









2月27日是 DeepSeek 开源周的第四天,连更三个项目,即两个工具和一个数据集:DualPipe、EPLB 以及来自训练和推理框架的分析数据。
-
DualPipe:一种用于 V3/R1 模型训练中实现计算 - 通信重叠的双向 pipeline 并行算法。
-
EPLB:一个为 V3/R1 打造的专家 - 并行负载均衡器。
-
训练和推理框架的分析数据:为了帮助社区更好地理解通信 - 计算重叠策略和底层实现细节。

-
DualPipe 链接:https://github.com/deepseek-ai/
-
DualPipeEPLB 链接:https://github.com/deepseek-ai/eplb
-
计算分析链接:https://github.com/deepseek-ai/profile-data
1 DualPipe
DualPipe 是 DeepSeek-V3 技术报告中提出的一种创新的双向流水线并行算法。它实现了前向和后向计算 - 通信阶段的完全重叠,同时减少了流水线气泡。
有网友制作了 DualPipe 与其他两种方法 ——1F1B and ZB1P 的对比图,如下所示,展示了 DualPipe 在 8 个流水线并行(PP)阶段和 20 个双向 micro-batches 情况下的调度。反向的 micro-batch 与前向的 micro-batch 对称,因此图中省略了它们的 batch ID。
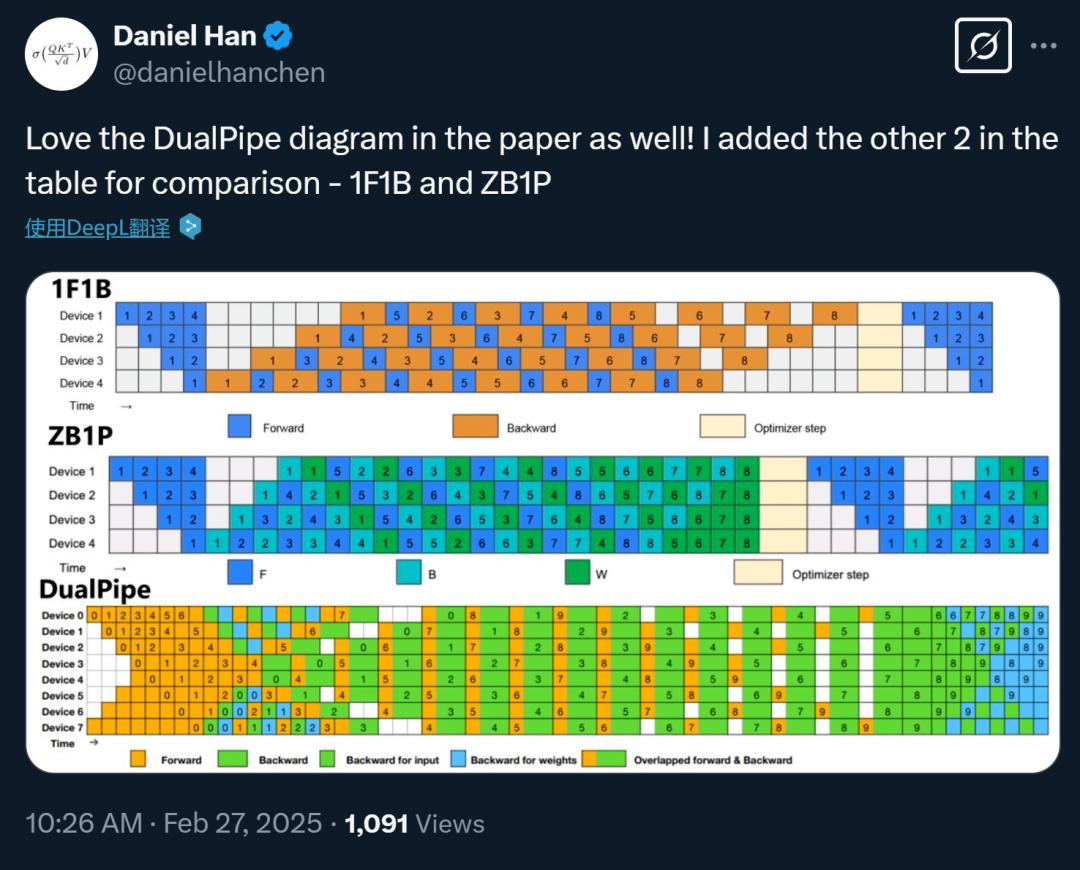
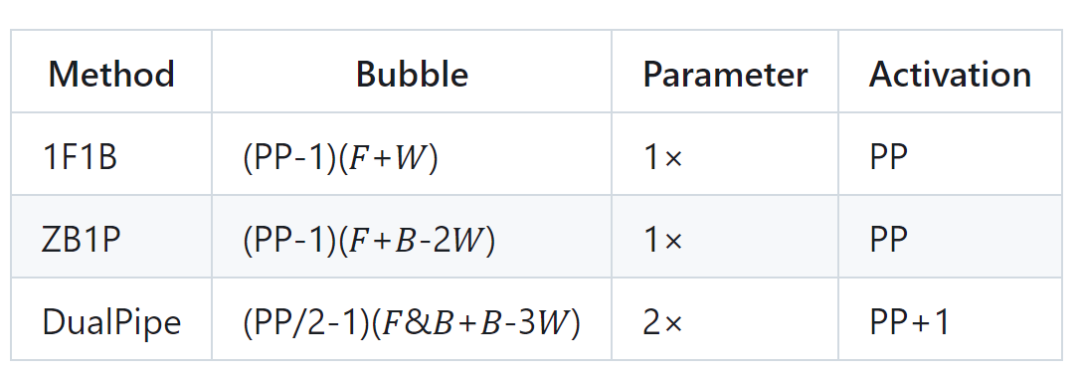
流水线气泡与内存使用情况比较:
-
𝐹 :表示前向数据块(forward chunk)的执行时间,
-
𝐵 :表示完整后向数据块(full backward chunk)的执行时间,
-
𝑊 :表示「权重后向」(backward for weights)数据块的执行时间,
