







操作系统:64位Ubuntu14.04
hadoop安装路径:/usr/local
一、在Eclipse下配置Hadoop插件:
1. Hadoop2.2.0还算比较新的,hadoop安装目录里还没有配套的Eclipse插件。可直接把附件中的hadoop-eclipse-kepler-plugin-2.2.0.rar解压后放到eclipse安装目录下的plugins目录中。
2.重启eclipse,如果安装插件成功,打开Window–>Preference,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。本例为/usr/local/hadoop,配置完成后保存退出。
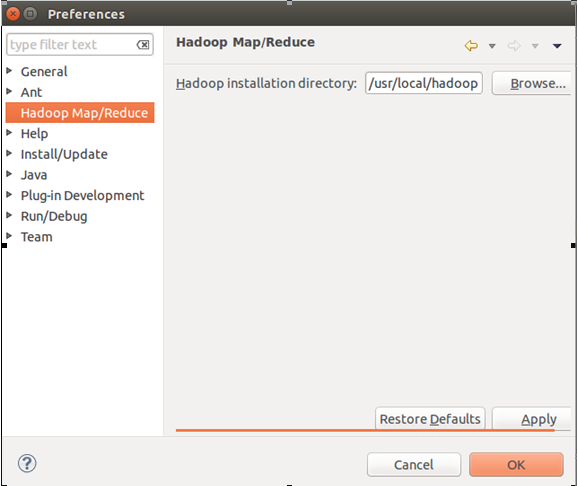
3.在Windows -> Open Perspective ->Other里,选择蓝大象Map/Reduce
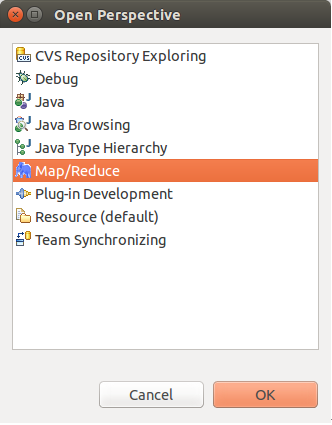
4. 在Windows -> Show View -> Other里,选择MapReduce Tool ->Map/Reduce Location
5. 在窗口下方出现的黄大象Map/Reduce Location空白处,右击选择New Map/Reduce Location
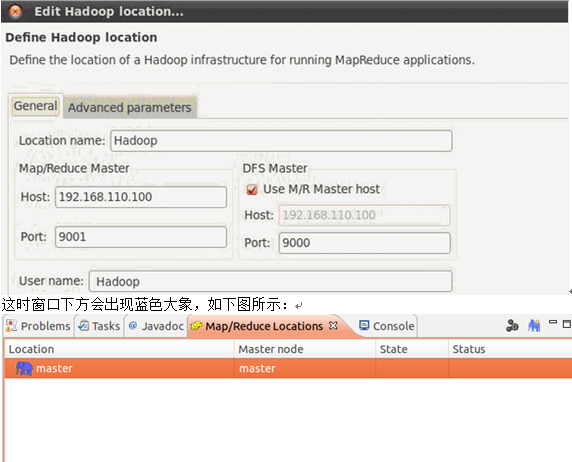
6. 在弹出来的对话框里,根据core-site.xml 和 mapred-site.xml里的地址和端口号,进行填写,其中Location name 任意,这里选hadoop
Map/Reduce Master和DFS Master里面的Host、Port分别为在mapred-site.xml、core-site.xml中配置的地址及端口。User name是搭建Hadoop集群时所用的用户名,我这里用的是hadoop。
两个文件的配置如下:
mapred-site.xml:
mapred.job.tracker
master:9001
core-site.xml
fs.default.name
hdfs://master:9000
(master是搭建hadoop时主节点的机器名)
7. 在窗口左侧试图的Project Explorer里,点击DFS Location,就会出现HDFS的目录级, 能够浏览hadoop集群上的目录文件信息,则配置成功
二、新建项目
File–>New–>Other–>Map/Reduce Project (项目名可以随便取,这里取wordCount )
复制 hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java到刚才新建的项目中
三,上传模拟数据文件夹
首先启动hadoop集群:
cd /usr/local/hadoop
sbin/start-all.sh
注意启动hadoop集群后datanode(子节点)要离开安全模式,否则不能成功上传文件。
./bin/hdfs dfsadmin –safemode leave
为了运行程序,我们需要一个输入的文件夹,和输出的文件夹。输出文件夹在程序运行完成后会自动生成。我们只需要给程序一个输入文件夹。
1.在当前目录(如hadoop安装目录)下新建文件夹input,并在文件夹下新建两个文件file01、file02,随意输入一些内容:
file01:

file02:

2.将文件夹input上传到分布式文件系统中。
bin/hdfs fs –put input input
(第二个input是文件名)
这个命令将input文件夹上传到了hadoop文件系统了,在该系统下就多了一个input文件夹,你可以使用下面命令查看:
bin/hdfs fs –ls /
也可以在窗口左侧的视图里查看
四、运行项目
1.在新建的项目hadoop-test,点击WordCount.java,右键–>Run As–>Run Configurations
2.在弹出的Run Configurations对话框中,点Java Application,这时会出现一个application名为wordCount
3.配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:
这里面的input就是你刚传上去文件夹。文件夹地址你可以根据自己具体情况填写。
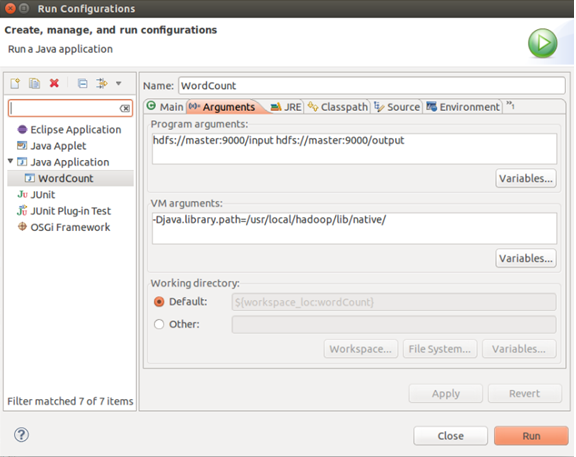
4.右键Run on hadoop,运行程序。

(图中的警告是由hadoop2.2.0与64位操作系统不兼容引起的)
刷新窗口左侧视图中的文件夹
会出现hadoop文件系统中存放的input文件以及运行后输出的output文件,output文件内容如下:
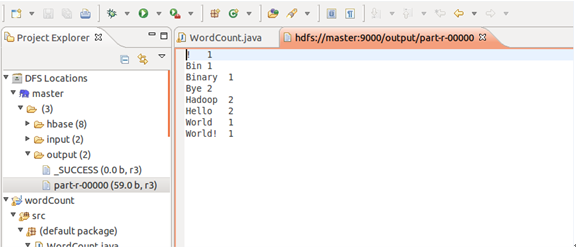
注意反复运行该程序需要删除output文件,否则会报output文件已存在的错。















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









