







首先需要配置环境
yum -y install lzo-devel zlib-devel gcc autoconf automake libtool
下载lzo包
wget www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz
解压
tar -zxvf lzo-2.06.tar.gz -C ~/app
然后进入到目录中执行以下操作
export CFLAGS=-m64
mkdir complie
./configure -enable-shared -prefix=/home/hadoop/app/lzo-2.06/complie/
make && make install
成功后进入到complie中查看文件

安装Hadoop-lzo
下载
wget https://github.com/twitter/hadoop-lzo/archive/master.zip
然后解压
unzip master
进入到hadoop-lzo-master中修改pom.xml文件,让其对应Hadoop版本
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.current.version>2.6.0</hadoop.current.version>
<hadoop.old.version>1.0.4</hadoop.old.version>
</properties>
然后执行以下命令
export CFLAGS=-m64
export CXXFLAGS=-m64
export C_INCLUDE_PATH=/home/hadoop/app/lzo-2.06/complie/include/ //这里需要提供编译好的lzo的include文件
export LIBRARY_PATH=/home/hadoop/app/lzo-2.06/complie/lib/ //这里需要提供编译好的lzo的lib文件
然后开始编译
mvn clean package -Dmaven.test.skip=true
接下来执行
cd target/native/Linux-amd64-64
tar -cBf - -C lib . | tar -xBvf - -C ~
cp ~/libgplcompression* $HADOOP_HOME/lib/native/
到hadoop-lzo-master下把jar包导入Hadoop中
cp target/hadoop-lzo-0.4.21-SNAPSHOT.jar $HADOOP_HOME/share/hadoop/common/
cp target/hadoop-lzo-0.4.21-SNAPSHOT.jar $HADOOP_HOME/share/hadoop/mapreduce/lib
接下来修改配置文件
再Hadoop的etc/hadoop/hadoop-env.sh中添加lib包地址
export LD_LIBRARY_PATH=/home/hadoop/app/lzo-2.06/complie/lib
在core-site.xml,添加
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
在mapred-site.xml,添加
<property>
<name>mapred.child.env </name>
<value>LD_LIBRARY_PATH=/home/hadoop/app/lzo-2.06/complie/lib</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
然后重启Hadoop
之后就可以尝试使用lzo压缩了
这里我准备了一份数据
使用lzo压缩
lzop access_2013_05_30_2.log
对比大小

然后将数据上传到HDFS中
hadoop fs -put access_2013_05_30_2.log.lzo /data
查看数据

然后利用Hadoop自带的wordcount实验一下
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /data/access_2013_05_30_2.log.lzo out
然而发现一个问题,那就是分片只有一片
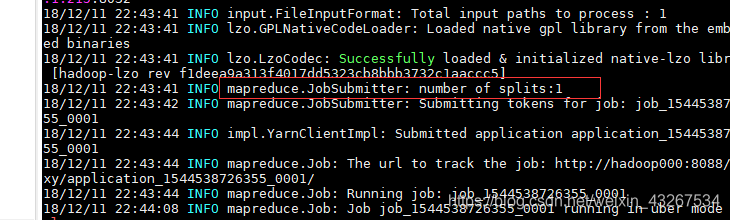
所以我们要把文件简历索引
hadoop jar hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /data/access_2013_05_30_2.log.lzo
注意位置,我是在lib下直接编译的,别忘了指定jar包位置

然后运行
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /data/access_2013_05_30_2.log.lzo /out















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