-
𝐹&𝐵:表示两个相互重叠的前向和后向数据块的执行时间。
值得一提的是,在 DualPipe 的 GitHub 上,DeepSeek 创始人梁文锋位列开发者行列之中。

2 EPLB
在使用专家并行(Expert Parallelism,EP)时,不同的专家会被分配到不同的 GPU 上。由于各个专家的计算负载会随当前任务而变化,因此保持各 GPU 间负载均衡至关重要。
DeepSeek-V3 论文中有提到,研究人员采用了冗余专家(redundant experts)策略,复制高负载的专家。然后,DeepSeek 通过启发式算法将这些复制的专家打包到 GPU 上,以确保不同 GPU 之间的负载平衡。
为了便于复现和部署,DeepSeek 在 eplb.py 中开源了部署的 EP 负载平衡算法。该算法根据估计的专家负载计算出一个平衡的专家复制和放置方案。
需要注意的是,专家负载的具体预测方法不在此代码库的讨论范围内,一种常用的方法是使用历史统计数据的移动平均值。
3 DeepSeek Infra 中的数据分析
DeepSeek 公开分享来自训练和推理框架的性能分析数据,旨在帮助社区更深入地理解通信 - 计算重叠策略和底层实现细节。
这些分析数据是通过 PyTorch Profiler 工具获取的。

图:训练过程
训练分析数据展示了,研究人员在 DualPipe 中如何实现单对前向和后向计算块的重叠策略。每个计算块包含 4 个 MoE 层。
训练配置文件数据展示了 DeepSeek 在 DualPipe 中针对一对单独的前向和后向块的重叠策略。每个块包含 4 个 MoE(专家混合)层。
并行配置与 DeepSeek-V3 预训练设置一致:EP64、TP1 具有 4K 序列长度。
为简单起见,在分析过程中不包括流水线并行(PP)通信。
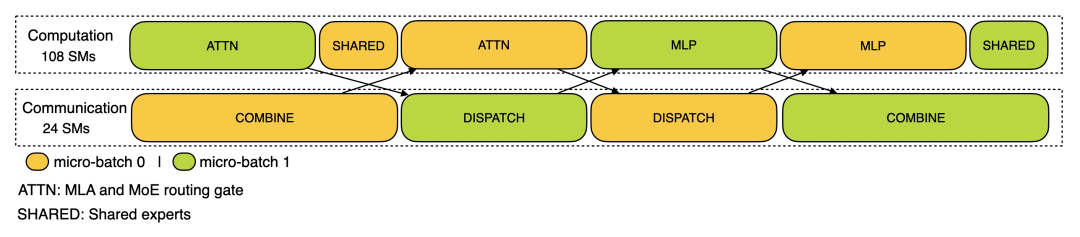
