









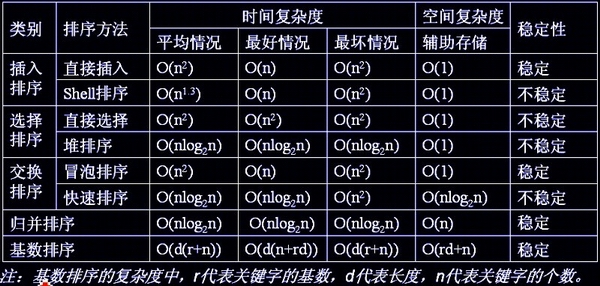
排序算法有非常多,主要包括:选择排序、插入排序、冒泡法、归并排序、快速排序、堆排序、计数排序、基数排序、桶排序
In-place sort(不占用额外内存或占用常数的内存):插入排序、选择排序、冒泡排序、堆排序、快速排序。
Out-place sort:归并排序、计数排序、基数排序、桶排序。
稳定排序:相等元素的相对顺序始终不会发生改变
stable sort:插入排序、冒泡排序、归并排序、计数排序、基数排序、桶排序。
unstable sort:选择排序、快速排序、堆排序。
选择排序(In-place、unstable )
每次找到剩余数组中的最小值,交换至剩余待排元素的起始位置
时间复杂度始终为O(n^2)
void select_sort(vector<int>& nums){
for(int i=0;i<nums.size()-1;++i){
int min=i;
for(int j=i+1;j<nums.size();++j){
if(nums[j]<nums[min])
min=j; //记录所有剩余元素中最小值的下标
}
swap(nums[i],nums[min]); //将最小值交换到起始位置
}
} 插入排序(In-place、stable )
每次要插入一个元素时,该元素前面的所有元素已经排好序。因此插入排序就是将元素插入到前面已排好序的序列中的合适位置上去
时间复杂度O(n^2),当数组已经有序时,可降为O(n)
void insertSort(vector<int>& nums){
for(int i=1;i<nums.size();++i){
int num=nums[i];
int j=i-1;
while(j>=0&&nums[j]>num){ //向前查找,找到最合适的位置插入a[i]
nums[j+1]=nums[j];
--j;
}
nums[j+1]=num;
}
} 归并排序(Out-place、stable )
将两个有序表合并成一个新的有序表,然后递归向上合并,直到整个数组有序
时间复杂度O(nlgn),最佳和最坏都是O(nlgn)
空间复杂度O(n)
void merge(vector<int>& nums,int start,int end,int mid,vector<int>& temp){
int i=start,j=mid+1;
int k=start;
while(i<=mid&&j<=end){
if(nums[i]<=nums[j]){
temp[k++]=nums[i++];
}else{
temp[k++]=nums[j++];
}
}
while(i<=mid) temp[k++]=nums[i++];
while(j<=end) temp[k++]=nums[j++];
for(int i=start;i<=end;++i){
nums[i]=temp[i];
}
}
void mergeSort(vector<int>& nums,int start,int end,vector<int>& temp){
if(start>=end) return;
int mid=start+(end-start)/2; //不断二分,递归进行归并排序
mergeSort(nums,start,mid,temp); //左边有序
mergeSort(nums,mid+1,end,temp); //右边有序
merge(nums,start,end,mid,temp); //合并左右两部分
} 快速排序(In-place、unstable )
选择一个基准元素,使得一趟排序后,所有比基准元素小的都在其左边,所有比基准元素大的都在其右边。
时间复杂度O(nlgn),在最坏情况会退化为O(n^2)
当数组中元素随机时,效率最佳。
/* 快速排序的代码非常简单,首先调用partion过程,得到主元元素在一次排序后的下标,然后对左、右子数组分别递归调用quick_sort() */
void quick_sort(vector<int>& nums,int start,int end){
if(start<end){
int mid=partion2(nums,start,end);
quick_sort(nums,start,mid-1);
quick_sort(nums,mid+1,end);
}
}
/*可以发现快速排序的关键是partion过程,partion过程可以通过多种不同的方法实现 */
int partion(vector<int>& nums,int start,int end){ //算法导论上的方案,以末尾元素作为主元,从左到右进行调整
int pivot=nums[end];
int j=start-1;
for(int i=start;i<end;++i){
if(nums[i]<=pivot){
++j;
swap(nums[i],nums[j]);
}
}
swap(nums[j+1],nums[end]);
return j+1;
}
int partion2(vector<int>& nums,int start,int end){ //另一种解法:挖坑填数
int pivot=nums[start];
int i=start,j=end;
while(i<j){
while(i<j&&nums[j]>=pivot) --j;
if(i<j){
nums[i]=nums[j];
++i;
}
while(i<j&&nums[i]<pivot) ++i;
if(i<j){
nums[j]=nums[i];
--j;
}
}
nums[j]=pivot;
return j;
}
int partion3(vector<int>& nums,int start,int end){ //另一种更简单的解法:找到左右不符合条件的元素,交换
int pivot=nums[start];
int i=start,j=end;
while(i<j){
while(i<j&&nums[j]>=pivot) --j;
while(i<j&&nums[i]<=pivot) ++i;
if(i<j){
swap(nums[i],nums[j]);
}
}
swap(nums[start],nums[i]);
return i;
} 堆排序(In-place sort、unstable sort)
可以采用大根堆进行堆排序
时间复杂度始终为O(nlgn)
堆排序在海量数据处理中使用得非常多:
如在10亿个元素中查找其中最大的前100个,可以通过维护一个100个元素小根堆来实现。
当新读出的元素比根节点元素大时,则替换根节点,并调整堆。
桶排序(out-place sort、stable sort)
将数组中的全部元素按照规则分配到不同的桶中去,然后再对每个子桶进行排序
最佳情况,每个桶中最多只有一个元素,这样一趟排序就能完成,时间复杂度为O(n)
但是如果所有元素都落入同一个桶中,则时间复杂度退化为O(n^2)
如果对子桶的排序选择归并、快排等算法,时间复杂度为O(nlgn)
主要应用:海量数据查找中位数
假设有10亿个整数,查找其中位数
整数有4个字节32bit,首先可以将最高位的1个字节8bit作为每个桶的key,这样就需要256个桶。
1) 依次读入每个元素,根据最高字节得到对应的桶,然后统计每个桶中元素的个数
2) 中位数为第5亿个元素,因此找到第5亿个元素对应的桶。
如前120个桶中所有元素总个数为4亿3千万,前121个桶中元素总个数为5亿1千万,则第5亿个元素一定在第121个桶中。由于前120个桶已有4亿3千万个元素,因此查找第121个桶中的第7千万个元素即为第5亿个元素,即为中位数。
3) 由于第121个桶中元素的最高字节都是相同的,因此可以采用同样的方法,以第二个字节作为key,继续对第121个桶中的8千万个元素进行桶排序。依次进行下去,直到找到目标元素。















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









