
缺点:交互延迟
适用:后台计算而不需要太多的交互任务

Serial Old:
过程:采用标记-整理算法,单线程
主要意义:在client模式下使用,或者作为CMS的后备
Parallel Old:
过程:采用标记-整理算法,多线程
适用:可以跟parallel scavenge配合使用,“吞吐量优先”
CMS:
过程:采用标志-清除算法
● 初始标记:stop-the-world 标记一下GC root能直接关联到的对象,速度很快
● 并发标记:GC root tracing
● 重新标记:stop-the-world 修正并发标记时出现的变化
● 并发清除:清除
优点:避免了耗时最长的两个过程的停顿,注重响应速度
缺点:1. 耗费CPU。 2. 无法处理浮动垃圾,老年代空间使用率低。 3. 空间碎片

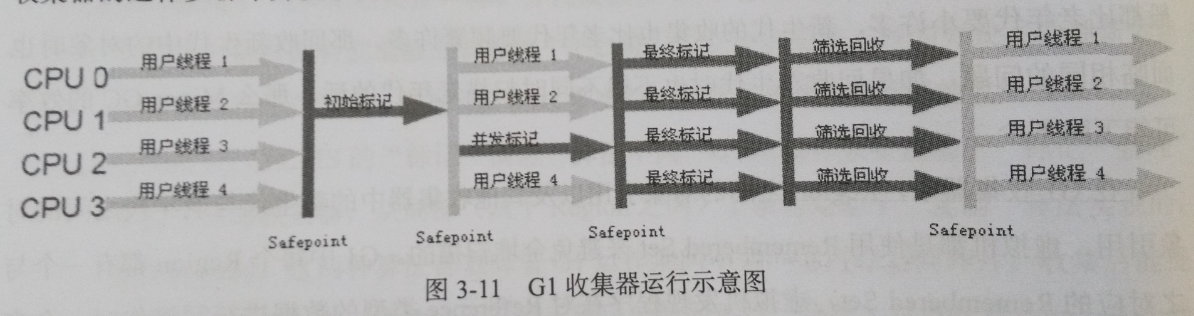
G1:
过程:新生代和老年代不再物理隔离,并行和并发,分带收集,整体采用“标记-整理”(部分采用复制),可预测的停顿时间模型(有计划地避免全区域垃圾收集)。 G1 跟踪各个Region里面垃圾堆积的价值大小,在后台维护一张优先列表,每次根据允许的收集时间,有限回收价值最大的Region。
● 初始标记
● 并发标记
● 最终标记
● 筛选回收















 2429
2429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