图:推理过程
在推理上,对于预填充,该配置文件采用 EP32 和 TP1(与 DeepSeek V3/R1 的实际在线部署一致),提示长度设置为 4K,每 GPU 的批大小为 16K 个 token。
在预填充阶段,DeepSeek 使用两个 micro-batch 来重叠计算和全对全(all-to-all)通信,同时确保注意力机制的计算负载在两个 micro-batch 间保持平衡 —— 这意味着同一个提示可以在它们之间拆分。
图:解码
在解码阶段,该配置文件采用 EP128、TP1 和 4K 的提示长度(与实际在线部署配置非常接近),每 GPU 批处理大小为 128 个请求。
与预填充类似,解码阶段也利用两个 micro-batch 进行重叠计算和全对全(all-to-all)通信。
但与预填充不同的是,解码过程中的全对全(all-to-all)通信不占用 GPU 流处理器(SM):发出 RDMA 消息后,所有 GPU SM 都被释放,系统等待计算完成后全对全通信完成。
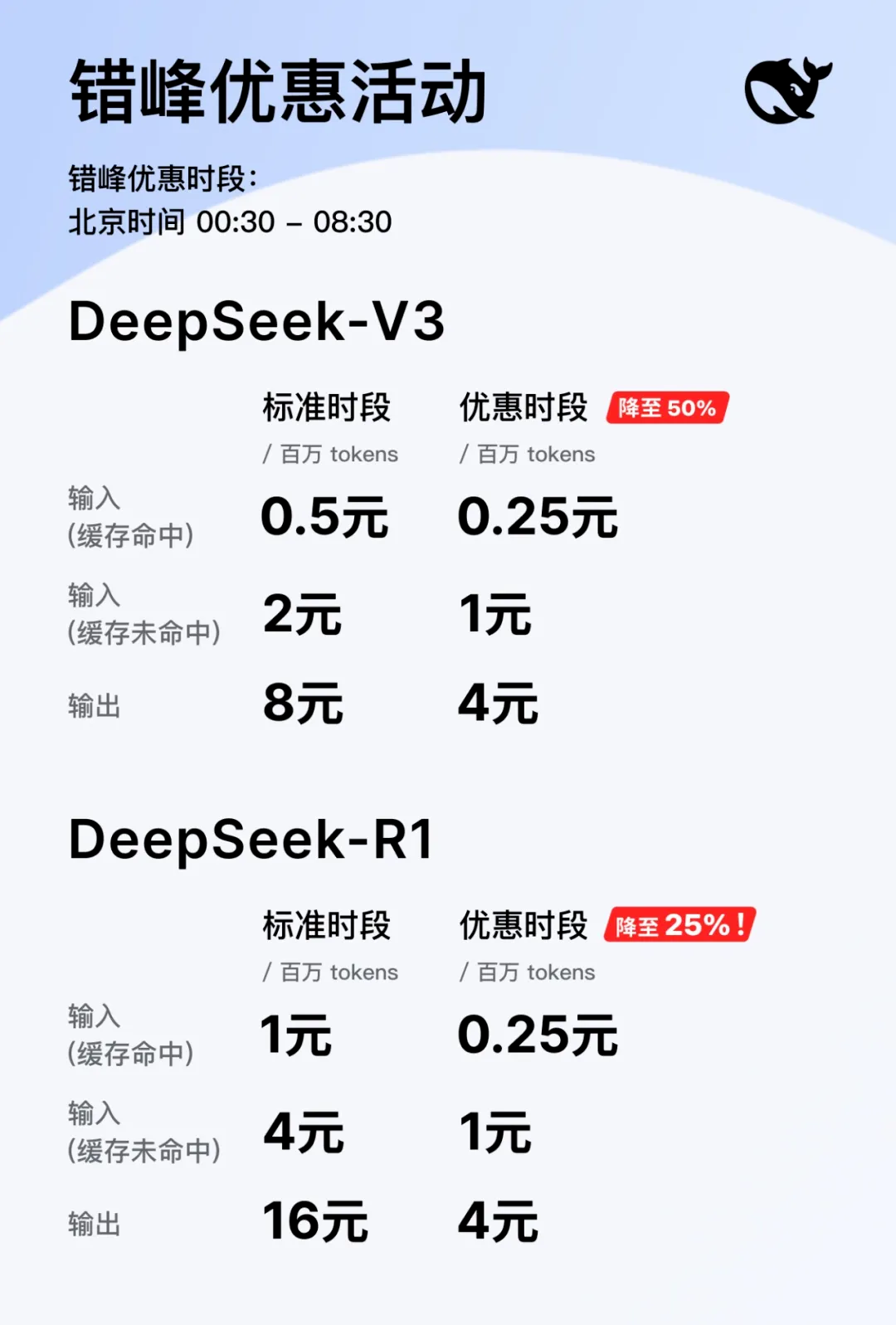
4 DeepSeek 错峰优惠,API 大降价
2月26日,DeepSeek 宣布推出错峰优惠活动。北京时间每日 00:30-08:30 为错峰时段,API 调用价格大幅下调:DeepSeek-V3 降至原价的 50%,DeepSeek-R1 降至 25%。
由于 DeepSeek 爆火,服务器资源紧张,公司一度暂停API调用,直到近期才重新开放API充值。
小伙伴们不必担心,对于在线使用的普通用户来说,DeepSeek 一直是免费的。
参考:
https://x.com/deepseek_ai/status/1894931931554558199
欢迎各位关注我的微信公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









