







ES集群相关概念:
•集群(cluster):一组拥有共同的 cluster name 的 节点。
•节点(node) :集群中的一个 Elasticearch 实例
•分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
•主分片(Primary shard):相对于副本分片的定义。
•副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
Java操作集群
只需将配置类修改为多个连接参数即可
public RestHighLevelClient clusterClient(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost(host1,port1,"http"),
new HttpHost(host2,port2,"http"),
new HttpHost(host3,port3,"http")
));
}分片与自平衡
当节点挂掉后,挂掉的节点分片会自平衡到其他节点中
注意:分片数量一旦确定好,不能修改。
索引分片推荐配置方案:
1.每个分片推荐大小10-30GB
2.分片数量推荐 = 节点数量 * 1~3倍
思考:比如有1000GB数据,应该有多少个分片?多少个节点
1.每个分片20GB 则可以分为40个分片
2.分片数量推荐 = 节点数量 * 1~3倍 --> 40/2=20 即20个节点
路由原理
Elasticsearch 是怎么知道一个文档应该存放到哪个分片中呢?
路由算法 :分片的索引 = hash(id) % 主分片的数量
脑裂现象
脑裂问题的出现就是因为从节点在选择主节点上出现分歧导致一个集群出现多个主节点从而使集群分裂,使得集群处于异常状态。
脑裂产生的原因:
1.网络原因:网络延迟
•一般es集群会在内网部署,也可能在外网部署,比如阿里云。
•内网一般不会出现此问题,外网的网络出现问题的可能性大些。
2.节点负载
•主节点的角色既为master又为data。数据访问量较大时,可能会导致Master节点停止响应(假死状态)。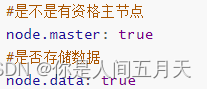
3.JVM内存回收
•当Master节点设置的JVM内存较小时,引发JVM的大规模内存回收,造成ES进程失去响应。
避免脑裂:
1.网络原因:discovery.zen.ping.timeout 超时时间配置大一点。默认是3S
2.节点负载:角色分离策略
•候选主节点配置为
•node.master: true
•node.data: false
•数据节点配置为
•node.master: false
•node.data: true
3.JVM内存回收:修改 config/jvm.options 文件的 -Xms 和 -Xmx 为服务器的内存一半。















 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









