







一、消息中间件
官方解释:消息中间件利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程间的通信。
说白了就是在分布式中进行消息的收发和处理的,但是为什么用,怎么用,用来解决什么问题
二、使用场景
版本:kafka2.10
简易架构:一般消息中间件有三大模块,producer(消息生产),broker或者叫Queue(消息存放),consumer(消息消费)如下图

一般情况下producer和consumer在两个不同系统A和B,A系统生产消息,并把消息存放到broker中,B系统消费存放在
Broker上的消息信息,乍一看跟系统之间RPC调用没什么区别,都是为了系统间通信,相对于RPC调用优势在哪里
1.异步处理:貌似RPC调用也可以实现异步调用的功能,但是RPC调用的异步处理跟消息中间件还是有很大的区别的
rpc异步调用后,当前系统对是否通信成功并无感知(是否通信成功也可以理解为消息是否已达),也许因为网络原
因,异步的消息并没有发送到其他系统;针对这一点消息中间件对消息做了改善,比如说持久化,接下来会以
kafka讲解支持消息重试
2.流量控制:系统的流量受到时间,季节,天气,节日等因素的影响,流量并不是均匀的,比如说11.11,流量会很大,
如果所有流量全都直接打到底层系统,甚至到数据库,那么系统很有可能会挂掉,这时候消息中间件的作用就
体现出来了所有消息先存到broker上,consumer根据自己的消费能力处理broker的消息
3.服务解耦:电商项目中很多系统一般都会订单感兴趣,订单创建,完成,取消或退回,如果没有消息中间件,那么每
个订单的创建都要通知到对订单创建感兴趣的系统,这样各个系统都会耦合到一块,增加了系统的复杂度;但是
如果通过消息中间件实现,订单创建后消息保存到消息中间件,对订单感兴趣的系统订阅这个消息,然后处理自
己系统的逻辑很大程度上降低了系统的耦合度
整体来说消息中间件具有以上三大优势,可以根据具体的业务场景分析,是否应该接入;不过不同的消息中间件也会提
供一些特殊的功能,比如事务,通过消息中间件的事务来保证系统数据的最终一致性,对于系统的性能及吞吐量都有很
大的提升目前支持事务的消息中间件有RocketMq和老牌ActiveMq都是apache下的产品,本文要讲的kafka并不支持事务
三、kafka的优势
1.高吞吐量:据说 每秒可以生产约 25 万消息(50 MB),每秒处理 55 万消息(110 MB)
在消息只支持持久化模式下能达到这么高的吞吐量已经相当可观了
2.高可用性:kafka只支持数据持久存储,并且可以灵活配置数据备份模式及应答模式,有很高的可用性
3.高可扩展性:kafka基于zookeeper的,broker可以灵活扩展
4.消息被处理在consumer维护,而不是在server端,消费失败可以灵活处理
四、kafka架构及使用
简单了解一下kafka的架构:
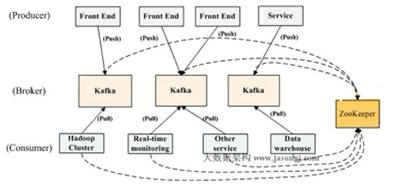
producer:消息生产方,直接与broker进行连接;只需要连接到一台broker上,就可以获得整个集群的broker信息,并
缓存在系统本地;并且定期更新缓存,防止broker挂掉系统无感知;生产消息到broker采用push的方式
consumer:消息消费方,kafka采用pull的模式消费topic
优点:可以根据自身系统的消费能力拉取并消费信息;相比于push方式来说,可以避免消息的丢失
缺点:需要实时关注broker中是否有消息产生
broker:消息存储,并且把自身的信息注册到zookeeper上
topic:主题,消息发送和消息接收指定的消息的主题,可以存在于多个broker上,但是一个消息只会存在一台broker上
partitions:消息分区,在磁盘上表现为一个文件夹,一个topic可以有多个partitions,并每一个partitions存放的数据是
互斥的,一个partitions只存在于一个broker上;一般会均匀的分布在不同broker上
segment:消息片,在磁盘上表现为一个文件,在partitions文件夹下,存放消息数据
replica:消息副本,对应于partitions,作为消息的备份出现,可配置数量;一般会均匀的分布在不同broker上















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









