







本文参考http://slaytanic.blog.51cto.com/2057708/1162287,感觉本地编译较为麻烦,所以总结了再Ubuntu上比较简洁快速的方式。
关于lzo压缩与gzip、bzip2要所的异同优劣请查阅其他文档,本文只做配置。
前提,假定所有hadoop节点都已部署完成,ant、maven、git都已安装完成并可用。
1、2步骤需要在所有Hadoop节点进行 3、4步骤修改完之后也需要同步到所有hadoop节点。
1.安装LZO库(动态链接文件),第二步依赖本步骤
sudo apt-get install liblzo2-dev2.安装lzop(解压缩lzo文件的工具,也就是我们的主角)
sudo apt-get install lzop至此可以再本地解压缩lzo文件
3.本地编译hadoop-lzo -xxx.jar,及native文件
如果找到已经编译好的jar包,native文件可直接使用(具体使用见步骤4)
check源码,建议使用twitter的源码。地址为https://github.com/twitter/hadoop-lzo.git
git clone https://github.com/twitter/hadoop-lzo.git hadoop-lzoclone完成后进入hadoop-lzo目录,并修改pom文件
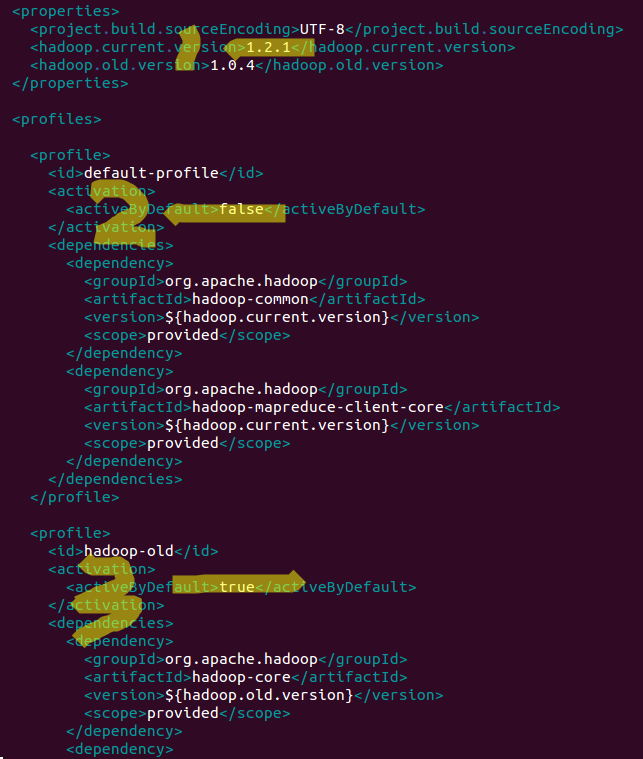
因为我用的hadoop版本是1.2.1,所以再1\2\3处进行了修改
修改处未你当前使用的hadoop版本,如有需要请提前将对应hadoop集群的jar包(hadoop-core-xxx,jar)install至你的本地repositry活deploy至nexus
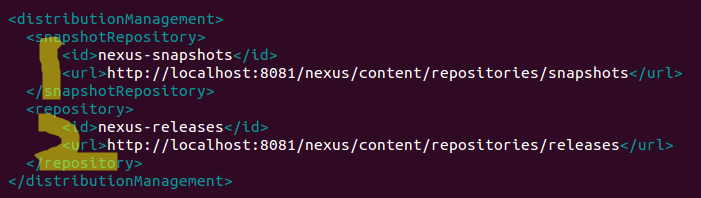
修改nexus两个库的地址
以上完成之后进行编译
mvn install 或 mvn deploy完成之后拷贝jar包及native库到各hadoop节点
cp hadoop-lzo-xxx.jar $HADOOP_HOME/libcp -R native $HADOOP_HOME/lib/native接着scp至所有hadoop节点,scp命令格式
scp localfile username@remotehost:/remotedir
4.修改配置文件
core-site.xml添加:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
mapred-site.xml添加:
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>mapred.child.env</name>
<value>LD_LIBRARY_PATH=/home/john/dev/hadoop-1.2.1/lib/native/Linux-amd64-64</value>
</property> 修改完成后scp至所有hadoop节点,重启。
5.测试
我下了个某网站的帐号及密码文件,此处文件随便找个就ok,行内内容用tab建分割。
1.压缩并put进hdfs
a.压缩
lzop userpass.txt
此时会生成userpass.txt.lzo文件
将该文件put进hadoop目录
b.put进hdfs
hadoop fs -put /aaa/aaa/userpass.txt.lzo /data/input/renren
c.创建索引
hadoop jar $HADOOP_HOME/lib/hadoop-lzo.jar com.hadoop.compression.lzo.DistributedLzoIndexer /data/input/renren/userpass.txt.lzo
2.修改Hadoop的例子WordCount(可去hadoop目录下的example中找代码)
将FileInputStream替换为DeprecatedLzoTextInputFormat
3.执行
具体执行略。















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









