







常用的选择排序方法有直接选择排序和堆排序。
直接选择排序(Straight Selection Sort)
1、直接选择排序的基本思想n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果:
①初始状态:无序区为R[1..n],有序区为空。
②第1趟排序
在无序区R[1..n]中选出关键字最小的记录R[k],将它与无序区的第1个记录R[1]交换,使R[1..1]和R[2..n]分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区。
……
③第i趟排序
第i趟排序开始时,当前有序区和无序区分别为R[1..i-1]和R[i..n](1≤i≤n-1)。该趟排序从当前无序区中选出关键字最小的记录R[k],将它与无序区的第1个记录R[i]交换,使R[1..i]和R[i+1..n]分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区。
这样,n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果。
2、直接选择排序的过程【参见动画演示】
3、算法描述
直接选择排序的具体算法如下:
void SelectSort(SeqList R)
{
int i,j,k;
for(i=1;i<n;i++)
{//做第i趟排序(1≤i≤n-1)
k=i;
for(j=i+1;j<=n;j++) //在当前无序区R[i..n]中选key最小的记录R[k]
if(R[j].key<R[k].key)
k=j; //k记下目前找到的最小关键字所在的位置
if(k!=i)
{ //交换R[i]和R[k]
R[0]=R[i];//R[0]作暂存单元
R[i]=R[k];
R[k]=R[0];
} //endif
} //endfor
} //SeleetSort(1)关键字比较次数(如果能利用前n-1次比较所得信息,则可以减少以后各趟选择排序中的比较次数)
无论文件初始状态如何,在第i趟排序中选出最小关键字的记录,需做n-i次比较,因此,总的比较次数为:
n(n-1)/2=0(n 2)
(2)记录的移动次数
当初始文件为正序时,移动次数为0
文件初态为反序时,每趟排序均要执行交换操作,总的移动次数取最大值3(n-1)。
直接选择排序的平均时间复杂度为O(n 2)。
(3)直接选择排序是一个就地排序
(4)稳定性分析
直接选择排序是不稳定的
【例】反例[2, 2,1]
堆排序
1、 堆(n个元素序列{k1,k2...ki...kn})
我们把堆看成一棵完全二叉树(其实就是),其任何一非叶节点满足性质:
(1)ki≤K2i且ki≤K2i+1 或(2)Ki≥K2i且ki≥K2i+1 (1≤i≤ (n/2) )
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
【例】关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1)和(2),
故它们均是堆,其对应的完全二叉树分别如小根堆示例和大根堆示例所示。

2、大根堆(序列递增)和小根堆(递减)
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小根堆。
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大根堆。
注意:
①堆中任一子树亦是堆。
②以上讨论的堆实际上是二叉堆(Binary Heap),类似地可定义k叉堆。
3、大根堆思想(小根堆请自行分析)
(1)假设现有一个R[1....n]的大根堆(无序区是R[1...n],没有有序区),根据大根堆的性质,我们知道R[1].key是最大的。
所以我们做一下操作:
① 将R[1]和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
② 由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。
③ 反复执行①② 直到无序区只有一个元素为止。
所以,我们的第一步是,将R[1....n]构造为堆。
最后,对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
注意:在任何时刻,堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到
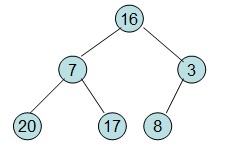



20和16交换后导致16不满足堆的性质,因此需重新调整
 这样就得到了初始堆。
这样就得到了初始堆。
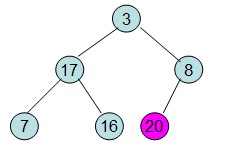 此时3位于堆顶不满堆的性质,则需调整继续调整
此时3位于堆顶不满堆的性质,则需调整继续调整








 这样整个区间便已经有序了。
这样整个区间便已经有序了。
(3)堆排序的算法:
//对R[1..n]进行堆排序,R[0]做暂存单元
void HeapSort(HeapType& R)
{
//先将R[1-n]建成初始堆
for (int i = R.length/2; i>0; i-- )
{//对每一个非子叶结点进行堆调整
HeapAdjust(R,i,R.length)
}
for(int i = R.length; i>1; i--)
{ //对当前无序区R[1..i]进行堆排序,共做n-1趟。
R[0]=R[1];//将堆顶和堆中最后一个记录交换
R[1]=R[i];
R[i]=R[0];
HeapAdjust(R,1,i-1);//将R[1..i-1]重新调整为堆,仅有R[1]可能违反堆性质
} //endfor
} //HeapSort(4)堆调整算法:
//调整堆,R是数据类型,s是要调整的结点,m是无序区的最后一位
void HeapAdjust(HeapType& R,int s,int m)
{//已知R[s..m].key中除了R[s].key之外均满足堆的定义
//所以,在初始堆的时候,要从下往上对所有非子叶结点进行堆调整
R[0]=R[s];//将R[s]先保存在R[0]上
for (int j=2*s; j<=m; j*=2)
{
if (j<m && R[j].key<R[j+1].key)
j++; //将j指向左右孩子中较大的一个
if (R[0].key > R[j].key)
break; //如果顺序正确,则结束调整
R[s]=R[j]; //如果错误,则交换位置
s = j; //然后继续调整交换过的结点
}
R[s] = R[0]; //最后,插入真确位置
}5、大根堆排序实例【 动画演示】。
6、 算法分析
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成。
堆排序的最坏时间复杂度为O(nlgn)。堆排序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1),
它是不稳定的排序方法。
部分资源摘自http://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









